


























Flipkart limited interview experience Real time questions & tips from candidates to crack your interview
SDE - 1
Flipkart limited
3 rounds | 7 Coding
problems

 Selected
Selected Interview preparation journey

Preparation
Duration: 4 Months
Topics: Data Structures, Algorithms, System Design, Aptitude, OOPS
Tip 1 : Must do Previously asked Interview as well as Online Test Questions.
Tip 2 : Go through all the previous interview experiences from Codestudio and Leetcode.
Tip 3 : Do at-least 2 good projects and you must know every bit of them.
Application process
Where: Campus
Eligibility: Above 7 CGPA
Tip 1 : Have at-least 2 good projects explained in short with all important points covered.
Tip 2 : Every skill must be mentioned.
Tip 3 : Focus on skills, projects and experiences more.

Interview rounds
01
Round
Medium
Video Call
Duration60 Minutes
Interview date10 Jul 2019
Coding problem2
The round was held on Google Meet and I was given 2 coding problems for which first I had to explain my approach and then I had to write code in Shared Google Docs and dry run on sample test cases and discuss Time and Space Complexity.
1. Validate BST
Moderate
25m average time
70% success

0/80
Asked in companies
Given a binary tree with N number of nodes, check if that input tree is Partial BST (Binary Search Tree) or not. If yes, return true, return false otherwise.
A binary search tree (BST) is said to be a Partial BST if it follows the following properties.
• The left subtree of a node contains only nodes with data less than and equal to the node’s data.
• The right subtree of a node contains only nodes with data greater than and equal to the node’s data.
• Both the left and right subtrees must also be partial binary search trees.
Example:
Input:
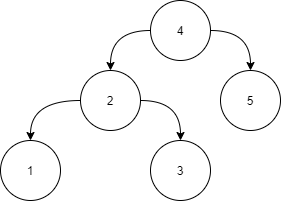
Answer:
Level 1:
All the nodes in the left subtree of 4 (2, 1, 3) are smaller
than 4, all the nodes in the right subtree of the 4 (5) are
larger than 4.
Level 2 :
For node 2:
All the nodes in the left subtree of 2 (1) are smaller than
2, all the nodes in the right subtree of the 2 (3) are larger than 2.
For node 5:
The left and right subtree for node 5 is empty.
Level 3:
For node 1:
The left and right subtree for node 1 are empty.
For node 3:
The left and right subtree for node 3 are empty.
Because all the nodes follow the property of a Partial binary
search tree, the above tree is a Partial binary search tree.
Problem approach
Approach 1 (Recursive Inorder Traversal) :
We know that the inorder traversal of a BST always gives us a sorted array , so if we maintain two variable Tree Nodes "previous" and "current" , we should always have previous->val < current->value for a valid BST.
Steps :
1) Create a boolean recursive function with two parameters (root and prev) which will return true if our binary tree is a BST or else it will return false.
2) If root is not null , call the recursive function with parameters (root->left,prev) and check if it return true or not.
3) For the prev node , check if at any point prev->val >= root->val if this condition is met , simply return false.
4) Update prev with root.
5) Call the recursive function again with parameters (root->right , prev)
TC : O(N) where N=number of nodes in the binary tree
SC : O(N)
//Pseudo Code :
bool isValidBST2(TreeNode* root , TreeNode*&prev)
{
//Using inorder traversal
if(root)
{
if(!isValidBST2(root->left,prev))
return false;
if(prev and prev->val >= root->val)
return false;
prev=root;
return isValidBST2(root->right,prev);
}
return true;
}
bool isValidBST(TreeNode*root)
{
TreeNode*prev=NULL;
return isValidBST2(root,prev);
}
Approach 2 (Iterative Inorder Traversal) :
We can also perfom an iterative inorder traversal of the Binary Tree using a stack and check the same condition that we checked above i.e., at any point if prev->value >= current->value if this is met then simply return false.
Steps :
1) Take a stack of TreeNodes and a TreeNode prev with its initial value as NULL.
