


























Aricent Technologies (Holdings) Limited interview experience Real time questions & tips from candidates to crack your interview
Software Engineer
Aricent Technologies (Holdings) Limited
2 rounds | 8 Coding
problems

Rejected
Interview preparation journey

Preparation
Duration: 4 months
Topics: Data Structures, Algorithms, OS, DBMS, Networking, Aptitude, OOPS
Tip 1 : Must do Previously asked Interview as well as Online Test Questions.
Tip 2 : Go through all the previous interview experiences from Codestudio and Leetcode.
Tip 3 : Do at-least 2 good projects and you must know every bit of them.
Application process
Where: Campus
Eligibility: Above 7 CGPA
Tip 1 : Have at-least 2 good projects explained in short with all important points covered.
Tip 2 : Every skill must be mentioned.
Tip 3 : Focus on skills, projects and experiences more.

Interview rounds
01
Round
Easy
Face to Face
Duration45 minutes
Interview date28 Dec 2015
Coding problem4
Technical round with questions on Programming and core Java concepts.
1. Detect loop in a Linked List
Moderate
15m average time
80% success

0/80
Asked in companies

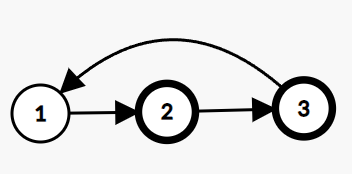
You are given a Singly Linked List of integers. Return true if it has a cycle, else return false.
A cycle occurs when a node's next points back to a previous node in the list.
Example:
In the given linked list, there is a cycle, hence we return true.
Problem approach
Floyd's algorithm can be used to solve this question.
Define two pointers slow and fast. Both point to the head node, fast is twice as fast as slow. There will be no cycle if it reaches the end. Otherwise, it will eventually catch up to the slow pointer somewhere in the cycle.
Let X be the distance from the first node to the node where the cycle begins, and let X+Y be the distance the slow pointer travels. To catch up, the fast pointer must travel 2X + 2Y. L is the cycle size. The total distance that the fast pointer has travelled over the slow pointer at the meeting point is what we call the full cycle.
X+Y+L = 2X+2Y
L=X+Y
Based on our calculation, slow pointer had already traveled one full cycle when it met fast pointer, and since it had originally travelled A before the cycle began, it had to travel A to reach the cycle's beginning!
After the two pointers meet, fast pointer can be made to point to head. And both slow and fast pointers are moved till they meet at a node. The node at which both the pointers meet is the beginning of the loop.
Pseudocode :
detectCycle(Node *head)
{
Node *slow=head,*fast=head;
while(slow!=NULL && fast!=NULL && fast->next!=NULL)
{
slow = slow->next;
fast = fast->next->next;
if(slow==fast)
{
fast = head;
while(slow!=fast)
{
slow = slow->next;
fast=fast->next;
}
return slow;
}
}
return NULL;
}2. Delete Nth node from the end of the given linked list
Moderate
15m average time
95% success
0/80
Asked in companies

