


























Paytm (One97 Communications Limited) interview experience Real time questions & tips from candidates to crack your interview

SDE - 1
Paytm (One97 Communications Limited)
3 rounds | 6 Coding
problems
 Selected
Selected Interview preparation journey

Preparation
Duration: 5 months
Topics: Data Structures , Recursion, Backtracking, Dynamic Programming, OOPS, DBMS, Operating Systems,
Tip 1 : Have a good understanding of how a data structure operations work.
Tip 2 : Have a good understanding of time complexities for every solution you provide.
Tip 3 : Not every question is meant to be solved. You need to just keep digging for the optimised solution and the interviewer will judge you.
Tip 4 : Have your projects ready with all the questions related to it.
Tip 5: Never hesitate to ask the interviewer for clue if you are stuck in the question.
Application process
Where: Campus
Eligibility: Above 6 CGPA
Tip 1 : Have two good projects on Resume with different tech stacks.
Tip 2 : Do not put irrelevant info on Resume like hobbies , interests etc.
Tip 3 : Only mention those things which you are confident about.
Tip 4 : Try to use words like implemented, designed etc for your projects.
Interview rounds
01
Round
Medium
Online Coding Interview
Duration90 minutes
Interview date9 Aug 2021
Coding problem2
Timing - 9:30 AM
Since the round was online and we took it our homes only , so not much about the environment.
Everybody had to join the test link 10 minutes before to refer to the instructions of test.
The platform was pretty smooth. Didn't face any lags while coding.
1. Subtree of Another Tree
Easy
10m average time
90% success

0/40
Asked in companies
Given two binary trees T and S, check whether tree S has exactly the same structure and node values with a subtree of T, i.e., check if tree S is a subtree of the tree T.
A subtree of a tree T is a tree S consisting of a node in T and all of its descendants in T. The subtree corresponding to the root node is the entire tree; the subtree corresponding to any other node is called a proper subtree.
Problem approach
1. Used recursions to solve it.
2. We need to start from root and check every subtree of it with the given subRoot.
3. We need to check if the subtree is same as the tree starting from subroot , therefore make isSameTree() method to check it.
2. Delete Kth node From End
Moderate
15m average time
95% success
0/80
Asked in companies
You have been given a singly Linked List of 'N' nodes with integer data and an integer 'K'.
Your task is to remove the 'K'th node from the end of the given Linked List and return the head of the modified linked list.
Example:
Input : 1 -> 2 -> 3 -> 4 -> 'NULL' and 'K' = 2
Output: 1 -> 2 -> 4 -> 'NULL'
Explanation:
After removing the second node from the end, the linked list become 1 -> 2 -> 4 -> 'NULL'.
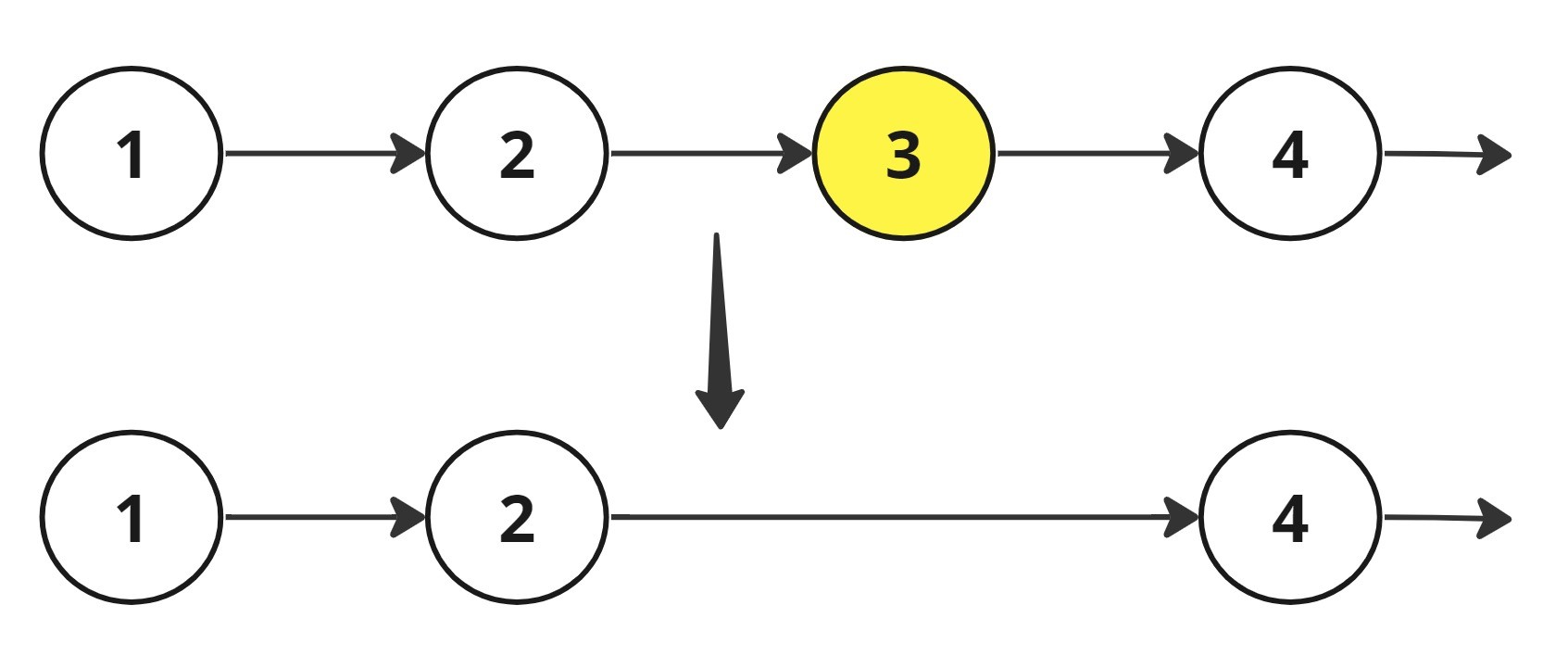
Problem approach
1. Find out the length of whole linked list.
2.Now calculate the difference of length and given n. ie dis=length-n. Dist is the length to node(say x) prior to the nth node which needs to be removed (say y).
3. Now travel again upto that dist .
4. Now all you need to is set the next pointer of x to next of y
i.e. x.next =x.next.next.
02
Round
Easy
Video Call
Duration60 minutes
Interview date10 Apr 2022
Coding problem2
The round was for about 1 hr .
The interviewer was friendly and very supportive.
He introduced himself first and asked me for my introduction.
1. Trapping Rain Water
Moderate
15m average time
80% success
0/80
Asked in companies