2) Run a loop till stack is not empty or root != NULL.
3) While pushing a root to the stack, push all its left descendants into the stack untill root != NULL.
4) Take current = stack.top() and pop it from the stack
5) Check if prev is NOT NULL and if prev->val >= curr->val , if this cond. is met simply return false.
6) Update prev with current.
7) Update root with root->right.
TC : O(N) where N=number of nodes in the binary tree
SC : O(N)
//Pseudo Code :
bool isValidBST(TreeNode* root)
{
stackst;
TreeNode*prev=NULL;
while(!st.empty() || root!=NULL)
{
while(root!=NULL)
{
st.push(root);
root=root->left;
}
root=st.top();
st.pop();
if(prev and prev->val>=root->val)
return false;
prev=root;
root=root->right;
}
return true;
}
2. Maximum sum path from the leaf to root
Easy
10m average time
90% success
0/40
Asked in companies
You are given a binary tree of 'N' nodes.
Your task is to find the path from the leaf node to the root node which has the maximum path sum among all the root to leaf paths.
For Example:
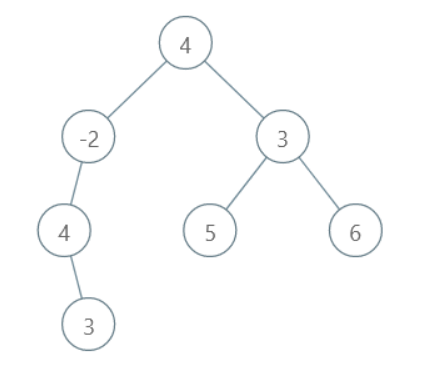
All the possible root to leaf paths are:
3, 4, -2, 4 with sum 9
5, 3, 4 with sum 12
6, 3, 4 with sum 13
Here, the maximum sum is 13. Thus, the output path will be 6, 3, 4.
Note:
There will be only 1 path with max sum.
Problem approach
Approach :
The approach is as follows:
1) Get the max sum path for the left subtree.
2) Get the max sum path for the right subtree.
3) Select the one with the max sum from both and insert current node's data into it.
4) Return the updated path.
Algorithm:
list ‘MAXPATHSUM’('ROOT'):
1) If the root is NULL: return empty list.
2) Initialize ‘LEFTPATH’ = ‘MAXPATHSUM’('ROOT'->left).
3) Initialize ‘LEFTPATH’ = ‘MAXPATHSUM’('ROOT'->right).
4) Append 'ROOT' -> data to both the lists.
5) Find the sum of both lists.
6) Return the list with the greater sum.
TC : O(N+H^2), where ‘N’ is the number of nodes in the Binary tree and ‘H’ is the height of the binary tree.
SC : O(N)
02
Round
Medium
Video Call
Duration60 Minutes
Interview date10 Jul 2019
Coding problem3
This was also a Data Structures and Algorithms round where I was asked to solve 2 coding problems explaining my approach with proper Complexity Analysis . After the coding questions were over there was some time left so the interviewer asked me some concepts related to DBMS.
1. Next Permutation
Moderate
15m average time
85% success
0/80
Asked in companies

You have been given a permutation of ‘N’ integers. A sequence of ‘N’ integers is called a permutation if it contains all integers from 1 to ‘N’ exactly once. Your task is to rearrange the numbers and generate the lexicographically next greater permutation.
To determine which of the two permutations is lexicographically smaller, we compare their first elements of both permutations. If they are equal — compare the second, and so on. If we have two permutations X and Y, then X is lexicographically smaller if X[i] < Y[i], where ‘i’ is the first index in which the permutations X and Y differ.
For example, [2, 1, 3, 4] is lexicographically smaller than [2, 1, 4, 3].
Problem approach
Approach 1 (Naive/Brute Force Soln) :
1) Find out every possible permutation of list formed by the elements of the given array and find out the permutation which is just larger than the given one.
2) This one will be a very naive approach, since it requires us to find out every possible permutation which will take really long time and the implementation is complex.
