


























Oracle interview experience Real time questions & tips from candidates to crack your interview
Application Developer
Oracle
4 rounds | 12 Coding
problems

 Selected
Selected Interview preparation journey

Preparation
Duration: 4 Months
Topics: Data Structures, Algorithms, System Design, Aptitude, DBMS, OOPS
Tip 1 : Must do Previously asked Interview as well as Online Test Questions.
Tip 2 : Go through all the previous interview experiences from Codestudio and Leetcode.
Tip 3 : Do at-least 2 good projects and you must know every bit of them.
Application process
Where: Campus
Eligibility: Above 7 CGPA
Tip 1 : Have at-least 2 good projects explained in short with all important points covered.
Tip 2 : Every skill must be mentioned.
Tip 3 : Focus on skills, projects and experiences more.

Interview rounds
01
Round
Medium
Online Coding Test
Duration60 Minutes
Interview date22 Aug 2019
Coding problem2
This was a proctured online coding test where we had 2 questions to solve under 60 minutes. Both the questions were of Easy to Medium level of difficulty and can be solved if one has a decent command over Data Structures and Algorithms.
1. Partition Equal Subset Sum
Moderate
25m average time
65% success

0/80
Asked in companies
You are given an array 'ARR' of 'N' positive integers. Your task is to find if we can partition the given array into two subsets such that the sum of elements in both subsets is equal.
For example, let’s say the given array is [2, 3, 3, 3, 4, 5], then the array can be partitioned as [2, 3, 5], and [3, 3, 4] with equal sum 10.
Follow Up:
Can you solve this using not more than O(S) extra space, where S is the sum of all elements of the given array?
Problem approach
Approach :
1) Find the 'SUM' of all elements of array say 'TOTALSUM'.
2) If 'TOTALSUM' is not divisible by 2 return false, as array cant be partitioned into two equal subsets.
3) Create a new auxiliary array 'DP' of length 'N' * 'TOTALSUM' / 2.
4) Iterate the given array, now for each index 'I' we run a loop from 0 to 'TOTALSUM' / 2 then at each index 'J' we have two choices:
4.1) Exclude the number. In this case, we will see if we can get 'J' from the subset excluding this number: 'DP'[i-1]['J']
4.2) Include the number if its value is not more than 'J'. In this case, we will see if we can find a subset to get the remaining 'SUM': 'DP'['I' - 1]['J' - 'NUMS'['I']]
5) If either of the two above choices is true then we can find a subset of numbers with 'SUM' 'J'.
6) At last, return 'DP'['N']['TOTALSUM' / 2].
TC : O(N * S), where ‘N’ is the size of the array, and ‘S’ is the sum of all elements in the given array.
SC : O(N * S)
2. Count Subsequences
Moderate
30m average time
60% success
0/80
Asked in companies

