


























Cisco Systems India Pvt Ltd interview experience Real time questions & tips from candidates to crack your interview
Software Engineer
Cisco Systems India Pvt Ltd
2 rounds | 6 Coding
problems

Rejected
Interview preparation journey

Journey
My interview journey with Cisco was a great learning experience. I began my preparation by building strong fundamentals in Data Structures, Algorithms, and core computer science subjects such as Operating Systems, DBMS, and Computer Networks. Along with this, I practiced coding problems regularly and worked on projects to strengthen my practical understanding. This preparation helped me get shortlisted for the interview process.
Although I was not able to clear the final stages, the experience helped me understand the level of depth expected in technical interviews and motivated me to further improve my knowledge.
Application story
I applied for the opportunity at Cisco through an off-campus hiring drive by submitting my application online via their careers portal. After applying, I received communication regarding the initial screening and assessment process. Candidates who cleared the assessment were shortlisted for the interview rounds.
The entire process was conducted online, and updates regarding each stage were shared via email. The process was smooth and well-organized throughout.
Why selected/rejected for the role?
I was able to clear the initial stages of the process at Cisco, but I was not selected in the later round. The discussion involved deeper questions on computer networking and system-level concepts, and I realized that my preparation in some advanced networking topics needed improvement. The experience helped me understand the depth of knowledge expected and motivated me to further strengthen my fundamentals.
Preparation
Duration: 15 Months
Topics: Data Structures, Algorithms, Computer Networks, Operating Systems, Object-Oriented Programming (OOP), Database Management Systems (DBMS)
Tip 1: Practice DSA problems consistently and focus on understanding the logic behind each solution rather than memorizing patterns.
Tip 2: Strengthen core subjects like Computer Networks, Operating Systems, and DBMS, as many interviews focus on fundamentals.
Tip 3: Work on a few strong projects and be prepared to explain the design, technologies used, and challenges faced.
Application process
Where: Other
Eligibility: 7+ Cpi (Salary Package: 46 LPA)
Tip 1: Highlight strong projects and internships that clearly demonstrate your technical skills and problem-solving ability.
Tip 2: Keep the resume concise and only include technologies or concepts that you can confidently explain during the interview.

Interview rounds
01
Round
Hard
Online Coding Interview
Duration90 minutes
Interview date13 Feb 2026
Coding problem3
1. Detect Cycle In A Directed Graph
Moderate
30m average time
75% success

0/80
Asked in companies
You are given a directed graph having ‘N’ nodes. A matrix ‘EDGES’ of size M x 2 is given which represents the ‘M’ edges such that there is an edge directed from node EDGES[i][0] to node EDGES[i][1].
Find whether the graph contains a cycle or not, return true if a cycle is present in the given directed graph else return false.
For Example :
In the following directed graph has a cycle i.e. B->C->E->D->B.
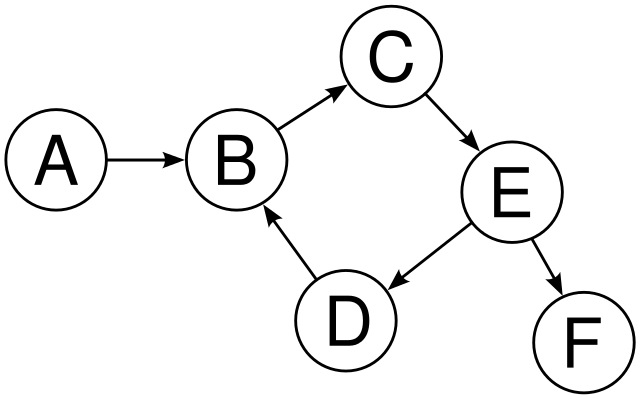
Note :
1. The cycle must contain at least two nodes.
2. It is guaranteed that the given graph has no self-loops in the graph.
3. The graph may or may not be connected.
4. Nodes are numbered from 1 to N.
5. Your solution will run on multiple test cases. If you are using global variables make sure to clear them.
Problem approach
Step 1: I first clarified the problem and understood that detecting cycles in a directed graph requires tracking the traversal path.
Step 2: Initially, I considered using a simple DFS traversal to visit all nodes in the graph.
Step 3: I maintained two arrays: one visited array to track visited nodes and another recursion stack array to track nodes currently in the DFS path.
Step 4: During the DFS traversal, if I encountered a node that was already present in the recursion stack, it indicated the presence of a cycle in the graph.
Step 5: If a neighboring node was not visited, I recursively performed DFS on that node.
Step 6: After exploring all neighbors of a node, I removed it from the recursion stack before returning.
Step 7: If any DFS call detected a cycle, I returned true; otherwise, after checking all nodes, the graph was considered acyclic.
2. Dijkstra's shortest path
Moderate
25m average time
65% success
0/80
Asked in companies