TC : O(N!) since total permutations possible for an array consisting of N distinct elements = N!
SC : O(N)
Approach 2 (Efficient Approach ) :
1) Find the first pair of two successive numbers a[i] and a[i-1] , from the right, which satisfy a[i] > a[i−1].
2) Rearrange the numbers to the right of a[i-1] including itself.
3) Replace the number a[i-1] with the number which is just larger than itself among the numbers lying to its right section, say a[j].
4) Swap the numbers a[i-1] and a[j] .
5) Reverse the numbers following a[i-1] to get the next smallest lexicographic permutation.
TC : O(N)
SC : O(1)
2. Largest BST subtree
Easy
10m average time
90% success
0/40
Asked in companies

You have been given a Binary Tree of 'N' nodes, where the nodes have integer values. Your task is to return the size of the largest subtree of the binary tree which is also a BST.
A binary search tree (BST) is a binary tree data structure which has the following properties.
• The left subtree of a node contains only nodes with data less than the node’s data.
• The right subtree of a node contains only nodes with data greater than the node’s data.
• Both the left and right subtrees must also be binary search trees.
Example:
Given binary tree:
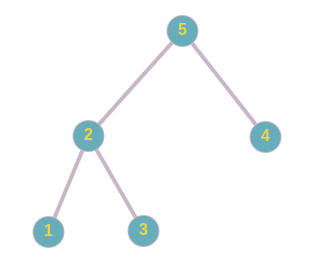
In the given binary tree, subtree rooted at 2 is a BST and its size is 3.
Problem approach
Approach 1 (Brute Force) :
We can make every node of the binary tree as the root node BST and check whether it is a BST or not.
Steps :
1) Start from the root of the binary tree and do the inorder traversal using recursion.
2) For the current node ‘ROOT', do the following-
2.1) If it is the root of a valid BST, return its size.
2.2) Else, find the largest BST in left and right subtrees.
TC : O(N^2), where ‘N’ denotes the number of nodes in the binary tree.
SC : O(N)
Approach 2 (Bottom-up Traversal of BST) :
The key observation here is that if a subtree is a BST then all nodes in its subtree will also be a BST. So, we will recurse on the binary tree in a bottom-up manner and use the information of the left subtree and right subtree to store the information for the current subtree.
Algorithm :
1) We will keep a variable named ‘MAX_BST’ denoting our answer.
2) For each node of the binary tree, we will store the following information-
2.1) ‘IS_VALID’, denoting whether it is a BST
2.2) ‘SIZE’, denoting the size of the subtree
2.3) ‘MIN’, denoting the minimum value of data in the left subtree
2.4) 'MAX', denoting the maximum value of data in the right subtree
3) For the current node 'CURR_NODE' we will do the following--(steps 3-8)
For the subtree to be a BST following conditions should be satisfied-
3.1) 'CURR_NODE' -> data > max value in left subtree
3.2) 'CURR_NODE' -> data < minimum value in right subtree
3.3) 'CURR_NODE' -> left must be a BST.
3.4) 'CURR_NODE' -> right must be a BST.
4) If the current subtree is a BST, we will update 'CURR_NODE' as-
4.1) Set ‘IS_VALID’ to true.
4.2) Set ‘MAX_BST’ to max( ‘SUB_BST’, ‘SIZE’ ).
5) Else, we do the following
5.1) Set ‘IS_VALID’ to false.
6) Set size to ‘SIZE’ of left subtree + ‘SIZE’ of right subtree + 1
7) Set ‘MAX’ to maximum data value among 'CURR_NODE', left subtree and right subtree.
8) Set ‘MIN’ to minimum data value among 'CURR_NODE', left subtree and right subtree.
TC : O(N), where ‘N’ denotes the number of nodes in the binary tree.
SC : O(N)
3. DBMS Question
Explain Indexing in Databases.
Problem approach
Answer :
Indexing : Indexing is a way to optimize the performance of a database by minimizing the number of disk accesses required when a query is processed. It is a data structure technique which is used to quickly locate and access the data in a database.
