


























Samsung interview experience Real time questions & tips from candidates to crack your interview
SDE - 1
Samsung
4 rounds | 11 Coding
problems

 Selected
Selected Interview preparation journey

Preparation
Duration: 4 Months
Topics: Data Structures, Algorithms, System Design, Aptitude, OOPS
Tip 1 : Must do Previously asked Interview as well as Online Test Questions.
Tip 2 : Go through all the previous interview experiences from Codestudio and Leetcode.
Tip 3 : Do at-least 2 good projects and you must know every bit of them.
Application process
Where: Campus
Eligibility: Above 7 CGPA
Tip 1 : Have at-least 2 good projects explained in short with all important points covered.
Tip 2 : Every skill must be mentioned.
Tip 3 : Focus on skills, projects and experiences more.

Interview rounds
01
Round
Medium
Online Coding Test
Duration120 Minutes
Interview date20 Aug 2019
Coding problem2
The round had 2 coding problems to solve with varying difficulty. Each candidate had a different set of questions. The round was around 2 pm. The webcam was turned on to keep an eye on candidates.
1. Bursting Balloons
Moderate
40m average time
60% success

0/80
Asked in companies

You are given an array 'ARR' of N integers. Each integer represents the height of a balloon. So, there are N balloons lined up.
Your aim is to destroy all these balloons. Now, a balloon can only be destroyed if the player shoots its head. So, to do the needful, he/ she shoots an arrow from the left to the right side of the platform, from an arbitrary height he/she chooses. The arrow moves from left to right, at a chosen height ARR[i] until it finds a balloon. The moment when an arrow touches a balloon, the balloon gets destroyed and disappears and the arrow continues its way from left to right at a height decreased by 1. Therefore, if the arrow was moving at height ARR[i], after destroying the balloon it travels at height ARR[i]-1. The player wins this game if he destroys all the balloons in minimum arrows.
You have to return the minimum arrows required to complete the task.
Problem approach
Approach :
1 )We will use a map data structure that will store the height of fired arrows.
2) Start a loop from i = 0 to i = N - 1 and for the i’th balloon if the map contains the value ARR[i] then it
means this balloon will get hit by the previous arrow.
2.1) Therefore decrease the count of ARR[i] in the map and if it becomes 0 remove the key from the
map.
2.2) Increase the count of ARR[i]-1 in the map because there is an arrow at this height available.
3) If the map does not contain the ARR[i] then We will need to fire a new arrow to increase the count of
ARR[i] in the map.
4) Now at the end find the sum of all the arrows present in the map and return it.
TC : O(N)), where N is the number of balloons.
SC : O(N)
2. Count Leaf Nodes
Easy
10m average time
90% success
0/40
Asked in companies
You are given a Binary tree. You have to count and return the number of leaf nodes present in it.
A binary tree is a tree data structure in which each node has at most two children, which are referred to as the left child and the right child
A node is a leaf node if both left and right child nodes of it are NULL.
Problem approach
Approach :
1) Given a tree node ROOT, initialise a queue of nodes NODEQUEUE and COUNT by 0.
2) Push ROOT into NODEQUEUE.
3) While NODEQUEUE is not empty do:
3.1) Initialize node TEMP as NODEQUEUE.peek().
3.2) If TEMP.left is not NULL, push TEMP.left to NODEQUEUE.
3.3) If TEMP.right is not NULL, push TEMP.right to NODEQUEUE.
3.4) If TEMP.right and TEMP.left are both NULL, increase COUNT by 1.
4) Return COUNT
TC : O(N), where N=number of nodes in the tree
SC : O(N)
02
Round
Medium
Face to Face
Duration60 Minutes
Interview date21 Aug 2019
Coding problem2
This round had 2 questions related to DSA. I was first asked to explain my approach with proper complexity analysis and then code the soution in any IDE that I prefer.
1. Rod cutting problem
Moderate
40m average time
75% success
0/80
Asked in companies

