


























Infosys private limited interview experience Real time questions & tips from candidates to crack your interview
System Engineer
Infosys private limited
4 rounds | 11 Coding
problems

 Selected
Selected Interview preparation journey

Preparation
Duration: 4 Months
Topics: Data Structures, Algorithms, System Design, Aptitude, OOPS
Tip 1 : Must do Previously asked Interview as well as Online Test Questions.
Tip 2 : Go through all the previous interview experiences from Codestudio and Leetcode.
Tip 3 : Do at-least 2 good projects and you must know every bit of them.
Application process
Where: Campus
Eligibility: Above 7 CGPA
Tip 1 : Have at-least 2 good projects explained in short with all important points covered.
Tip 2 : Every skill must be mentioned.
Tip 3 : Focus on skills, projects and experiences more.
Interview rounds
01
Round
Medium
Online Coding Interview
Duration120 Minutes
Interview date17 Nov 2021
Coding problem2
This was an online MCQ + coding round where we had 1 hour to solve the MCQ's and another 1 hour to solve 2 coding
questions. The MCQ's were related to both General and Technical Aptitude and the coding questions were relatively
easy if one has a decent grip on Data Structures and Algorithms.
1. Generate all parenthesis
Moderate
30m average time
85% success

0/80
Asked in companies

You are given an integer 'N', your task is to generate all combinations of well-formed parenthesis having ‘N’ pairs.
A parenthesis is called well-formed if it is balanced i.e. each left parenthesis has a matching right parenthesis and the matched pairs are well nested.
For Example:
For ‘N’ = 3,
All possible combinations are:
((()))
(()())
(())()
()(())
()()()
Problem approach
Approach :
generate function:
It will take a number of arguments:
‘TOTAL’ - an integer representing the total number of characters i.e twice the number of pairs.
‘OPEN’ - an integer representing the number of opening brackets till now.
‘CLOSE’ - an integer representing the number of closing brackets till now.
‘S’ - a string representing the parenthesis till now.
‘ANS’ - a vector of string to store all the generated parenthesis.
1) If the size of the string becomes equal to ‘TOTAL’’, that means that a valid parenthesis is generated, we will store it in the ‘ANS’ vector.
2) If ‘OPEN’ is greater than ‘CLOSE’,
2.1) Then we can give a closing bracket at this index.
2.2) Again if ‘OPEN’ is less than ‘TOTAL’ / 2, we can also give an opening bracket at this index.
3) Else we can only give an opening bracket at this index.
given function :
1) Declare a variable ‘TOTAL’ with a value twice as ‘N’, since each pair consists of two characters.
2) Declare a vector of strings ‘ANS’ to store all the valid parentheses.
3) Call the generate function with zero opening bracket, zero closing bracket, and an empty string.
4) Finally, return the ‘ANS’ vector.
TC : O(2 ^ N), where N is the total number of characters.
SC : O(1)
2. Compress the String
Moderate
25m average time
60% success
0/80
Asked in companies

Ninja has been given a program to do basic string compression. For a character that is consecutively repeated more than once, he needs to replace the consecutive duplicate occurrences with the count of repetitions.
Example:
If a string has 'x' repeated 5 times, replace this "xxxxx" with "x5".
The string is compressed only when the repeated character count is more than 1.
Note :
The consecutive count of every character in the input string is less than or equal to 9.
Problem approach
Approach :
1) Keep two indices, both starting from the initial character. Let’s say, ‘STARTINDEX’ and ‘ENDINDEX’. These indices are going to tell the start and end of the substring where the characters are the same.
2) Start moving the ‘ENDINDEX’ to every character till the character at ‘STARTINDEX’ is a match.
3) Whenever there is a mismatch, we can calculate the frequency of the character at the ‘STARTINDEX’ by subtracting the ‘STARTINDEX’ from ‘ENDINDEX’.
4) Append the character at the ‘STARTINDEX’ with its total frequency and add it to the final string you want to return. If the frequency of the character is 1, no need to append its frequency.
5) Move the ‘STARTINDEX' to ‘ENDINDEX’.
6) Repeat until all the characters are traversed in this manner.
TC : O(N), where N = length of the string
SC : O(1)
02
Round
Medium
Video Call
Duration60 Minutes
Interview date17 Nov 2021
Coding problem4
The interviewer asked me 1 coding problem in this round where I was expected to first explain my approach with proper complexity analysis and then code the solution. After that, some more questions related to DBMS and OOPS were also asked in this round.
1. Pair Sum
Easy
15m average time
90% success
0/40
Asked in companies

