


























Capillary Technologies interview experience Real time questions & tips from candidates to crack your interview
SDE - 1
Capillary Technologies
6 rounds | 7 Coding
problems

 Selected
Selected Interview preparation journey

Preparation
Duration: 3 months
Topics: The top topics I prepared for the interview were:Data Structures (Arrays, Linked Lists, Trees, Graphs)Algorithms (Searching, Sorting, Time and Space Complexity)Object-Oriented Design and Design PatternsConcurrency and ParallelismNetworking and Distributed Systems
Tip 1 : Start with the basics: Having a strong foundation in the fundamentals of computer science is essential for any technology job. Brush up on data structures, algorithms, and programming concepts.
Tip 2 : Brush up your coding skills by solving coding challenges and exercises on platforms like HackerRank, LeetCode, and CodingNinja. This will help you to improve your problem-solving abilities and speed.
Tip 3 : Stay up-to-date with the latest technologies in your field by reading blogs, articles, and tutorials. This will help you to understand the newest trends and innovations, and to be able to discuss them in an interview.
Application process
Where: Campus
Eligibility: Above 7 CGPA, No criteria, Need two development projects on Resume
Tip 1 : Tailor your resume to the company: When applying to a product-based company, it's important to tailor your resume to show how your skills and experience align with the company's needs and values. Research the company's products and technology stack, and highlight any relevant experience you have with those technologies.
Tip 2 : Highlight your product development experience: Product-based companies are looking for candidates who have experience in product development and can bring a customer-centric mindset to the team. Make sure to highlight your past experience working on product development projects and any customer-facing experience you have. Include any metrics or data that demonstrate the impact of your work on the product and the customer satisfaction.
Tip 3 : Highlight any metrics or data that demonstrate the impact of your work on the product and the customer satisfaction. This could be things like increased user engagement, reduced development time, or improved performance.

Interview rounds
01
Round
Medium
Online Coding Interview
Duration90 minutes
Interview date1 Sep 2021
Coding problem1
Timing: around 10 am
1. Longest Increasing Subsequence
Moderate
30m average time
65% success