Given a rod of length ‘N’ units. The rod can be cut into different sizes and each size has a cost associated with it. Determine the maximum cost obtained by cutting the rod and selling its pieces.
Note:
1. The sizes will range from 1 to ‘N’ and will be integers.
2. The sum of the pieces cut should be equal to ‘N’.
3. Consider 1-based indexing.
Problem approach
Approach : This was a very standard problem related to DP and I had already solved it in platforms like LeetCode and CodeStudio . I first gave the recursive approach and then optimised it using memoisation. The interviewer then asked me to do the same problem using iterative DP this time.
Steps :
1) Declare an array, ‘COST’ of size ‘'N'+1’ and initialize 'COST'[0] = 0. We use this 1 D array to store the previous COST and with every iteration, we update the COST.
2) Run a loop where 1<= 'I' <= 'N'. Consider ‘'I'’ as the length of the rod.
3) Divide the rod of length 'I' into two rods of length 'J' and 'I' - 'J' - 1 using a nested loop in which 0<=j<'I'. Find the COST of this division using A['J'] + COST[i - j -1] and compare it with the already existing value in the array COST[].
4) Store the maximum value at every index 'X', which represents the maximum value obtained for partitioning a rod of length ‘X’.
5) For a greater length, all the possible combinations are formed with all the pre-calculated shorter lengths, and the maximum of them is stored in a COST array with every iteration.
6) Lastly, COST[N] stores the maximum COST obtained for a rod of length 'N'.
TC : O(N^2)
SC : O(N)
2. Count Subarrays with Given XOR
Moderate
15m average time
85% success
0/80
Asked in companies
Given an array of integers ‘ARR’ and an integer ‘X’, you are supposed to find the number of subarrays of 'ARR' which have bitwise XOR of the elements equal to 'X'.
Note:
An array ‘B’ is a subarray of an array ‘A’ if ‘B’ that can be obtained by deletion of, several elements(possibly none) from the start of ‘A’ and several elements(possibly none) from the end of ‘A’.
Problem approach
Approach 1 (Brute Force) :
1) Create a variable ans, which stores the total number of subarrays. We will set the variable ans as 0.
2) Iterate index from 0 to N - 1.
3) Iterate pos from index to M - 1.
3.1) We will maintain a variable currentXor, which will store the XOR of all elements present in the
current subarray. We will set currentXor as 0.
4) We will traverse num from index to pos. We will update currentXor with XOR of currentXor and
ARR[num].
4.1) Check if currentXor is equal to X.
4.2) Increment ans by 1.
5) Return the variable ans.
TC : O(N^3), where N=size of the array
SC : O(1)
Approach 2 (Using Hashing) :
1) Create a HashMap “prefXor” which stores the count of subarrays having a particular XOR value.
2) Create a variable “curXor” which stores the XOR for ‘i’ elements. Initialise it with zero. Also, create a
variable called “ans” to store the count of the subarrays having XOR ‘X’.
3) Start iterating through given array/list using a variable ‘i’ such that 0 <= ‘i’ < n
3.1) Update the “curXor” i.e. curXor = curXor ^ arr[i]
3.2) Store the required value of the prefix Xor to make the XOR of the subarray ending at the current
index equal to X i.e. req = X ^ curXor
3.3) Now add the count of prefix arrays with required xor i.e. ans = ans + prefXor[req]
3.4) Update the “prefXor” HashMap with the “curXor” i.e. prefXor[curXor] = prefXor[curXor] + 1
TC : O(N), where N=size of the array
SC : O(N)
03
Round
Medium
Face to Face
Duration60 Minutes
Interview date21 Aug 2019
Coding problem3
This round had 2 questions of DSA of Easy-Medium difficulty and at the end I was asked a Puzzle to check my general problem solving ability.
1. Rotting Oranges
Moderate
20m average time
78% success
0/80
Asked in companies