You have been given an undirected graph of ‘V’ vertices (labeled 0,1,..., V-1) and ‘E’ edges. Each edge connecting two nodes (‘X’,’Y’) will have a weight denoting the distance between node ‘X’ and node ‘Y’.
Your task is to find the shortest path distance from the source node, which is the node labeled as 0, to all vertices given in the graph.
Example:
Input:
4 5
0 1 5
0 2 8
1 2 9
1 3 2
2 3 6
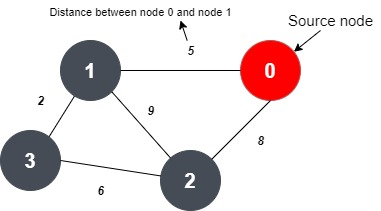
In the given input, the number of vertices is 4, and the number of edges is 5.
In the input, following the number of vertices and edges, three numbers are given. The first number denotes node ‘X’, the second number denotes node ‘Y’ and the third number denotes the distance between node ‘X’ and ‘Y’.
As per the input, there is an edge between node 0 and node 1 and the distance between them is 5.
The vertices 0 and 2 have an edge between them and the distance between them is 8.
The vertices 1 and 2 have an edge between them and the distance between them is 9.
The vertices 1 and 3 have an edge between them and the distance between them is 2.
The vertices 2 and 3 have an edge between them and the distance between them is 6.
Note:
1. There are no self-loops(an edge connecting the vertex to itself) in the given graph.
2. There can be parallel edges i.e. two vertices can be directly connected by more than 1 edge.
Problem approach
Step 1: I first clarified the requirements and understood that we need to find not just the shortest path but the K shortest distinct paths, which cannot be solved using a simple shortest path algorithm alone.
Step 2: Initially, I considered using Dijkstra’s algorithm to find the shortest path from the source to the destination.
Step 3: After finding the first shortest path, I used the idea of modifying the path by deviating at different nodes to generate alternative candidate paths.
Step 4: I maintained a priority queue (min-heap) to store candidate paths based on their total cost.
Step 5: Each time the minimum-cost path was extracted from the heap, it was added to the final answer list.
Step 6: From that path, I generated new candidate paths by changing segments of the route and pushed them back into the priority queue.
Step 7: I repeated the process until K paths were found or no more candidate paths were available.
Step 8: Finally, the algorithm returned the K shortest paths in increasing order of cost.
3. Making The Largest Island
Moderate
30m average time
70% success
0/80
Asked in companies