You have been given a long type array/list 'arr’ of size 'n’.
It represents an elevation map wherein 'arr[i]’ denotes the elevation of the 'ith' bar.
Print the total amount of rainwater that can be trapped in these elevations.
Note :
The width of each bar is the same and is equal to 1.
Example:
Input: ‘n’ = 6, ‘arr’ = [3, 0, 0, 2, 0, 4].
Output: 10
Explanation: Refer to the image for better comprehension:

Note :
You don't need to print anything. It has already been taken care of. Just implement the given function.
Problem approach
Basic Insight:
An element of the array can store water if there are higher bars on the left and right. The amount of water to be stored in every element can be found out by finding the heights of bars on the left and right sides. The idea is to compute the amount of water that can be stored in every element of the array.
Optimised solution.
Approach: In the previous solution, to find the highest bar on the left and right, array traversal is needed, which reduces the efficiency of the solution. To make this efficient, one must pre-compute the highest bar on the left and right of every bar in linear time. Then use these pre-computed values to find the amount of water in every array element.
Algorithm:
Create two arrays left and right of size n. create a variable max_ = INT_MIN.
Run one loop from start to end. In each iteration update max_ as max_ = max(max_, arr[i]) and also assign left[i] = max_
Update max_ = INT_MIN.
Run another loop from end to start. In each iteration update max_ as max_ = max(max_, arr[i]) and also assign right[i] = max_
Traverse the array from start to end.
The amount of water that will be stored in this column is min(a,b) – array[i],(where a = left[i] and b = right[i]) add this value to total amount of water stored
2. System Design Question
How would you design a dictionary ?
Problem approach
Tip 1: Asked about how many meanings can a word have.
Tip 2: Gave a map based implementation where a word is key and meaning is the value corresponding to it.
Tip 3: Then he was not satisfied much as words like say "AKASE" and "AKASH" would need seperate entries in the map.
Tip 4 : Then I gave a Trie based solution where identical prefixes were only stored once i.e "AKAS" prefix will be stored once only. and only seperate node will be created for "E" and "H". At the end node we can store the meaning.
03
Round
Easy
Video Call
Duration60 minutes
Interview date10 Apr 2022
Coding problem2
It was also for about 1 hour.
The round was good as the interviewer asked about DBMS and 1 DSA question.
The interviewer was very polite.
1. Chocolate Problem
Moderate
15m average time
85% success
0/80
Asked in companies
Given an array/list of integer numbers 'CHOCOLATES' of size 'N', where each value of the array/list represents the number of chocolates in the packet. There are ‘M’ number of students and the task is to distribute the chocolate to their students. Distribute chocolate in such a way that:
1. Each student gets at least one packet of chocolate.