You have been given a grid containing some oranges. Each cell of this grid has one of the three integers values:
Every second, any fresh orange that is adjacent(4-directionally) to a rotten orange becomes rotten.
Your task is to find out the minimum time after which no cell has a fresh orange. If it's impossible to rot all the fresh oranges then print -1.
Note:
1. The grid has 0-based indexing.
2. A rotten orange can affect the adjacent oranges 4 directionally i.e. Up, Down, Left, Right.
Problem approach
Approach : I solved this problem using Multisource-BFS as I had solved questions similar to this while preparing for my interviews.
Steps :
1) Initialize ‘TIME’ to 0.
2) Declare a Queue data structure and a 2D boolean array ‘VISITED’.
3) Push all cells with rotten orange to the queue.
4) Loop till queue is not empty
4.1) Get the size of the current level/queue.
4.2) Loop till the 'LEVEL_SIZE' is zero:
i) Get the front cell of the queue.
ii) Push all adjacent cells with fresh oranges to the queue.
iii) Mark the cells visited which are pushed into the queue.
4.3) Increment ‘TIME’ by 1.
5) Iterate the grid again. If a fresh orange is still present, return -1.
6) Return maximum of ‘TIME’ - 1 and 0.
TC : O(N * M), where N and M are the numbers of rows and columns of the grid respectively.
SC : O(N*M)
2. Detect and Remove Loop
Moderate
10m average time
90% success
0/80
Asked in companies
Given a singly linked list, you have to detect the loop and remove the loop from the linked list, if present. You have to make changes in the given linked list itself and return the updated linked list.
Expected Complexity: Try doing it in O(n) time complexity and O(1) space complexity. Here, n is the number of nodes in the linked list.
Problem approach
Approach 1(Using Hashing) :
We are going to maintain a lookup table(a Hashmap) that basically tells if we have already visited a node or not,
during the course of traversal.
Steps :
1) Visit every node one by one, until null is not reached.
2) Check if the current node is present in the loop up table, if present then there is a cycle and will return
true, otherwise, put the node reference into the lookup table and repeat the process.
3) If we reach at the end of the list or null, then we can come out of the process or loop and finally, we can
say the loop doesn't exist.
TC : O(N), where N is the total number of nodes.
SC : O(N)
Approach 2 (Using Slow and Fast Pointers) :
Steps :
1) The idea is to have 2 pointers: slow and fast. Slow pointer takes a single jump and corresponding to
every jump slow pointer takes, fast pointer takes 2 jumps. If there exists a cycle, both slow and fast
pointers will reach the exact same node. If there is no cycle in the given linked list, then fast pointer will
reach the end of the linked list well before the slow pointer reaches the end or null.
2) Initialize slow and fast at the beginning.
3) Start moving slow to every next node and moving fast 2 jumps, while making sure that fast and its next
is not null.
4) If after adjusting slow and fast, if they are referring to the same node, there is a cycle otherwise repeat
the process
5) If fast reaches the end or null then the execution stops and we can conclude that no cycle exists.
TC : O(N), where N is the total number of nodes.
SC : O(1)
3. Puzzle
Two wire burning puzzle.
Problem approach
If we light a stick, it takes 60 minutes to burn completely. What if we light the stick from both sides? It will take exactly half the original time, i.e. 30 minutes to burn completely.
1) 0 minutes – Light stick 1 on both sides and stick 2 on one side.
2) 30 minutes – Stick 1 will be burnt out. Light the other end of stick 2.
3) 45 minutes – Stick 2 will be burnt out. Thus 45 minutes is completely measured.
04
Round
Medium
Face to Face
Duration50 Minutes
Interview date21 Aug 2019
