


























Media.net interview experience Real time questions & tips from candidates to crack your interview
SDE - 1
Media.net
4 rounds | 6 Coding
problems

 Selected
Selected Interview preparation journey

Preparation
Duration: 6 months
Topics: Data Structures and Algorithms, Operating System, Database Management System, Computer Networking, Object-Oriented Programming System
Tip 1 : Practice as much as you can. But focus on quality of problems rather than quantity. Doing competitive programming will help you for the sure.
Tip 2 : Understand the concept well and practice problems on them. Try as many approach you can for a problem and compare them on the basis of complexities.
Tip 3 : While learning the theory subject try to to find simple relatable examples for explaining.
Application process
Where: Referral
Tip 1 : Keep your resume short (one page) and crisp and do mention your achievements for sure.
Tip 2 : Don't put any false skills on your resume.

Interview rounds
01
Round
Hard
Online Coding Interview
Duration90 minutes
Interview date28 Sep 2021
Coding problem2
It was an online coding round. I received the test link 10 mins prior to the test. The test was around 7 in the evening.
1. Longest Substring with At Most K Distinct Characters
Moderate
20m average time
80% success

0/80
Asked in companies

You are given a string 'str' and an integer ‘K’. Your task is to find the length of the largest substring with at most ‘K’ distinct characters.
For example:
You are given ‘str’ = ‘abbbbbbc’ and ‘K’ = 2, then the substrings that can be formed are [‘abbbbbb’, ‘bbbbbbc’]. Hence the answer is 7.
Problem approach
count amount of such substrings of t that are bigger than corresponding substring of s and begin at the position i.
1.If t[i] < s[i], this amount equals 0.
2.If t[i] > s[i], this amount equals n - i.
3.If t[i] = s[i], then let's find such nearest position j, j > i , that t[j] ≠ s[j]. If t[j] > s[j], needed amount of substrings will be n - j. If t[j] < s[j], needed amount of substrings will be 0.
We can rephrase this: If t[i] > s[i], it will be (1 + pref)·(n - i) new substrings, where pref means how many last elements in s and t is equal.
Let's make dp. dp[i][sum] means that we viewed i positions, have sum needed substrings and s[i] ≠ t[i]. Lets iterate their common prefix pref.
If t[i] < s[i], dp[i][sum] + = dp[i - pref - 1][sum]·(s[i] - 'a') — we can count this value using partial sums.
If t[i] > s[i], dp[i][sum] + = dp[i - pref - 1][sum - (1 + pref)·(n - i)]·('z' - s[i]). Let's iterate pref.
Let's note that sum - pref·(n - i) ≥ 0, so pref ≤ sum / (n - i) and pref ≤ k / (n - i). This means that third cycle will make at most k / (n - i) iterations when we find value of dp[i][sum]. Let's count total number of iterations:
= < k·(n + k·log k).
2. Minimum XOR
Easy
0/40
Asked in companies

Ninja is learning the bitwise operations to score well in his class test. He found an interesting question on bitwise XOR. The problem statement is as follows:
An array ‘ARR’ consists of ‘N’ numbers. The task is to find pair having the minimum XOR value.No, need to print the values of the element. Just print the minimum XOR value. Can you help Ninja to solve this problem?
For Example
If the array ‘ARR’ is [13,5,11,1], the answer will be 4, corresponding to the XOR value of 1 and 5.
Problem approach
Build up the tree, then with dfs at any step you could get all ancestor: push it to stack then pop if you processed x, but this could be too slow when the tree is a path (there are n ancestor in the worst case). How to find the max value for e ^ node ? Since you are doing the xor bit by bit we can find the max value also bit by bit, start from the largest possible power of two then you need to know for a given val2=e^node value only if you shift right the e ^ val2 by d then was it in the root-x path shifted by d ?
[notice that node=e^val2 because val2=e^node]
Use a segmented tree to decide this in O(1), hence you can process each query in O(log(n)) time. [sort also the queries to know what you should answer for x].
02
Round
Medium
Online Coding Test
Duration60 minutes
Interview date16 Nov 2022
Coding problem2
The round was in the afternoon. The interview started with a little introduction. Then he asked me some theory questions from OOPs and DBMS. Then the interviewer gave me an algorithm problem. I tell him all my approaches when he was satisfied with my approach then he asked me to write the code. I have to write the code in a Google Doc.
The interviewer was quite friendly and made me comfortable before the interview.
1. Trie Implementation
Moderate
25m average time
65% success
0/80
Asked in companies
Implement a Trie Data Structure which supports the following three operations:
Operation 1 - insert(word) - To insert a string WORD in the Trie.
Operation 2- search(word) - To check if a string WORD is present in Trie or not.
Operation 3- startsWith(word) - To check if there is a string that has the prefix WORD.
Trie is a data structure that is like a tree data structure in its organisation. It consists of nodes that store letters or alphabets of words, which can be added, retrieved, and deleted from the trie in a very efficient way.
In other words, Trie is an information retrieval data structure, which can beat naive data structures like Hashmap, Tree, etc in the time complexities of its operations.
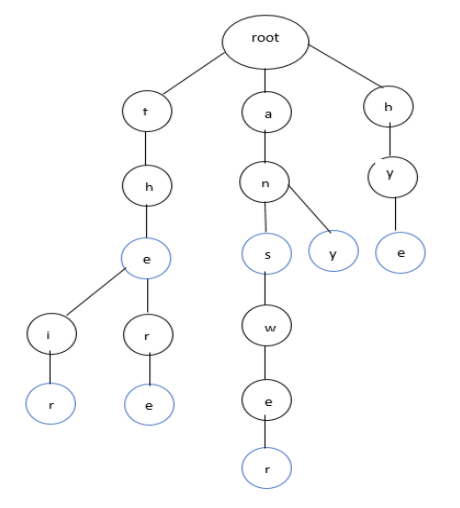
The above figure is the representation of a Trie. New words that are added are inserted as the children of the root node.
Alphabets are added in the top to bottom fashion in parent to children hierarchy. Alphabets that are highlighted with blue circles are the end nodes that mark the ending of a word in the Trie.
For Example:-
Type = ["insert", "search"], Query = ["coding", "coding].
We return ["null", "true"] as coding is present in the trie after 1st operation.
Problem approach
As there were only four strings hence the number of cases was not much. So i first found the common prefix from all the strings and took them as one node. After that I tried every permutation possible between the strings and find the minimum number of node.
2. Theory Questions
What is indexing and Why it is used?
03
Round
Medium
Online Coding Test
Duration60 minutes
Interview date22 Nov 2021
Coding problem1
The round was in the evening. The interview started with a little introduction. The interviewer gave me an algorithm problem. I tell him all my approaches when he was satisfied with my approach then he asked me to write the code. I have to write the code in a google Doc. After that he asked some problem based on OS and CN.
The interviewers was very friendly and made me comfortable before the interview.He also talked about the company and how i can work on my weak points.
1. Find the minimum cost to reach destination using a train
Moderate
20m average time
80% success
0/80
Asked in companies


