


























CIS - Cyber Infrastructure interview experience Real time questions & tips from candidates to crack your interview
SDE - 1
CIS - Cyber Infrastructure
3 rounds | 8 Coding
problems

 Selected
Selected Interview preparation journey

Preparation
Duration: 5 Months
Topics: Data Structures, Algorithms, DBMS, OS, Aptitude, OOPS
Tip 1 : Must do Previously asked Interview as well as Online Test Questions.
Tip 2 : Go through all the previous interview experiences from Codestudio and Leetcode.
Tip 3 : Do at-least 2 good projects and you must know every bit of them.
Application process
Where: Campus
Eligibility: Above 7 CGPA
Tip 1 : Have at-least 2 good projects explained in short with all important points covered.
Tip 2 : Every skill must be mentioned.
Tip 3 : Focus on skills, projects and experiences more.

Interview rounds
01
Round
Medium
Online Coding Test
Duration75 minutes
Interview date17 Aug 2021
Coding problem2
This was an online coding round where we had 2 questions to solve under 75 minutes. I found both the questions to be
of Medium to Hard level of difficulty.
1. Minimum Cost Path
Moderate
25m average time
70% success

0/80
Asked in companies
You have been given a matrix of ‘N’ rows and ‘M’ columns filled up with integers. Find the minimum sum that can be obtained from a path which from cell (x,y) and ends at the top left corner (1,1).
From any cell in a row, we can move to the right, down or the down right diagonal cell. So from a particular cell (row, col), we can move to the following three cells:
Down: (row+1,col)
Right: (row, col+1)
Down right diagonal: (row+1, col+1)
Problem approach
Approach (Iterative DP ) :
1) For each cell, let’s compute the answer in a top-down fashion, starting from the top leftmost cells. We create a ‘dp’ table of dimensions X*Y to store these results.
2) As we compute the results for the top leftmost cells first, when we come to cell (i, j), we already have the results for cells (i-1, j), (i, j-1) and (i-1, j-1) stored in the dp table (provided they do not violate the matrix boundaries).
3) This allows us to compute results for the current cell in O(1) time.
TC : O(X*Y), where X and Y are the coordinates of the destination cell.
SC : O(X*Y)
2. Shortest Path in a Binary Matrix
Moderate
37m average time
65% success
0/80
Asked in companies
You have been given a binary matrix of size 'N' * 'M' where each element is either 0 or 1. You are also given a source and a destination cell, both of them lie within the matrix.
Your task is to find the length of the shortest path from the source cell to the destination cell only consisting of 1s. If there is no path from source to destination cell, return -1.
Note:
1. Coordinates of the cells are given in 0-based indexing.
2. You can move in 4 directions (Up, Down, Left, Right) from a cell.
3. The length of the path is the number of 1s lying in the path.
4. The source cell is always filled with 1.
For example -
1 0 1
1 1 1
1 1 1
For the given binary matrix and source cell(0,0) and destination cell(0,2). Few valid paths consisting of only 1s are
X 0 X X 0 X
X X X X 1 X
1 1 1 X X X
The length of the shortest path is 5.
Problem approach
Approach : I solved this problem using BFS.
Breadth-First-Search considers all the paths starting from the source and moves ahead one unit in all those paths at
the same time. This makes sure that the first time when the destination is visited, it is the path with the shortest
length.
Steps :
1) Create an empty queue and enqueue source cell and mark it as visited
2) Declare a ‘STEPS’ variable, to keep track of the length of the path so far
3) Loop in level order till the queue is not empty
3.1) Fetch the front cell from the queue
3.2) If the fetched cell is the destination cell, return ‘STEPS’
3.3) Else for each of the 4 adjacent cells of the current cell, we enqueue each valid cell into the queue
and mark them visited.
3.4) Increment ‘STEPS’ by 1 when all the cells in the current level are processed.
4) If all nodes in the queue are processed and the destination cell is not reached, we return -1.
TC : O(N*M), where ‘N’ and ‘M’ are the number of rows and columns in the Binary Matrix respectively.
SC : O(N*M)
02
Round
Medium
Video Call
Duration60 Minutes
Interview date17 Aug 2021
Coding problem2
This round had 2 questions related to DSA. I was first asked to explain my approach with proper complexity analysis
and then code the soution in any IDE that I prefer.
1. Reverse Linked List
Moderate
15m average time
85% success
0/80
Asked in companies