2. The difference between the maximum number of chocolate in a packet and the minimum number of chocolate in a packet given to the students is minimum.
Example :
Given 'N' : 5 (number of packets) and 'M' : 3 (number of students)
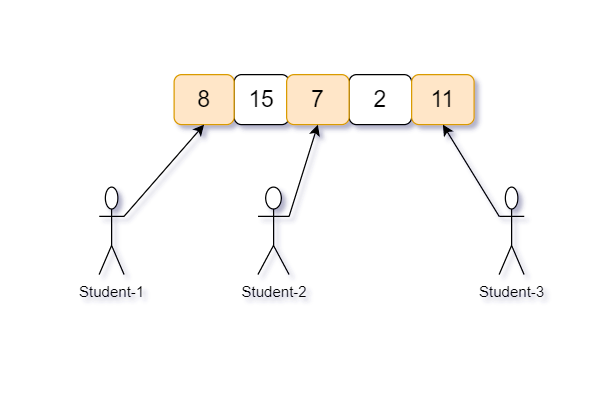
And chocolates in each packet is : {8, 11, 7, 15, 2}
All possible way to distribute 5 packets of chocolates among 3 students are -
( 8,15, 7 ) difference of maximum-minimum is ‘15 - 7’ = ‘8’
( 8, 15, 2 ) difference of maximum-minimum is ‘15 - 2’ = ‘13’
( 8, 15, 11 ) difference of maximum-minimum is ‘15 - 8’ = ‘7’
( 8, 7, 2 ) difference of maximum-minimum is ‘8 - 2’ = ‘6’
( 8, 7, 11 ) difference of maximum-minimum is ‘11 - 7’ = ‘4’
( 8, 2, 11 ) difference of maximum-minimum is ‘11 - 2’ = ‘9’
( 15, 7, 2 ) difference of maximum-minimum is ‘15 - 2’ = 13’
( 15, 7, 11 ) difference of maximum-minimum is ‘15 - 7’ = ‘8’
( 15, 2, 11 ) difference of maximum-minimum is ‘15 - 2’ = ‘13’
( 7, 2, 11 ) difference of maximum-minimum is ‘11 - 2’ = ‘9’
Hence there are 10 possible ways to distribute ‘5’ packets of chocolate among the ‘3’ students and difference of combination (8, 7, 11) is ‘maximum - minimum’ = ‘11 - 7’ = ‘4’ is minimum in all of the above.
Problem approach
1. First I gave bruteforce solution i.e generate all subsets of size m. For every subset, find the difference between the maximum and minimum elements in it. Finally, return the minimum difference.
2. I optimised it by sorting the array and use sliding window technique by maintaing a window of m.
3. The minimum difference between the max and min value in that window fetched me the answer.
2. DBMS Question
Given a table EmployeePosition .
Write a query to find the Nth highest salary from the table without using TOP/limit keyword.
Problem approach
SELECT Salary
FROM EmployeePosition E1
WHERE N-1 = (
SELECT COUNT( DISTINCT ( E2.Salary ) )
FROM EmployeePosition E2
WHERE E2.Salary > E1.Salary );


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
To make an AI less repetitive in a long paragraph, you should increase:
Choose another skill to practice
Similar interview experiences
SDE - 1
2 rounds | 3 problems
Interviewed by Paytm (One97 Communications Limited)
 Selected
Selected 923 views
0 comments
0 upvotes
SDE - 1
2 rounds | 5 problems
Interviewed by Paytm (One97 Communications Limited)
Rejected
716 views
0 comments
0 upvotes
SDE - 1
3 rounds | 10 problems
Interviewed by Paytm (One97 Communications Limited)
Rejected
542 views
0 comments
0 upvotes
SDE - 1
3 rounds | 8 problems
Interviewed by Paytm (One97 Communications Limited)
Selected 522 views
0 comments
0 upvotes
Companies with similar interview experiences
SDE - 1
5 rounds | 12 problems
Interviewed by Amazon
 Selected
Selected 114453 views
24 comments
0 upvotes
SDE - 1
4 rounds | 5 problems
Interviewed by Microsoft
Selected 57719 views
5 comments
0 upvotes
SDE - 1
3 rounds | 7 problems
Interviewed by Amazon
 Selected
Selected 34914 views
7 comments
0 upvotes