Index Structure : Indexes can be created using some database columns.
1) The first column of the database is the search key that contains a copy of the primary key or candidate key of the table. The values of the primary key are stored in sorted order so that the corresponding data can be accessed easily.
2) The second column of the database is the data reference. It contains a set of pointers holding the address of the disk block where the value of the particular key can be found.
Indexing Methods :
There are primarily three methods of indexing:
1) Clustered Indexing
2) Non-Clustered or Secondary Indexing
3) Multilevel Indexing
1) Clustered Indexing :
When more than two records are stored in the same file these types of storing known as cluster indexing. By using the cluster indexing we can reduce the cost of searching reason being multiple records related to the same thing are stored at one place and it also gives the frequent joining of more than two tables (records).
1.1) Primary Indexing : This is a type of Clustered Indexing wherein the data is sorted according to the
search key and the primary key of the database table is used to create the index. It is a default format of
indexing where it induces sequential file organization.
2) Non-clustered or Secondary Indexing :
A non clustered index just tells us where the data lies, i.e. it gives us a list of virtual pointers or references to the location where the data is actually stored. Data is not physically stored in the order of the index. Instead, data is present in leaf nodes.
3) Multilevel Indexing :
With the growth of the size of the database, indices also grow. As the index is stored in the main memory, a single-level index might become too large a size to store with multiple disk accesses. The multilevel indexing segregates the main block into various smaller blocks so that the same can stored in a single block.
03
Round
Medium
Video Call
Duration50 Minutes
Interview date10 Jul 2019
Coding problem2
This round also had 2 questions related to DS and Algo . One was from graphs and the other was an implementation of a LRU Cache . There were 2 interviewers and both of them were quite friendly and helpful. Overall, this round went well.
1. Detect Cycle In A Directed Graph
Moderate
30m average time
75% success
0/80
Asked in companies
You are given a directed graph having ‘N’ nodes. A matrix ‘EDGES’ of size M x 2 is given which represents the ‘M’ edges such that there is an edge directed from node EDGES[i][0] to node EDGES[i][1].
Find whether the graph contains a cycle or not, return true if a cycle is present in the given directed graph else return false.
For Example :
In the following directed graph has a cycle i.e. B->C->E->D->B.
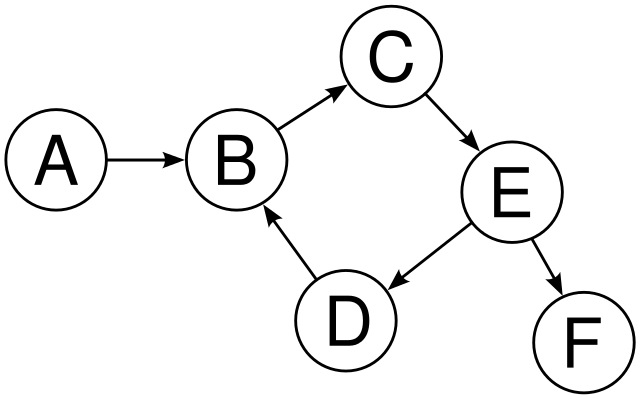
Note :
1. The cycle must contain at least two nodes.
2. It is guaranteed that the given graph has no self-loops in the graph.
3. The graph may or may not be connected.
4. Nodes are numbered from 1 to N.
5. Your solution will run on multiple test cases. If you are using global variables make sure to clear them.
Problem approach
Approach 1 (DFS) :
1) We need to create a recursive function that uses the current node, visited, and recursion stack.
2) Firstly mark the current node as visited and also mark the current node into the recursion stack.
3) Now track all the nodes which are not visited and are adjacent to the current node.
4) Then recursively call the function for those nodes, If the recursive function returns true then return true.
5) And if the adjacent nodes are already visited in the recursion stack then return true.
6) For the whole approach, create a wrapper function that calls the recursive function for all the vertices, and if any instance function returns true then return true as the answer.
7) Else, if for all vertices the function returns false then return false as the answer.