Given a singly linked list of integers. Your task is to return the head of the reversed linked list.
For example:
The given linked list is 1 -> 2 -> 3 -> 4-> NULL. Then the reverse linked list is 4 -> 3 -> 2 -> 1 -> NULL and the head of the reversed linked list will be 4.
Follow Up :
Can you solve this problem in O(N) time and O(1) space complexity?
Problem approach
Iterative(Without using stack) :
1) Initialize three pointers prev as NULL, curr as head and next as NULL.
2) Iterate through the linked list. In loop, do following.
// Before changing next of current,
// store next node
next = curr->next
// Now change next of current
// This is where actual reversing happens
curr->next = prev
// Move prev and curr one step forward
prev = curr
curr = next
3)Finally the prev pointer contains our head , i,e. ,head=prev .
TC : O(n)
SC: O(1)
Recursive:
1) Divide the list in two parts - first node and rest of the linked list.
2) Call reverse for the rest of the linked list.
3) Link rest to first.
4) Fix head pointer
TC:O(n)
SC:O(n)
Iterative(Using Stack):
1) Store the nodes(values and address) in the stack until all the values are entered.
2) Once all entries are done, Update the Head pointer to the last location(i.e the last value).
3) Start popping the nodes(value and address) and store them in the same order until the stack is empty.
4) Update the next pointer of last Node in the stack by NULL.
TC: O(n)
SC:O(n)
2. Cycle Detection In Undirected Graph
Moderate
0/80
Asked in companies
You have been given an undirected graph with 'N' vertices and 'M' edges. The vertices are labelled from 1 to 'N'.
Your task is to find if the graph contains a cycle or not.
A path that starts from a given vertex and ends at the same vertex traversing the edges only once is called a cycle.
Example :
In the below graph, there exists a cycle between vertex 1, 2 and 3.
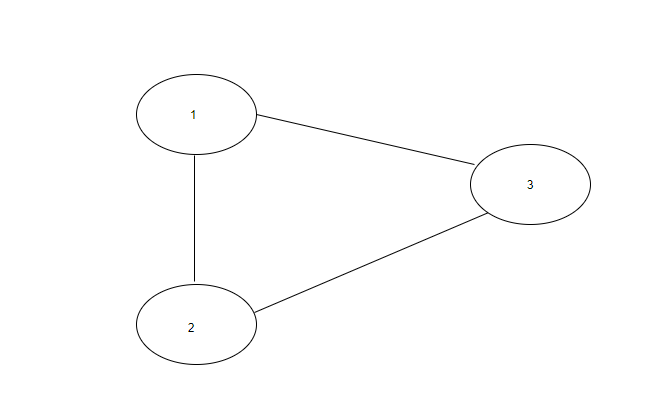
Note:
1. There are no parallel edges between two vertices.
2. There are no self-loops(an edge connecting the vertex to itself) in the graph.
3. The graph can be disconnected.
For Example :
Input: N = 3 , Edges = [[1, 2], [2, 3], [1, 3]].
Output: Yes
Explanation : There are a total of 3 vertices in the graph. There is an edge between vertex 1 and 2, vertex 2 and 3 and vertex 1 and 3. So, there exists a cycle in the graph.
Problem approach
Approach (Using Union-Find Algo) :
1) We initialise two arrays ‘PARENT’ and ‘RANK’ to keep track of the parent and rank of the subsets. Here rank
denotes the depth of the tree (subset).
2) Now we will iterate through all edges of the graph:
2.1) Find the parent of both vertices (say ‘PARENT1’ and ‘PARENT2’).
2.2) If ‘PARENT1’ == ‘PARENT2’
Return “Yes”. Here, ‘PARENT1’ == ‘PARENT2’ represents that both subsets are initially connected and now we have
another edge connecting them. Hence a cycle exists.
2.3) Else If ‘PARENT1’ != ‘PARENT2’
Union both subsets into a single set. We are doing this because we have two subsets and an edge connecting them.
Now both subsets combine and become a single subset.
3) Finally, return “No”.
TC : O(M * logN), where N is the number of vertices and M is the number of edges in the graph.
SC : O(N)
03
Round
Medium
Video Call
Duration60 minutes
Interview date17 Aug 2021
Coding problem4
This round had 2 coding questions - first one related to Dynamic Programming and the second one was from Sorting. This was followed by some questions from OOPS.
1. 0 1 Knapsack
Easy
15m average time
85% success
0/40
Asked in companies
A thief is robbing a store and can carry a maximal weight of W into his knapsack. There are N items and the ith item weighs wi and is of value vi. Considering the constraints of the maximum weight that a knapsack can carry, you have to find and return the maximum value that a thief can generate by stealing items.
Problem approach
Approach :
1) The idea is to create a 2-D array ‘result’ of size size (N + 1) * (W + 1).
2) Initially, all the elements of the ‘result’ matrix will be 0.
3) Now, the value result[i][j] denotes the maximum profit the thief can earn considering upto first 'i' items whose combined weight is less than or equal to 'j'.
4) The detailed algorithm to fill the ‘result’ matrix is as follows:
L1 : Run a loop from i = 1 to N to consider all the items.
L2 : Run a loop from j = 0 to W to consider all weights from 0 to maximum capacity W.
If the weight of the current item is more than j, we can not include it.
Thus, result[i][j] = result[i - 1][j].
Else, find the maximum profit obtained by either including the current item or excluding the current item.
i.e. result[i][j] = max(result[i - 1][j], values[i] + result[i - 1][j - weights[i]]).
5) Return result[N][W], the final profit that the thief can make.
TC : O(N*W), where N is the number of items and W is the maximum capacity of the knapsack.
SC : O(N*W)
2. Merge Intervals
Moderate
20m average time
80% success
0/80
Asked in companies