You have been given an integer array/list 'ARR' of size 'N'. Your task is to return the total number of those subsequences of the array in which all the elements are equal.
A subsequence of a given array is an array generated by deleting some elements of the given array with the order of elements in the subsequence remaining the same as the order of elements in the array.
Note :
As this value might be large, print it modulo 10^9 + 7
Problem approach
Approach :
1) Store the frequency of each element in a hashmap (say, ‘FREQ’).
2) Maintain a variable ‘RESULT’ which stores the final answer.
3) For each element present in the hashmap,
3.1) Calculate the value of (2^eleCount - 1) % MOD, ‘eleCount’ is frequency of current element.
3.2) Add the above value to ‘RESULT’
4) The final answer is the value of ‘RESULT’ after we are done iterating over all the elements of the hashmap.
TC : O(N), where N=size of the array
SC : O(N)
02
Round
Medium
Face to Face
Duration60 Minutes
Interview date23 Aug 2019
Coding problem4
This round had 2 questions from DSA of Easy to Medium level in which I first had to explain my approach and then I had to code . After that, I was asked some questions from DBMS and SQL to check basic understanding of the subject.
1. Merge K Sorted Arrays
Moderate
15m average time
85% success
0/80
Asked in companies
You have been given ‘K’ different arrays/lists, which are sorted individually (in ascending order). You need to merge all the given arrays/list such that the output array/list should be sorted in ascending order.
Problem approach
Approach (Using Min Heap) :
1) Create an output array ‘ANS’.
2) Create a min-heap of size K and insert the first element of all the arrays, along with its indices, into the heap.
3) The heap is ordered by the element of the array/list.
4) While the min-heap is not empty, we will keep doing the following operations :
4.1) Remove the minimum element from the min-heap (the minimum element is always at the root) and store it in the output array.
4.2) Insert the next element from the array for which the current element is extracted. If the array doesn’t have any more elements i.e. if the index of the above-removed component is equal to ‘LENGTH-1’ of the array from which the element is extracted, then do nothing.
5) After the above process, 'ANS' will contain all the elements of ‘K’ arrays in ascending order.
6) Return the output array i.e. ‘ANS’.
TC : O((N * K) * log(K)), where ‘K’ is the number of arrays and ‘N’ is the average number of elements in every array.
SC : O(N*K)
2. Construct Tree From Preorder Traversal
Moderate
10m average time
90% success
0/80
Asked in companies
Given an array ‘pre[]’ of ‘n’ elements that represent Preorder traversal of a spacial binary tree where every node has either 0 or 2 children. Also Given a boolean array ‘isLeaf’ such that isLeaf[i] represents if the ‘i-th’ node in the ‘pre’ array is a leaf node or not. Write a function to construct the tree from the given two arrays and return the head node of the constructed binary tree.
For example let pre={1,2,4,5,3,6,7}
isLeaf={0,0,1,1,0,1,1}
Here 0 means that the node is not a leaf node and 1 means that the node is a leaf node.
Then we will have the following tree
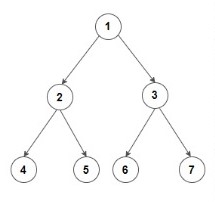
Problem approach
Approach :
1) We will maintain ‘MIN_VAL’ and ‘MAX_VAL’ (initialized to minimum and maximum possible value, respectively) to set a range for every node.
2) We will also maintain ‘PRE_ORDER_INDEX’to keep track of the index in the ‘PRE_ORDER_INDEX’ array.
3) We initialize ‘CURR_VAL’ to ‘PREORDER’[‘PRE_ORDER_INDEX’].
3.1) If ‘CURR_VAL’ doesn’t fall in the range [‘MIN_VAL’: ‘MAX_VAL’ ], we return NULL.
3.2) Else, we construct ‘NODE’ initialized to ‘CURR_VAL’ and increment ‘PRE_ORDER_INDEX’.
4) We will then set the range for the left subtree ([‘MIN_VAL’ : ‘CURR_VAL’ + ‘1’) and the right subtree (['CURR_VAL' +1 : ‘MAX_VAL’]) and recursively construct them.
TC : O(N), where N=number of nodes in the BST
SC : O(N)
3. DBMS Question
Explain the difference between the DELETE and TRUNCATE command in a DBMS.
Problem approach
DELETE command : This command is needed to delete rows from a table based on the condition provided by the WHERE clause.
1) It deletes only the rows which are specified by the WHERE clause.
2) It can be rolled back if required.
3) It maintains a log to lock the row of the table before deleting it and hence it’s slow.
TRUNCATE command : this command is needed to remove complete data from a table in a database. It is like a DELETE command which has no WHERE clause.
1) It removes complete data from a table in a database.
2) It can be rolled back even if required. ( truncate can be rolled back in some databases depending on their version but it can be tricky and can lead to data loss).
3) It doesn’t maintain a log and deletes the whole table at once and hence it’s fast.
4. DBMS Question
What are Constraints in SQL?
Problem approach
Constraints are used to specify the rules concerning data in the table. It can be applied for single or multiple fields in an SQL table during the creation of the table or after creating using the ALTER TABLE command. The constraints are :
1) NOT NULL - Restricts NULL value from being inserted into a column.
2) CHECK - Verifies that all values in a field satisfy a condition.