You have been given a singly Linked List of 'N' nodes with integer data and an integer 'K'.
Your task is to remove the 'K'th node from the end of the given Linked List and return the head of the modified linked list.
Example:
Input : 1 -> 2 -> 3 -> 4 -> 'NULL' and 'K' = 2
Output: 1 -> 2 -> 4 -> 'NULL'
Explanation:
After removing the second node from the end, the linked list become 1 -> 2 -> 4 -> 'NULL'.
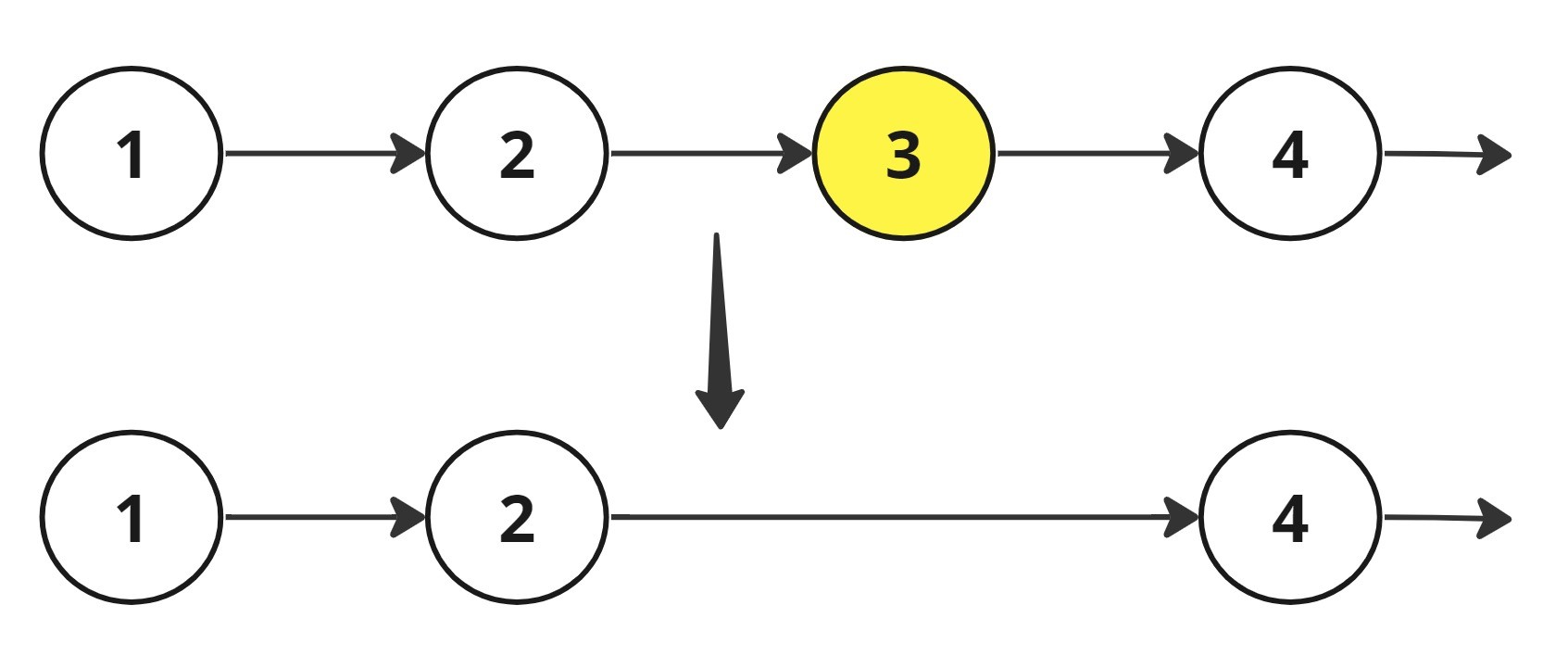
Problem approach
Intuition :
Lets K be the total nodes in the linked list.
Observation : The Nth node from the end is (K-N+1)th node from the beginning.
So the problem simplifies down to that we have to find (K-N+1)th node from the beginning.
One way of doing it is to find the length (K) of the linked list in one pass and then in the second pass move (K-N+1) step from the beginning to reach the Nth node from the end.
To do it in one pass. Let’s take the first pointer and move N step from the beginning. Now the first pointer is (K-N+1) steps away from the last node, which is the same number of steps the second pointer require to move from the beginning to reach the Nth node from the end.
Approach :
Take two pointers; the first will point to the head of the linked list and the second will point to the Nth node from the beginning.
Now keep incrementing both the pointers by one at the same time until the second is pointing to the last node of the linked list.
After the operations from the previous step, the first pointer should point to the Nth node from the end now. So, delete the node the first pointer is pointing to.
3. Java Question
What are the types of access modifiers in Java?
Problem approach
There are four types of Java access modifiers:
Private: The access level of a private modifier is only within the class. It cannot be accessed from outside the class.
Default: The access level of a default modifier is only within the package. It cannot be accessed from outside the package. If you do not specify any access level, it will be the default.
Protected: The access level of a protected modifier is within the package and outside the package through child class. If you do not make the child class, it cannot be accessed from outside the package.
Public: The access level of a public modifier is everywhere. It can be accessed from within the class, outside the class, within the package and outside the package.
4. Java Question
How are Java objects stored in memory?
Problem approach