There are ‘N’ stations on the route of a train. The train goes from station 0 to ‘N’ - 1. The ticket cost for all pairs of stations (i, j) is given where ‘j’ is greater than ‘i’. Your task is to find the minimum cost to reach the Nth station.
Note:
Cost of entries where j < i will be represented as INT_MAX VALUE which is 10000 in the price matrix.
Example:
If ‘N’ = 3
'PRICE[3][3]' = {{0, 15, 80,},
{INF, 0, 40},
{INF, INF, 0}};
First, go from 1st station to 2nd at 15 costs, then go from 2nd to 3rd at 40. 15 + 40 = 55 is the total cost.It is cheaper than going directly from station 1 to station 3 as it would have cost 80.
The output will be 55.
Problem approach
This can be done with Dijkstra:
lets say our dijkstra state is {daysPassed, timeTravelled, vertexId}
initial state is {0,0,startCity} we add it to priority queue (sorted as tuples, min first)
For each state in queue:
try going to all neighboring cities (if timeTravelled + edgeWeigth <= maxTravelTimePerDay), state changes to {daysPassed, timeTravelled + edgeWeight, neighbourId}
try to sleep in current city (if it has a hotel), state changes to {daysPassed + 1, 0, vertexId}
Of course its not profitable to sleep in same hotel 2 times so we can additionally keep a boolean array indicating whether we slept in some hotel and only try to sleep in hotel once (on first time visiting vertex)
if any time during algorithm we reach goal city daysPassed from state is the answer
04
Round
Hard
Online Coding Test
Duration60 minutes
Interview date18 Dec 2021
Coding problem1
The round was in the evening. The interview started with a little introduction. The interviewer gave me an algorithm problem. I tell him all my approaches. Then he discussed the complexities of all the approaches. And discussed some test cases too. He did not ask me to write the code. After that, he asked about some problems based on my projects. He also asked me some real-life scenario questions related to the session and cookie. He asked me to write SQL queries too.
The interviewer was friendly and made me comfortable before the interview. He also talked about the company.
1. Alien dictionary
Hard
46m average time
50% success
0/120
Asked in companies

You have been given a sorted (lexical order) dictionary of an alien language.
Write a function that returns the order of characters as a string in the alien language. This dictionary will be given to you as an array of strings called 'dictionary', of size 'N'.
Example :
If the dictionary consists of the following words:-
["caa", "aaa", "aab"], and 'K' is 3.
Then, the order of the alphabet is -
['c', 'a', 'b']
Note:
If the language consists of four letters, the four letters should be the starting four letters of the English language.
However, their order might differ in the alien language.
Problem approach
First of all i gave the naive approach to try all the words that can be formed using the number string and then checking which word is present in the dictionary.
Then i give the reverse approach -> load the dict, then translate each dictionary word character-by-character into its keypad representation.The input number then just need to be directly matched against these number, and return all matching dict words.
After that he asked me to optimise it further. Then. i give the approach using trie in which is each node is linked to a hash map, which contains the value of the key which can used to generate the letter.


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
How do you remove whitespace from the start of a string?
Choose another skill to practice
Similar interview experiences
SDE - 1
3 rounds | 6 problems
Interviewed by Media.net
 Selected
Selected 4659 views
1 comments
0 upvotes
SDE - 1
3 rounds | 4 problems
Interviewed by Media.net

Rejected
2262 views
0 comments
0 upvotes
SDE - 1
2 rounds | 2 problems
Interviewed by Media.net
Selected 1301 views
0 comments
0 upvotes
SDE - 1
4 rounds | 8 problems
Interviewed by Media.net
Selected 1442 views
0 comments
0 upvotes
Companies with similar interview experiences
SDE - 1
5 rounds | 12 problems
Interviewed by Amazon
 Selected
Selected 115097 views
24 comments
0 upvotes
SDE - 1
4 rounds | 5 problems
Interviewed by Microsoft
Selected 58237 views
5 comments
0 upvotes
SDE - 1
3 rounds | 7 problems
Interviewed by Amazon
 Selected
Selected 35147 views
7 comments
0 upvotes