0/80
Asked in companies

For a given array with N elements, you need to find the length of the longest subsequence from the array such that all the elements of the subsequence are sorted in strictly increasing order.
Strictly Increasing Sequence is when each term in the sequence is larger than the preceding term.
For example:
[1, 2, 3, 4] is a strictly increasing array, while [2, 1, 4, 3] is not.
Problem approach
To solve this problem using dynamic programming, I used an array to store the longest increasing subsequence ending at each index of the input array. The length of the longest increasing subsequence ending at the current index can be determined by comparing the current value to the previous values in the array and taking the maximum value.
This problem is a classic example of dynamic programming. It has a time complexity of O(n^2) and space complexity of O(n).
02
Round
Easy
Online Coding Interview
Duration90 minutes
Interview date3 Sep 2021
Coding problem1
1 coding question was there
1. Minimum Operations
Moderate
30m average time
70% success
0/80
You are given two strings, 'S' and 'T' of lengths 'N' and 'M' respectively. You have to find the minimum number of operations required to make both strings equal.
The operations you can perform on both strings are:
1- Insert a character.
2- Replace a character with any character.
3- Delete a character.
For Example :
Consider S = 'this' and T = 'the'. The minimum operations required to make strings equal are:
1- Delete ‘s’ from the string S. Hence the string S becomes ‘thi’.
2- Replace the character ‘i’ with ‘e’ in the string S. Hence the string S becomes ‘the’.
The minimum number of operations required is 2. Hence the answer is 2.
Note:
Strings don't contain spaces in between.
Problem approach
This problem can be solved using dynamic programming by creating a 2-dimensional array to store the minimum number of operations needed to transform the first string up to the index i into the second string up to the index j. The value at each index can be determined by considering the case of a substitution, deletion, or insertion.
The time complexity for this problem is O(nm) where n is the length of string1 and m is the length of string2 and space complexity is O(nm) as well.
03
Round
Medium
Face to Face
Duration90 minutes
Interview date10 Sep 2020
Coding problem2
It was typical DSA round, two questions were asked one was of map and other one of graphs
1. Group Anagrams Together
Moderate
0/80
Asked in companies
You have been given an array/list of strings 'STR_LIST'. You are supposed to return the strings as groups of anagrams such that strings belonging to a particular group are anagrams of one another.
Note :
An Anagram is a word or phrase formed by rearranging the letters of a different word or phrase. We can generalize this in string processing by saying that an anagram of a string is another string with the same quantity of each character in it, in any order.
Example:
{ “abc”, “ged”, “dge”, “bac” }
In the above example the array should be divided into 2 groups. The first group consists of { “abc”, “bac” } and the second group consists of { “ged”, “dge” }.
Problem approach
To solve this problem, you can use a hash map to store the anagrams. The key of the map should be a string representing the sorted characters of the original string and the value should be a vector of strings that are anagrams of the key.
You iterate through the input array, for each string, sort the characters and use the sorted string as a key to check if it already exists in the map. If it does, add the original string to the corresponding value vector, if not, create a new key-value pair in the map with the sorted string as the key and a new vector containing the original string as the value.
This problem has a time complexity of O(nm log m) where n is the size of the input array and m is the length of the longest string in the input array, it's because of sorting each string, the space complexity is O(nm) where n is the size of the input array and m is the length of the longest string in the input array.
CODE:
vector> groupAnagrams(vector& strs) {
unordered_map> map;
for (string s : strs) {
string key = s;
sort(key.begin(), key.end());
map[key].push_back(s);
}
vector> res;
for (auto p : map) {
res.push_back(p.second);
}
return res;
}
it might feel like an easy problem , but believe me it wasn't , I tried to give an easier understating of the question here , but interviewer uses tricky situations to ask this question.
2. K-Closest Points
Moderate
25m average time
75% success
0/80
Asked in companies
You are given an array of points of size ‘n’. such that point[i]=[xi, yi] where 'xi' is coordinate and 'yi' is y coordinate of the 'ith' point. You need to find 'k' closest points from the origin (0,0).
The distance between two points ('x1', 'y1') and ('x2', 'y2') is given as (x1-x2)^2 +(y1-y2)^2.
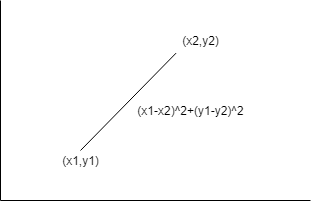
If two points have the same distance then the one with minimum 'x' coordinate will be chosen.
Problem approach
This problem can be solved using a combination of algorithms such as divide and conquer, sorting and brute force. The divide and conquer approach is more efficient as it reduces the number of points to consider, sorting is used to order the points by their x or y-coordinates and brute force is used to find the closest pair of points among the remaining points.
This problem has a time complexity of O(n*log(n)) for the best case and O(n^2) for the worst case, the space complexity is O(n)
Thankfully I have the solution with me-aswell:
import math
def closest_pair(points):
n = len(points)
if n <= 1:
return float('inf')
if n == 2:
return math.hypot(points[0][0] - points[1][0], points[0][1] - points[1][1])
mid = n // 2
left = points[:mid]
right = points[mid:]
dl = closest_pair(left)
dr = closest_pair(right)
d = min(dl, dr)
strip = [p for p in points if abs(p[0] - points[mid][0]) < d]
strip.sort(key=lambda p: p[1])
for i, p in enumerate(strip):
for j in range(i+1, min(i+7, len(strip))):
q = strip[j]
d = min(d, math.hypot(p[0] - q[0], p[1] - q[1]))
return d
04
Round
Medium
Face to Face
Duration90minutes
Interview date12 Sep 2021
Coding problem1
This was a more of theoretical round , although there were 1 coding question,But it was an easy recursive solution + binary search.
1. Technical Questions
These were some of the problems:
Explain the difference between static and dynamic binding in object-oriented programming and give an example of each.
How does a B+ tree index work in a relational database management system, and what are its advantages over a simple binary search tree index?