3) DEFAULT - Automatically assigns a default value if no value has been specified for the field.
4) UNIQUE - Ensures unique values to be inserted into the field.
5) INDEX - Indexes a field providing faster retrieval of records.
6) PRIMARY KEY - Uniquely identifies each record in a table.
7) FOREIGN KEY - Ensures referential integrity for a record in another table.
03
Round
Medium
Face to Face
Duration60 Minutes
Interview date23 Aug 2019
Coding problem4
This round also had 2 questions from DS and Algo where I had to first explain my approach and then write the pseudo code in Google Docs. This was followed by some questions from DBMS and SQL . I was also asked to execute a SQL query at the end.
1. Search In A Row Wise And Column Wise Sorted Matrix
Moderate
15m average time
80% success
0/80
Asked in companies
You are given an 'N * N' matrix of integers where each row and each column is sorted in increasing order. You are given a target integer 'X'.
Find the position of 'X' in the matrix. If it exists then return the pair {i, j} where 'i' represents the row and 'j' represents the column of the array, otherwise return {-1,-1}
For example:
If the given matrix is:
[ [1, 2, 5],
[3, 4, 9],
[6, 7, 10]]
We have to find the position of 4. We will return {1,1} since A[1][1] = 4.
Problem approach
Approach :
1) Start your search from the top-right corner of the matrix.
2) There can be three cases:
2.1) The current element is equal to target: return this position
2.2) The current element is greater than the target: This means that any element on the current column is also greater, thus we move to the previous column
2.3) The current element is smaller than the target: This means that any element on the current row is also smaller, thus we move to the next row
3) If we go out of the matrix, it means element is not found. So, return {-1, -1}.
TC : O(N), where N=number of rows or columns in the matrix
SC : O(1)
2. Valid Parentheses
Easy
10m average time
80% success
0/40
Asked in companies
You're given a string 'S' consisting of "{", "}", "(", ")", "[" and "]" .
Return true if the given string 'S' is balanced, else return false.
For example:
'S' = "{}()".
There is always an opening brace before a closing brace i.e. '{' before '}', '(' before ').
So the 'S' is Balanced.
Problem approach
Approach :
1) Declare a character stack.
2) Now traverse the expression string
2.1) If the current character is a starting bracket ( ‘(‘ or ‘{‘ or ‘[‘ ) then push it to stack .
2.2) If the current character is a closing bracket ( ‘)’ or ‘}’ or ‘]’ ) then pop from stack and if the popped
character is the matching starting bracket then fine else parenthesis are not balanced.
3) After complete traversal, if there is some starting bracket left in the stack then “not balanced”.
4) Otherwise, the string is balanced.
TC : O(N), where N=length of the string
SC : O(N)
3. DBMS Question
Given an Employee Table, find the Nth highest salary from it.
Problem approach
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
DECLARE M INT;
SET M=N-1;
RETURN (
SELECT DISTINCT Salary FROM Employee ORDER BY Salary DESC LIMIT M, 1
);
END
4. DBMS Question
What is the difference between Clustered and Non-clustered index?
Problem approach
1) Clustered index modifies the way records are stored in a database based on the indexed column. A non-clustered index creates a separate entity within the table which references the original table.
2) Clustered index is used for easy and speedy retrieval of data from the database, whereas, fetching records from the non-clustered index is relatively slower.
3) In SQL, a table can have a single clustered index whereas it can have multiple non-clustered indexes.
04
Round
Easy
HR Round
Duration30 Minutes
Interview date23 Aug 2019
Coding problem2
This was a typical HR round with some standard Behavioral questions.
1. Basic HR Question
Tell me something about yourself?
Problem approach
Tip 1 : Prepare the points that you will speak in your introduction prior to the interview.
Tip 2 : Tell about your current cgpa, achievements and authenticated certification
Tip 3 : I told about my role in current internship and what all I do
2. Basic HR Question
Why you want to be a part of Oracle?
Problem approach
Tip 1 : Oracle technologies are modern, cutting edge and built for enterprise requirements (think world class security, availability, performance, scalability, integrated ML/AI and so forth). Oracle Database is #1 worldwide.
Tip 2 : Since it’s inception, Oracle has become a market leader when it comes to database. Oracle has its own all possible solution for it’s clients whether it is into IT or Banking.
Tip 3 : Oracle gives your job sustainability with better career growth - in terms of job profile and package both.


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
How do you remove whitespace from the start of a string?
Choose another skill to practice
Similar interview experiences
Application Developer
4 rounds | 11 problems
Interviewed by Oracle
Selected 3526 views
0 comments
0 upvotes
Application Developer
4 rounds | 12 problems
Interviewed by Oracle
Selected 1228 views
0 comments
0 upvotes
Application Developer
4 rounds | 4 problems
Interviewed by Oracle
 Selected
Selected 5226 views
0 comments
0 upvotes
Application Developer
3 rounds | 4 problems
Interviewed by Oracle
Rejected
1840 views
0 comments
0 upvotes