You are given an integer array 'ARR' of size 'N' and an integer 'S'. Your task is to return the list of all pairs of elements such that each sum of elements of each pair equals 'S'.
Note:
Each pair should be sorted i.e the first value should be less than or equals to the second value.
Return the list of pairs sorted in non-decreasing order of their first value. In case if two pairs have the same first value, the pair with a smaller second value should come first.
Problem approach
Approach :
1) Initialize a list to store our results.
2) For each element in the array ‘ARR[i]’, we will check whether there exists an element equals to ('S' - ‘ARR[i]’) already in the map.
3) If it exists we will add the pair('ARR[i]', ‘S’ - ‘ARR[i]’ ) ‘COUNT’ number of times to the list, where ‘COUNT’ represents the frequency of ('S' - ‘ARR[i]’) in the map.
4) Also, we will increment the frequency of the current element ('ARR[i]') in the map. Sort the list of pairs as per the given output format and return this list.
TC : O(N^2), where N = size of the array
SC : O(N)
2. DBMS Question
Explain the difference between the DELETE and TRUNCATE command in a DBMS.
Problem approach
DELETE command : This command is needed to delete rows from a table based on the condition provided by the WHERE clause.
1) It deletes only the rows which are specified by the WHERE clause.
2) It can be rolled back if required.
3) It maintains a log to lock the row of the table before deleting it and hence it’s slow.
TRUNCATE command : This command is needed to remove complete data from a table in a database. It is like a DELETE command which has no WHERE clause.
1) It removes complete data from a table in a database.
2) It can be rolled back even if required. (Truncate can be rolled back in some databases depending on their version but it can be tricky and can lead to data loss).
3) It doesn’t maintain a log and deletes the whole table at once and hence it’s fast.
3. DBMS Question
Explain different languages present in DBMS.
Problem approach
Following are various languages present in DBMS:
1) DDL(Data Definition Language): It contains commands which are required to define the database.
E.g., CREATE, ALTER, DROP, TRUNCATE, RENAME, etc.
2) DML(Data Manipulation Language): It contains commands which are required to manipulate the data present in the database.
E.g., SELECT, UPDATE, INSERT, DELETE, etc.
3) DCL(Data Control Language): It contains commands which are required to deal with the user permissions and controls of the database system.
E.g., GRANT and REVOKE.
4) TCL(Transaction Control Language): It contains commands which are required to deal with the transaction of the database.
E.g., COMMIT, ROLLBACK, and SAVEPOINT.
4. OOPS Question
What is Early Binding and Late Binding in C++ ?
Problem approach
OOP is used commonly for software development. One major pillar of OOP is polymorphism. Early Binding and Late
Binding are related to that. Early Binding occurs at compile time while Late Binding occurs at runtime. In method
overloading, the bonding happens using the early binding. In method overriding, the bonding happens using the late
binding. The difference between Early and Late Binding is that Early Binding uses the class information to resolve
method calling while Late Binding uses the object to resolve method calling.
Early Binding : In Early Binding, the class information is used to resolve method calling. Early Binding occurs at
compile time. It is also known as the static binding. In this process, the binding occurs before the program actually
runs. Overloading methods are bonded using early binding.
Late Binding : In Late Binding, the object is used to resolve method calling. Late Binding occurs at runtime. It is also
known as dynamic binding. In this process, the binding occurs at program execution. Overridden methods are
bonded using late binding.
03
Round
Medium
Video Call
Duration60 Minutes
Interview date17 Nov 2021
Coding problem4
This round had 1 Algorithmic question wherein I was supposed to code the problem after discussing their approaches and respective time and space complexities . After that , I was grilled on some OOPS concepts related to C++.
1. Quick Sort
Moderate
10m average time
90% success
0/80
Asked in companies