In Java, all objects are dynamically allocated on Heap. This is different from C++ where objects can be allocated memory either on Stack or on Heap. In C++, when we allocate the object using new(), the object is allocated on Heap, otherwise on Stack if not global or static.
In Java, when we only declare a variable of a class type, only a reference is created (memory is not allocated for the object). To allocate memory to an object, we must use new(). So the object is always allocated memory on heap.
02
Round
Easy
Face to Face
Duration45 minutes
Interview date28 Dec 2015
Coding problem4
Technical round with questions on DSA mainly.
1. Time Complexity Question
What are the time complexities for each sorting algorithms?
Problem approach
| Algorithm | Best | Average | Worst |
| Selection Sort | Ω(n^2) | θ(n^2) | O(n^2) |
| Bubble Sort | Ω(n) | θ(n^2) | O(n^2) |
| Insertion Sort | Ω(n) | θ(n^2) | O(n^2) |
| Heap Sort | Ω(n log(n)) | θ(n log(n)) | O(n log(n)) |
| Quick Sort | Ω(n log(n)) | θ(n log(n)) | O(n^2) |
| Merge Sort | Ω(n log(n)) | θ(n log(n)) | O(n log(n)) |
| Bucket Sort | Ω(n+k) | θ(n+k) | O(n^2) |
| Radix Sort | Ω(nk) | θ(nk) | O(nk) |
2. Quick Sort
Moderate
10m average time
90% success
0/80
Asked in companies
You are given an array of integers. You need to sort the array in ascending order using quick sort.
Quick sort is a divide and conquer algorithm in which we choose a pivot point and partition the array into two parts i.e, left and right. The left part contains the numbers smaller than the pivot element and the right part contains the numbers larger than the pivot element. Then we recursively sort the left and right parts of the array.
Example:
Let the array = [ 4, 2, 1, 5, 3 ]
Let pivot to be the rightmost number.
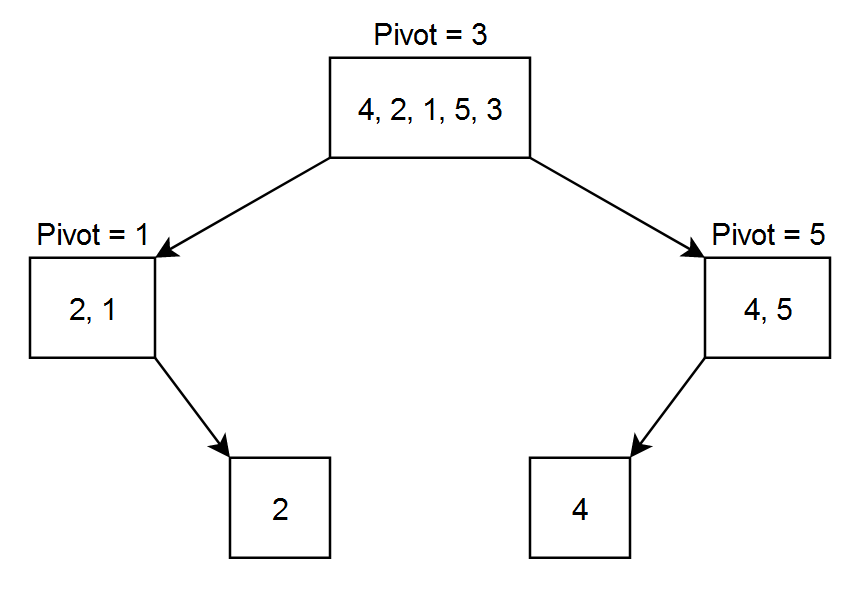
After the 1st level partitioning the array will be { 2, 1, 3, 4, 5 } as 3 was the pivot. After 2nd level partitioning the array will be { 1, 2, 3, 4, 5 } as 1 was the pivot for the left part and 5 was the pivot for the right part. Now our array is sorted and there is no need to divide it again.
Problem approach
Algorithm:
QUICKSORT (array A, start, end)
{
if (start < end)
{
p = partition(A, start, end)
QUICKSORT (A, start, p - 1)
QUICKSORT (A, p + 1, end)
}
}
Partition Algorithm :
The partition algorithm rearranges the sub-arrays in a place.
PARTITION (array A, start, end)
{
pivot = A[end]
i = start-1
for j = start to end -1
{
do if (A[j] < pivot)
{
then i = i + 1
swap A[i] with A[j]
}
}
swap A[i+1] with A[end]
return i+1
}3. Merge Sort
Easy
15m average time
85% success
0/40
Asked in companies
Given a sequence of numbers ‘ARR’. Your task is to return a sorted sequence of ‘ARR’ in non-descending order with help of the merge sort algorithm.