You are given an 'n' x 'n' binary matrix 'grid'.
You are allowed to change at most one '0' to be '1'. Your task is to find the size of the largest island in the grid after applying this operation.
Note:
An island is a 4-directionally (North, South, East, West) connected group of 1s.
Example:
Input: 'grid' = [[1,0],
[0,1]]
Output: 3
Explanation:
We can change the 0 at (0,1) to 1 and get an island of size 3.
Problem approach
Step 1: I first clarified the problem and understood that islands are groups of connected 1s, and we are allowed to convert one 0 to 1 to maximize the island size.
Step 2: I started by traversing the grid and labeling each existing island using DFS while calculating its size.
Step 3: I stored the size of each island with a unique island ID in a hash map.
Step 4: After identifying all islands, I iterated over every cell containing 0 to check the potential island size if that cell was converted to 1.
Step 5: For each 0 cell, I looked at its four neighboring cells and collected the unique island IDs connected to it.
Step 6: I summed the sizes of those unique islands and added 1 for the flipped cell to calculate the new island size.
Step 7: I kept track of the maximum possible island size obtained from all such conversions.
Step 8: Finally, I returned the maximum island size after considering all possible flips.
02
Round
Medium
Video Call
Duration60 minutes
Interview date4 Mar 2026
Coding problem3
1. Minimum Path Sum
Moderate
15m average time
85% success
0/80
Asked in companies
Ninjaland is a country in the shape of a 2-Dimensional grid 'GRID', with 'N' rows and 'M' columns. Each point in the grid has some cost associated with it.
Find a path from top left i.e. (0, 0) to the bottom right i.e. ('N' - 1, 'M' - 1) which minimizes the sum of the cost of all the numbers along the path. You need to tell the minimum sum of that path.
Note:
You can only move down or right at any point in time.
Problem approach
Step 1: I first clarified the problem constraints and realized that we need to find the shortest path in a grid while also keeping track of the number of obstacles we can eliminate.
Step 2: Since we need the shortest path, I decided to use Breadth-First Search (BFS) because it guarantees the shortest path in an unweighted grid.
Step 3: I created a queue to store the current position along with the number of obstacles eliminated so far.
Step 4: I maintained a visited structure that tracked cells along with the remaining number of obstacle eliminations to avoid revisiting inefficient states.
Step 5: During traversal, for each cell, I explored its four neighboring cells and checked whether they were inside the grid.
Step 6: If the next cell contained an obstacle, I checked whether I still had remaining eliminations available before moving into that cell.
Step 7: I pushed valid states into the queue and continued the BFS traversal level by level.
2. Operating System
Problem approach
Tip 1 : Focus on understanding process synchronization, deadlocks, and memory management concepts thoroughly.
Tip 2 : Practice explaining concepts with diagrams and real-life examples for better clarity in interviews.
Tip 3 : Revise important topics like paging, segmentation, scheduling algorithms, and concurrency problems regularly.
3. Network Monitoring
Design a distributed system that can monitor thousands of network devices such as routers, switches, and servers in real time. The system should collect metrics like CPU usage, packet loss, latency, bandwidth utilization, and device status, and generate alerts when abnormal behavior is detected.
Problem approach
Tip 1: Start by defining functional and non-functional requirements like scalability, latency, and reliability.
Tip 2: Design a high-level architecture including collectors, load balancers, message queues (like Kafka), processing services, and time-series databases.
Tip 3: Discuss optimizations such as data aggregation, caching, distributed storage, and fault-tolerant services to handle large-scale network monitoring.


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
Which collection class forbids duplicates?
Choose another skill to practice
Similar interview experiences
SDE - 1
3 rounds | 7 problems
Interviewed by OYO
 Selected
Selected 5572 views
0 comments
0 upvotes
SDE - Intern
2 rounds | 3 problems
Interviewed by Amazon
Rejected
1332 views
0 comments
0 upvotes
SDE - 1
2 rounds | 5 problems
Interviewed by Meesho
Rejected
6978 views
0 comments
0 upvotes
SDE - 1
3 rounds | 9 problems
Interviewed by Salesforce
 Selected
Selected 4114 views
0 comments
0 upvotes
Companies with similar interview experiences
Software Engineer
3 rounds | 7 problems
Interviewed by Optum
 Selected
Selected 8278 views
1 comments
0 upvotes
Software Engineer
5 rounds | 5 problems
Interviewed by Microsoft
 Selected
Selected 10700 views
1 comments
0 upvotes
Software Engineer
2 rounds | 4 problems
Interviewed by Amazon
Selected 4928 views
1 comments
0 upvotes