You are given N number of intervals, where each interval contains two integers denoting the start time and the end time for the interval.
The task is to merge all the overlapping intervals and return the list of merged intervals sorted by increasing order of their start time.
Two intervals [A,B] and [C,D] are said to be overlapping with each other if there is at least one integer that is covered by both of them.
For example:
For the given 5 intervals - [1, 4], [3, 5], [6, 8], [10, 12], [8, 9].
Since intervals [1, 4] and [3, 5] overlap with each other, we will merge them into a single interval as [1, 5].
Similarly, [6, 8] and [8, 9] overlap, merge them into [6,9].
Interval [10, 12] does not overlap with any interval.
Final List after merging overlapping intervals: [1, 5], [6, 9], [10, 12].
Problem approach
Approach :
1) We will first sort the intervals by non-decreasing order of their start time.
2) Then we will add the first interval to our resultant list.
3) Now, for each of the next intervals, we will check whether the current interval is overlapping with the last interval in
our resultant list.
4) If it is overlapping then we will update the finish time of the last interval in the list by the maximum of the finish time
of both overlapping intervals.
5) Otherwise, we will add the current interval to the list.
TC : O(N * log(N)), where N = number of intervals
SC : O(1)
3. OOPS Question
What are some advantages of using OOPs?
Problem approach
1) OOPs is very helpful in solving very complex level of problems.
2) Highly complex programs can be created, handled, and maintained easily using object-oriented programming.
3) OOPs, promote code reuse, thereby reducing redundancy.
4) OOPs also helps to hide the unnecessary details with the help of Data Abstraction.
5) OOPs, are based on a bottom-up approach, unlike the Structural programming paradigm, which uses a top-down
approach.
6) Polymorphism offers a lot of flexibility in OOPs.
4. OOPS Question
What are access specifiers and what is their significance?
Problem approach
Access specifiers, as the name suggests, are a special type of keywords, which are used to control or specify the
accessibility of entities like classes, methods, etc. Some of the access specifiers or access modifiers include “private”,
“public”, etc. These access specifiers also play a very vital role in achieving Encapsulation - one of the major features
of OOPs.


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
How do you remove whitespace from the start of a string?
Choose another skill to practice
Similar interview experiences
SDE - 1
3 rounds | 5 problems
Interviewed by CIS - Cyber Infrastructure
Selected 2197 views
0 comments
0 upvotes
SDE - 1
3 rounds | 4 problems
Interviewed by CIS - Cyber Infrastructure
Selected 784 views
0 comments
0 upvotes
SDE - 1
3 rounds | 3 problems
Interviewed by CIS - Cyber Infrastructure
Selected 497 views
0 comments
0 upvotes
SDE - 1
3 rounds | 3 problems
Interviewed by CIS - Cyber Infrastructure
Selected 580 views
1 comments
0 upvotes
Companies with similar interview experiences
SDE - 1
2 rounds | 3 problems
Interviewed by BNY Mellon
 Selected
Selected 6365 views
3 comments
0 upvotes
SDE - 1
3 rounds | 6 problems
Interviewed by BNY Mellon
 Selected
Selected 0 views
0 comments
0 upvotes
SDE - 1
3 rounds | 7 problems
Interviewed by BNY Mellon
Selected 0 views
0 comments
0 upvotes