


























Robert Bosch Engineering and Business Solutions Vietnam interview experience Real time questions & tips from candidates to crack your interview

Associate Software Engineer
Robert Bosch Engineering and Business Solutions Vietnam
3 rounds | 11 Coding
problems

 Selected
Selected Interview preparation journey

Preparation
Duration: 4 Months
Topics: Data Structures, Algorithms, Computer Networks, Operating System, Software Design Patterns, OOPS
Tip 1 : Must do Previously asked Interview as well as Online Test Questions.
Tip 2 : Go through all the previous interview experiences from Codestudio and Leetcode.
Tip 3 : Do at-least 2 good projects and you must know every bit of them.
Application process
Where: Campus
Eligibility: Above 7 CGPA
Tip 1 : Have at-least 2 good projects explained in short with all important points covered.
Tip 2 : Every skill must be mentioned.
Tip 3 : Focus on skills, projects and experiences more.

Interview rounds
01
Round
Medium
Face to Face
Duration60 Minutes
Interview date15 Nov 2021
Coding problem4
This round had 2 coding questions of Easy to Medium level of difficulty followed by some more questions from OOPS.
1. Intersection of Linked List
Easy
25m average time
73% success

0/40
Asked in companies
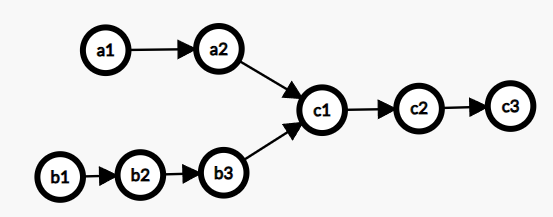
You are given two Singly Linked Lists of integers, which may have an intersection point.
Your task is to return the first intersection node. If there is no intersection, return NULL.
Example:-
The Linked Lists, where a1, a2, c1, c2, c3 is the first linked list and b1, b2, b3, c1, c2, c3 is the second linked list, merging at node c1.
Problem approach
Approach :
1) Calculate the length of both the lists, say len1 and len2
2) Get the absolute difference of the lengths, diff = |len1 – len2|
3) Now traverse the long list from the first node till ‘diff’ nodes so that from there onwards both the lists have equal
number of nodes
4) Then traverse both the lists in parallel and check whether a common node is reached (Note that getting a common
node is done by comparing the address of the nodes, not the data)
4.1) If yes, return that node’s data
4.2) If no, return -1
TC : O(N) , where N = max length of the linked list
SC : O(1)
2. Spiral Matrix
Easy
0/40
Asked in companies

You are given a N x M matrix of integers, print the spiral path of the matrix.
For example:

Problem approach
Approach :
spiralPrint(matrix[][], R, C, rows, cols):
1) Check for base cases, i.e. if outside the boundary of the matrix then return.
2) Print the first row from left to right of the matrix i.e from column ‘C’ to ‘cols’, print the elements of the Rth row.
3) Print the last column from top to bottom of the matrix i.e from row ‘R’ to ‘rows’, print the elements of the (cols)th
column.
4) Print the last row from right to left of the matrix i.e from column ‘cols’ to ‘C’, print the elements of the (rows)th row.
5) Print the first column from bottom to top of the matrix i.e from row ‘rows’ to ‘R’, print the elements of the Cth
column.
6) Call the function recursively with the updated values of boundaries, spiralPrint(matrix, R + 1, C + 1, rows - 1, cols -
1).
TC : O(N*M) , where N = number of rows and M = number of columns of the matrix.
SC : O(max(N,M))
3. OOPS Question
When can you use super keyword?
Problem approach
The super keyword is used to access hidden fields and overridden methods or attributes of the parent class.
Following are the cases when this keyword can be used :
1) Accessing data members of parent class when the member names of the class and its child subclasses are same.
2) To call the default and parameterized constructor of the parent class inside the child class.
3) Accessing the parent class methods when the child classes have overridden them.
4. OOPS Question
What do you mean by data encapsulation?
Problem approach
1) Data Encapsulation is an Object-Oriented Programming concept of hiding the data attributes and their behaviors in
a single unit.
2) It helps developers to follow modularity while developing software by ensuring that each object is independent of
other objects by having its own methods, attributes, and functionalities.
3) It is used for the security of the private properties of an object and hence serves the purpose of data hiding.
02
Round
Medium
Face to Face
Duration60 Minutes
Interview date15 Nov 2021
Coding problem5
This round started with 2 coding questions - the first one was related to Binary Tree and the second one was a simple questions related to Number Theory. After that, I was some questions related to DBMS towards the end of the interview.
1. Spiral Order Traversal of a Binary Tree
Easy
20m average time
75% success
0/40
Asked in companies
You have been given a binary tree of 'N' nodes. Print the Spiral Order traversal of this binary tree.
For example
For the given binary tree [1, 2, 3, -1, -1, 4, 5, -1, -1, -1, -1]
1
/ \
2 3
/ \
4 5
Output: 1 3 2 4 5
Problem approach
Approach :
1) We will maintain two stacks, one for each direction i.e. leftToRight and rightToleft.
2) We will do a level order traversal of the given binary tree and push nodes of each level onto one of the stack
according to the current direction of traversal.
3) After we’ve pushed all nodes of a level onto one stack, we’ll start popping those nodes. While popping the nodes
we will push their children (if any) onto our other direction stack, so that the next level be traversed in reverse order.
TC : O(N), where N=number of nodes in the binary tree
SC : O(N)
2. Find prime numbers
Easy
15m average time
80% success
0/40
Asked in companies