You are given an array of integers. You need to sort the array in ascending order using quick sort.
Quick sort is a divide and conquer algorithm in which we choose a pivot point and partition the array into two parts i.e, left and right. The left part contains the numbers smaller than the pivot element and the right part contains the numbers larger than the pivot element. Then we recursively sort the left and right parts of the array.
Example:
Let the array = [ 4, 2, 1, 5, 3 ]
Let pivot to be the rightmost number.
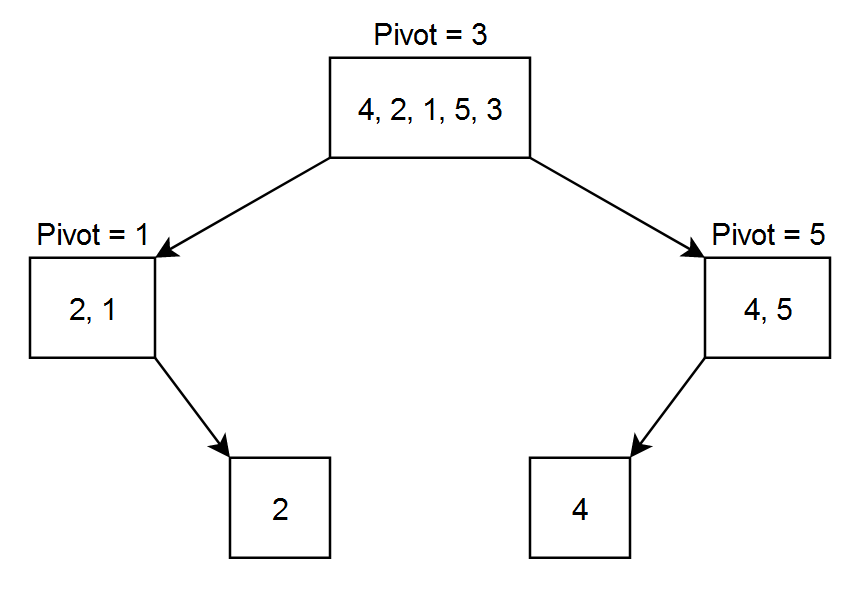
After the 1st level partitioning the array will be { 2, 1, 3, 4, 5 } as 3 was the pivot. After 2nd level partitioning the array will be { 1, 2, 3, 4, 5 } as 1 was the pivot for the left part and 5 was the pivot for the right part. Now our array is sorted and there is no need to divide it again.
Problem approach
Approach :
1) Select any splitting value, say L. The splitting value is also known as Pivot.
2) Divide the stack of papers into two. A-L and M-Z. It is not necessary that the piles should be equal.
3) Repeat the above two steps with the A-L pile, splitting it into its significant two halves. And M-Z pile, split into its
halves. The process is repeated until the piles are small enough to be sorted easily.
4) Ultimately, the smaller piles can be placed one on top of the other to produce a fully sorted and ordered set of
papers.
5) The approach used here is reduction at each split to get to the single-element array.
6) At every split, the pile was divided and then the same approach was used for the smaller piles by using the method
of recursion.
Technically, quick sort follows the below steps:
Step 1 − Make any element as pivot
Step 2 − Partition the array on the basis of pivot
Step 3 − Apply quick sort on left partition recursively
Step 4 − Apply quick sort on right partition recursively
//Pseudo Code :
quickSort(arr[], low, high)
{
if (low < high)
{
pivot_index = partition(arr, low, high);
quickSort(arr, low, pivot_index - 1); // Before pivot_index
quickSort(arr, pivot_index + 1, high); // After pivot_index
}
}
partition (arr[], low, high)
{
// pivot - Element at right most position
pivot = arr[high];
i = (low - 1);
for (j = low; j <= high-1; j++)
{
if (arr[j] < pivot)
{
i++;
swap(arr[i], arr[j]);
}
}
swap(arr[i + 1], arr[high]);
return (i + 1);
}
Complexity Analysis :
TC : Best Case - O(N*log(N))
Worst Case - O(N^2)
SC : Average Case - O(log(N))
Worst Case - O(N)
2. OOPS Question
Explain the difference b/w Dangling Pointer and Void Pointer
Problem approach
Dangling Pointer :
1) A dangling pointer is a pointer that occurs at the time when the object is de-allocated from memory without modifying the value of the pointer.
2) It points to the deleted object.
3) It usually occurs at the object destruction time.
4) Dangling pointer errors can only be avoided just by initializing the pointer to one NULL value.
5) The dangling pointer will be with a free() function in C.
Void Pointer :
1) A void pointer is a pointer that can point to any data type.
2) A void pointer can be assigned the address of any data type.
3) The representation of a pointer to the void is the same as the pointer of the character type.