Explain the difference between a weak entity and a strong entity in entity-relationship modeling, and give an example of each.
Explain the concept of acid properties in database systems and how they ensure data consistency and durability.
Describe the process of normalization in database design and explain the difference between first normal form, second normal form, and third normal form.
Explain the concept of polymorphism in object-oriented programming and how it is implemented in different programming languages.
Describe the different types of joins in relational databases and explain when to use each one.
Problem approach
Tip 1:To answer the question about static and dynamic binding, you should first define the terms and explain how they differ. Static binding refers to the process of linking a method call to the corresponding method definition at compile-time, while dynamic binding refers to the process of linking a method call to the corresponding method definition at runtime. You can give an example of each, such as an example of a static method in Java and an example of a virtual method in C++.
Tip 2:: Do practice for SQL queries. (JOIN specially)
Tip 3:have a good understanding of indexing in database systems, tree structures, and the advantages and disadvantages of different types of indexes.
05
Round
Easy
Face to Face
Duration60 minutes
Interview date15 Sep 2021
Coding problem1
it was a managerial round , one manager , one side-2 were there.questions were basically related to my projects . How I implemented those , and basic questions about the system design
1. Design Question
I had one NLP based summary creator as a project , so the interviewer asked me to
Design a news aggregator platform that can extract important information from a large number of news articles and provide a summary of the most important events to users. The platform should be able to handle millions of articles per day, handle multiple languages, and provide a personalized summary of the news for each user based on their interests.
Here are some key requirements for the system:
Scalability: The platform should be able to handle millions of articles per day and provide real-time summaries to users.
Multi-Language support: The platform should be able to handle news articles in multiple languages, including English, Spanish, Chinese, etc.
NLP: The platform should use NLP techniques such as text summarization, named entity recognition, and sentiment analysis to extract important information from the articles and provide a summary of the most important events.
Personalization: The platform should provide a personalized summary of the news for each user based on their interests. Users should be able to select their preferred topics and the platform should provide summaries of the most important events in those topics.
User Interface: The platform should provide an easy-to-use interface for users to browse and read the summarized news articles.
This problem is challenging because of the high volume of data and the need for real-time processing. It also requires a good understanding of NLP techniques, distributed systems, and database design to efficiently store and retrieve the articles and user preferences.
Problem approach
Here is a possible solution for the news aggregator platform:
Scalability: To handle the high volume of data, the platform can be designed using a distributed architecture. The system can use a message queue to handle the incoming articles and distribute them to multiple worker nodes for processing. These worker nodes can process the articles in parallel, using NLP techniques to extract important information and summarize the news. The summary can then be stored in a distributed database, such as a NoSQL database like MongoDB or Cassandra, which can handle large amounts of data and provide high read and write performance.
Multi-Language support: To handle multiple languages, the platform can use language detection libraries to identify the language of the incoming articles. Once the language is detected, the appropriate NLP tools and models can be used to process the text. For example, if the article is in Spanish, the platform can use a Spanish language model for text summarization.
NLP: The platform can use NLP techniques such as text summarization, named entity recognition, and sentiment analysis to extract important information from the articles and provide a summary of the most important events. For example, the platform can use GPT-3 or BERT to extract the key phrases from the articles and use those to generate a summary.
Personalization: To provide a personalized summary of the news for each user, the platform can store user preferences in a database. When a user logs in, the platform can retrieve their preferences and use them to filter the articles and provide a summary of the most important events in their preferred topics.
User Interface: The platform can provide a web-based interface for users to browse and read the summarized news articles. The interface can be designed using a JavaScript framework, such as React or Angular, to provide a responsive and user-friendly experience. Users can search for articles by keywords, view the summary, and read the full article if they wish.
06
Round
Easy
HR Round
Duration45 minutes
Interview date2 Oct 2020
Coding problem1
It was the last round , I was interviewed by the HR ,asked some basic behavioural questions and explained me the perks of working in capillary.
1. Basic HR Questions
Can you give an example of a project you have led and the steps you took to ensure its success?
How do you handle stressful situations and tight deadlines?
How do you handle criticism and feedback?
Problem approach
Tip 1: BE CONFIDENT
Tip 2: give real-life experience if possible ,otherwise try to formulate a realistic story


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
Which collection class forbids duplicates?
Choose another skill to practice
Similar interview experiences
SDE - 1
2 rounds | 4 problems
Interviewed by Capillary Technologies
Selected 1625 views
0 comments
0 upvotes
SDE - 1
3 rounds | 7 problems
Interviewed by Capillary Technologies
Selected 797 views
0 comments
0 upvotes
SDE - 1
4 rounds | 8 problems
Interviewed by Amazon
Selected 10308 views
0 comments
0 upvotes
SDE - Intern
1 rounds | 3 problems
Interviewed by Amazon
Selected 4015 views
0 comments
0 upvotes
Companies with similar interview experiences
SDE - 1
5 rounds | 12 problems
Interviewed by Amazon
 Selected
Selected 116551 views
24 comments
0 upvotes
SDE - 1
4 rounds | 5 problems
Interviewed by Microsoft
Selected 59304 views
5 comments
0 upvotes
SDE - 1
3 rounds | 7 problems
Interviewed by Amazon
 Selected
Selected 35700 views
7 comments
0 upvotes