You are given a positive integer ‘N’. Your task is to print all prime numbers less than or equal to N.
Note: A prime number is a natural number that is divisible only by 1 and itself. Example - 2, 3, 17, etc.
You can assume that the value of N will always be greater than 1. So, the answer will always exist.
Problem approach
Approach (Using Sieve of Eratosthenes) :
1) First, we will make a boolean array/list isPrime of size N + 1. This will mark if a number is prime or not. Initially, all
values will be true.
2) Then, we initialize a variable num equal to 2 which represents the current processing prime number.
3) We will loop as num from 2 to N^½:
3.1) If num is not prime, we continue.
3.2) Else, we will mark all multiples of num in isPrime as false.
4) In the end, we will iterate through isPrime and store all primes in the result vector/list.
5) Finally, we return the result vector.
TC : O(N * log(log N)), where N is the given positive integer.
SC : O(N)
3. DBMS Question
Explain Left Outer Join and Right Outer Join.
Problem approach
LEFT JOIN :
The LEFT JOIN or the LEFT OUTER JOIN returns all the records from the left table and also those records which
satisfy a condition from the right table. Also, for the records having no matching values in the right table, the output or
the result-set will contain the NULL values.
Syntax:
SELECT Table1.Column1,Table1.Column2,Table2.Column1,....
FROM Table1
LEFT JOIN Table2
ON Table1.MatchingColumnName = Table2.MatchingColumnName;
RIGHT JOIN :
The RIGHT JOIN or the RIGHT OUTER JOIN returns all the records from the right table and also those records
which satisfy a condition from the left table. Also, for the records having no matching values in the left table, the
output or the result-set will contain the NULL values.
Syntax:
SELECT Table1.Column1,Table1.Column2,Table2.Column1,....
FROM Table1
RIGHT JOIN Table2
ON Table1.MatchingColumnName = Table2.MatchingColumnName;
4. DBMS Question
Difference between Primary key and Unique key
Problem approach
Primary Key : Used to serve as a unique identifier for each row in a table.
Unique Key : Uniquely determines a row which isn’t primary key.
Key Differences Between Primary key and Unique key :
1) Primary key will not accept NULL values whereas Unique key can accept NULL values.
2) A table can have only one primary key whereas there can be multiple unique key on a table.
3) A Clustered index automatically created when a primary key is defined whereas Unique key generates the non-
clustered index.
5. DBMS Question
What is meant by normalization and denormalization?
Problem approach
NORMALIZATION :
1) Normalization is a process of reducing redundancy by organizing the data into multiple tables.
2) Normalization leads to better usage of disk spaces and makes it easier to maintain the integrity of the database.
DENORMALIZATION :
1) Denormalization is the reverse process of normalization as it combines the tables which have been normalized into
a single table so that data retrieval becomes faster.
2) JOIN operation allows us to create a denormalized form of the data by reversing the normalization.
03
Round
Easy
HR Round
Duration30 Minutes
Interview date15 Nov 2021
Coding problem2
This was a typical HR round with some standard Behavioral questions.
1. Basic HR Question
Tell me something about yourself?
Problem approach
Tip 1 : Prepare the points that you will speak in your introduction prior to the interview.
Tip 2 : Tell about your current cgpa, achievements and authenticated certification
Tip 3 : I told about my role in current internship and what all I do
2. Basic HR Question
Why should we hire you ?
Problem approach
Tip 1 : The cross questioning can go intense some time, think before you speak.
Tip 2 : Be open minded and answer whatever you are thinking, in these rounds I feel it is important to have opinion.
Tip 3 : Context of questions can be switched, pay attention to the details. It is okay to ask questions in these round,
like what are the projects currently the company is investing, which team you are mentoring. How all is the work
environment etc.
Tip 4 : Since everybody in the interview panel is from tech background, here too you can expect some technical
questions. No coding in most of the cases but some discussions over the design can surely happen.


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
Which collection class forbids duplicates?
Choose another skill to practice
Similar interview experiences
Associate Software Engineer
3 rounds | 14 problems
Interviewed by Robert Bosch Engineering and Business Solutions Vietnam
Selected 1447 views
1 comments
0 upvotes
SDE - 1
3 rounds | 7 problems
Interviewed by OYO
Selected 5572 views
0 comments
0 upvotes
SDE - 1
2 rounds | 5 problems
Interviewed by Meesho
Rejected
6978 views
0 comments
0 upvotes
SDE - 1
3 rounds | 9 problems
Interviewed by Salesforce
 Selected
Selected 4113 views
0 comments
0 upvotes
Companies with similar interview experiences
Associate Software Engineer
3 rounds | 10 problems
Interviewed by Amdocs
Selected 2525 views
0 comments
0 upvotes

Associate Software Engineer
3 rounds | 2 problems
Interviewed by Ernst & Young (EY)
 Selected
Selected 2979 views
0 comments
0 upvotes
Associate Software Engineer
3 rounds | 15 problems
Interviewed by Ernst & Young (EY)
Selected 2546 views
0 comments
0 upvotes