4) A void pointer can store an object of any type.
5) It is also called a general-purpose pointer.
3. C++ Question
Difference b/w Call by Value and Call by Reference in C++
Problem approach
Call by Value : In this parameter passing method, values of actual parameters are copied to function’s formal parameters and the two types of parameters are stored in different memory locations. So any changes made inside functions are not reflected in actual parameters of the caller.
//Pseudo Code :
void change(int x)
{
x=x+10;
cout<<"Value of x in the function = "< Change not reflected
Call by Reference : Here both the actual and formal parameters refer to the same locations, so any changes made inside the function are actually reflected in actual parameters of the caller.
//Pseudo Code :
void change(int &x)
{
x=x+10;
cout<<"Value of x in the function = "< Change reflected
4. C++ Question
What is Diamond Problem in C++ and how do we fix it?
Problem approach
The Diamond Problem : The Diamond Problem occurs when a child class inherits from two parent classes who both
share a common grandparent class i.e., when two superclasses of a class have a common base class.
Solving the Diamond Problem in C++ : The solution to the diamond problem is to use the virtual keyword. We make
the two parent classes (who inherit from the same grandparent class) into virtual classes in order to avoid two copies
of the grandparent class in the child class.
04
Round
Easy
HR Round
Duration30 Minutes
Interview date17 Nov 2021
Coding problem1
This was about 30 minutes long interview. First, she asked introduction, after that she was very interested in my internship that I did in summer and about my interests. She asked few common questions on that. Then we discussed about my role.
1. Basic HR Questions
What are your hobbies? or What are you passionate about?
What are your biggest achievements till date?
What are you most proud of?
Why do you want to work at Infosys?
Problem approach
Tip 1 : Be Confident
Tip 2 : Prepare your resume throughout
Tip 3 : Projects play so important role in your candidature


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
To make an AI less repetitive in a long paragraph, you should increase:
Choose another skill to practice
Similar interview experiences
System Engineer
4 rounds | 13 problems
Interviewed by Infosys private limited
Selected 1198 views
0 comments
0 upvotes
System Engineer
3 rounds | 3 problems
Interviewed by Infosys private limited
Selected 2677 views
0 comments
0 upvotes
System Engineer
2 rounds | 3 problems
Interviewed by Infosys private limited
Selected 0 views
0 comments
0 upvotes
System Engineer
2 rounds | 5 problems
Interviewed by Infosys private limited
Selected 1084 views
0 comments
0 upvotes
Companies with similar interview experiences
System Engineer
2 rounds | 2 problems
Interviewed by Cognizant
Selected 4965 views
5 comments
0 upvotes
System Engineer
3 rounds | 3 problems
Interviewed by Tata Consultancy Services (TCS)
 Selected
Selected 2463 views
0 comments
0 upvotes
System Engineer
2 rounds | 1 problems
Interviewed by Tata Consultancy Services (TCS)
Selected 2038 views
0 comments
0 upvotes