TC : O(N+M), where ‘N’ is the number of nodes and ‘M’ is the number of edges.
SC : O(N)
Approach 2 (BFS) :
1) First of all, we need to calculate the number of incoming edges for each of the nodes present in the graph.
2) Take an in-degree array which will keep track of traverse the array of edges and simply increase the counter of the destination node by 1.
3) At the start initialize the count of visited nodes as 0.
4) Pick all the nodes with in-degree i.e. number of incoming edges as 0 and add them into the queue.
5) Remove a node from the queue and then. Now increment count of visited nodes by 1 and decrement in-degree (number of incoming nodes) by 1 for all its neighboring nodes. And if the in-degree of a neighboring node is reduced to zero, then add it to the queue.
6) Keep on repeating step 5 until the queue is empty.
7) If the count of visited nodes is not equal to the number of nodes in the graph, then there exists a cycle in the graph, otherwise not.
TC : O(N+M), where ‘N’ is the number of nodes and ‘M’ is the number of edges.
SC : O(N)
2. LRU Cache Implementation
Moderate
25m average time
65% success
0/80
Asked in companies
Design and implement a data structure for Least Recently Used (LRU) cache to support the following operations:
1. get(key) - Return the value of the key if the key exists in the cache, otherwise return -1.
2. put(key, value), Insert the value in the cache if the key is not already present or update the value of the given key if the key is already present. When the cache reaches its capacity, it should invalidate the least recently used item before inserting the new item.
You will be given ‘Q’ queries. Each query will belong to one of these two types:
Type 0: for get(key) operation.
Type 1: for put(key, value) operation.
Note :
1. The cache is initialized with a capacity (the maximum number of unique keys it can hold at a time).
2. Access to an item or key is defined as a get or a put operation on the key. The least recently used key is the one with the oldest access time.
Problem approach
Structure of an LRU Cache :
1) In practice, LRU cache is a kind of Queue — if an element is reaccessed, it goes to the end of the eviction order
2) This queue will have a specific capacity as the cache has a limited size. Whenever a new element is brought in, it is added at the head of the queue. When eviction happens, it happens from the tail of the queue.
3) Hitting data in the cache must be done in constant time, which isn't possible in Queue! But, it is possible with HashMap data structure
4) Removal of the least recently used element must be done in constant time, which means for the implementation of Queue, we'll use DoublyLinkedList instead of SingleLinkedList or an array.
LRU Algorithm :
The LRU algorithm is pretty easy! If the key is present in HashMap, it's a cache hit; else, it's a cache miss.
We'll follow two steps after a cache miss occurs:
1) Add a new element in front of the list.
2) Add a new entry in HashMap and refer to the head of the list.
And, we'll do two steps after a cache hit:
1) Remove the hit element and add it in front of the list.
2) Update HashMap with a new reference to the front of the list.
Tip : This is a very frequently asked question in interview and its implementation also gets quite cumbersome if you are doing it for the first time so better knock this question off before your SDE-interviews.


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
How do you remove whitespace from the start of a string?
Choose another skill to practice
Similar interview experiences
SDE - 1
3 rounds | 10 problems
Interviewed by Flipkart limited
Selected 2634 views
0 comments
0 upvotes
SDE - 1
3 rounds | 3 problems
Interviewed by Flipkart limited
Selected 1906 views
0 comments
0 upvotes
SDE - 1
3 rounds | 3 problems
Interviewed by Flipkart limited
 Selected
Selected 1718 views
0 comments
0 upvotes
SDE - 1
3 rounds | 4 problems
Interviewed by Flipkart limited
Selected 2197 views
0 comments
0 upvotes
Companies with similar interview experiences
SDE - 1
5 rounds | 12 problems
Interviewed by Amazon
 Selected
Selected 115096 views
24 comments
0 upvotes
SDE - 1
4 rounds | 5 problems
Interviewed by Microsoft
Selected 58237 views
5 comments
0 upvotes
SDE - 1
3 rounds | 7 problems
Interviewed by Amazon
 Selected
Selected 35146 views
7 comments
0 upvotes