Example :
Merge Sort Algorithm -
Merge sort is a Divide and Conquer based Algorithm. It divides the input array into two-parts, until the size of the input array is not ‘1’. In the return part, it will merge two sorted arrays a return a whole merged sorted array.
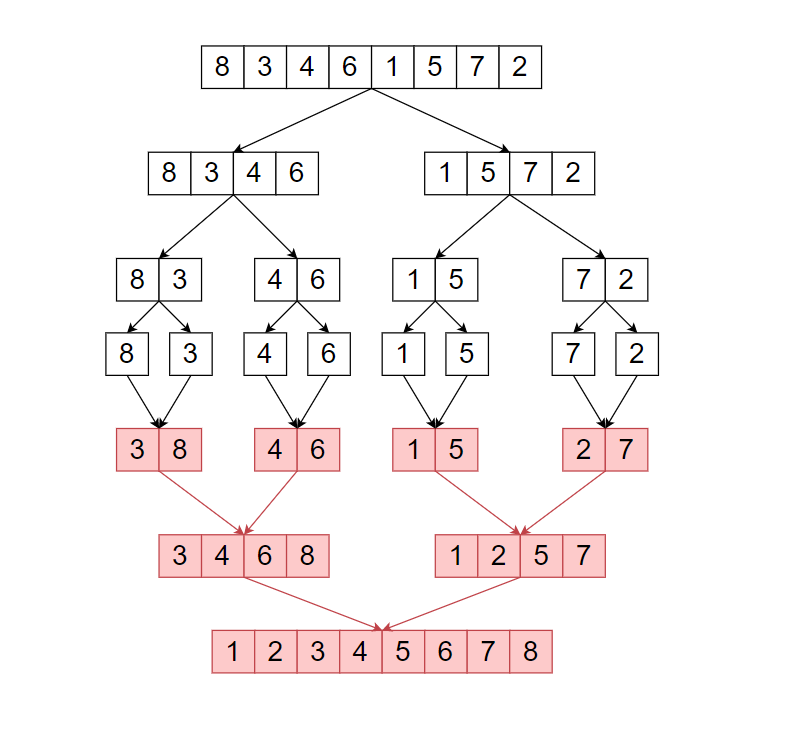
The above illustrates shows how merge sort works.
Note :
It is compulsory to use the ‘Merge Sort’ algorithm.
Problem approach
MERGE_SORT(arr, beg, end)
if beg < end
set mid = (beg + end)/2
MERGE_SORT(arr, beg, mid)
MERGE_SORT(arr, mid + 1, end)
MERGE (arr, beg, mid, end)
end of if
END MERGE_SORT4. Computer Network Question
What is serial port and parallel port?
Problem approach
1. Serial port(COM Port):
A serial port is also called a communication port and they are used for connection of external devices like a modem, mouse, or keyboard (basically in older PCs). Serial cables are cheaper to make in comparison to parallel cables and they are easier to shield from interference. There are two versions of it, which are 9 pin model and 25 pin model. It transmits data at 115 KB/sec.
2. Parallel Port (LPT ports):
Parallel ports are generally used for connecting scanners and printers. It can send several bits at the same time as it uses parallel communication. Its data transfer speed is much higher in comparison with the serial port. It is a 25 pin model. It is also known as Printer Port or Line Printer Port.


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
Which collection class forbids duplicates?
Choose another skill to practice
Similar interview experiences
Software Engineer
2 rounds | 6 problems
Interviewed by Aricent Technologies (Holdings) Limited
Rejected
896 views
0 comments
0 upvotes
Software Engineer
3 rounds | 6 problems
Interviewed by Aricent Technologies (Holdings) Limited
 Selected
Selected 971 views
0 comments
0 upvotes
Software Engineer
2 rounds | 9 problems
Interviewed by Aricent Technologies (Holdings) Limited
Selected 958 views
0 comments
0 upvotes
Software Engineer
2 rounds | 14 problems
Interviewed by Aricent Technologies (Holdings) Limited
Selected 0 views
0 comments
0 upvotes
Companies with similar interview experiences
Software Engineer
3 rounds | 7 problems
Interviewed by Optum
 Selected
Selected 8278 views
1 comments
0 upvotes
Software Engineer
5 rounds | 5 problems
Interviewed by Microsoft
 Selected
Selected 10700 views
1 comments
0 upvotes
Software Engineer
2 rounds | 4 problems
Interviewed by Amazon
Selected 4928 views
1 comments
0 upvotes