Coding problem4
This round had 2 Algorithmic questions wherein I was supposed to code both the problems after discussing their
approaches and respective time and space complexities . After that , I was grilled on some OOPS concepts related to C++.
1. Longest Palindromic Substring
Moderate
20m average time
80% success
0/80
Asked in companies
You are given a string ('STR') of length 'N'. Find the longest palindromic substring. If there is more than one palindromic substring with the maximum length, return the one with the smaller start index.
Note:
A substring is a contiguous segment of a string.
For example : The longest palindromic substring of "ababc" is "aba", since "aba" is a palindrome and it is the longest substring of length 3 which is a palindrome, there is another palindromic substring of length 3 is "bab" since "aba" starting index is less than "bab", so "aba" is the answer.
Problem approach
Approach :
1) Create a 2-D dp boolean vector(with all false initially) where dp[i][j] states whether s[i...j] is a palindrome or not and initilialise a variable ans=1 which will store the final answer.
2) Base Case : For every i from 0 to n-1 fill dp[i][i]=1 ( as a single character is always a palindrome ) .
3) Now, run 2 loops first one from i=n-1 to i=0 (i.e., tarverse from the back of the string) and the second one from j=i+1 to n .
4) For every s[i]==s[j] , check if(j-i==1 i.e., if s[i] and s[ j] are two consecutive same letters) or if(dp[i+1][j-1]==1 or not i.e., if the string s[i+1,....j-1] is palindrome or not .
5) Because if the string s[i+1,....j-1] is a palindrome and s[i]==s[j] then s[i] and s[j] can be appended at the starting and the ending position of s[i+1,...j-1] and s[i...j] will then be a palindrome , so mark dp[i][j]=1 and update the answer as ans=max(ans , j-i+1).
6) Finally return the ans
TC : O(N^2) where N=length of the string s
SC : O(N^2)
2. Quick Sort
Moderate
10m average time
90% success
0/80
Asked in companies
You are given an array of integers. You need to sort the array in ascending order using quick sort.
Quick sort is a divide and conquer algorithm in which we choose a pivot point and partition the array into two parts i.e, left and right. The left part contains the numbers smaller than the pivot element and the right part contains the numbers larger than the pivot element. Then we recursively sort the left and right parts of the array.
Example:
Let the array = [ 4, 2, 1, 5, 3 ]
Let pivot to be the rightmost number.
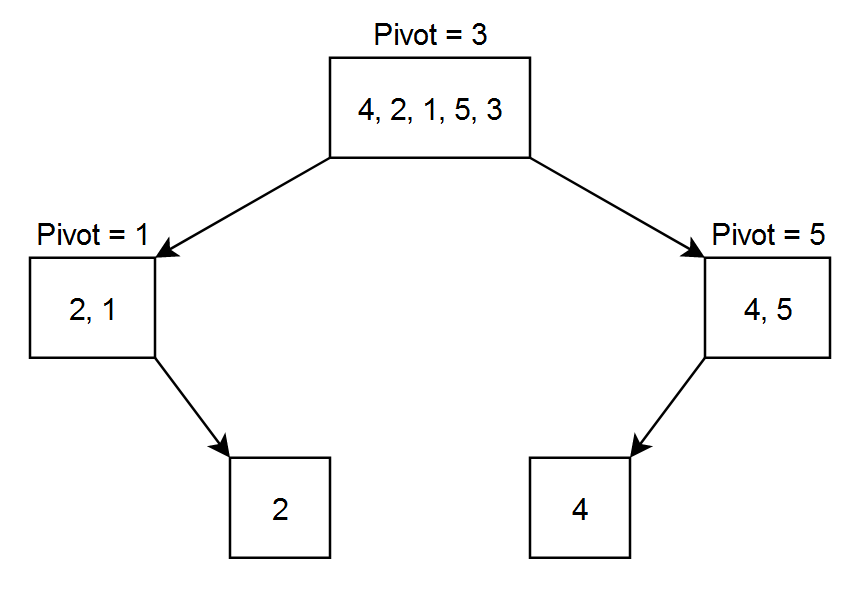
After the 1st level partitioning the array will be { 2, 1, 3, 4, 5 } as 3 was the pivot. After 2nd level partitioning the array will be { 1, 2, 3, 4, 5 } as 1 was the pivot for the left part and 5 was the pivot for the right part. Now our array is sorted and there is no need to divide it again.
Problem approach
Approach :
1) Select any splitting value, say L. The splitting value is also known as Pivot.
2) Divide the stack of papers into two. A-L and M-Z. It is not necessary that the piles should be equal.
3) Repeat the above two steps with the A-L pile, splitting it into its significant two halves. And M-Z pile, split into its halves. The process is repeated until the piles are small enough to be sorted easily.
4) Ultimately, the smaller piles can be placed one on top of the other to produce a fully sorted and ordered set of papers.
5) The approach used here is reduction at each split to get to the single-element array.
6) At every split, the pile was divided and then the same approach was used for the smaller piles by using the method of recursion.
Technically, quick sort follows the below steps:
Step 1 − Make any element as pivot
Step 2 − Partition the array on the basis of pivot
Step 3 − Apply quick sort on left partition recursively
Step 4 − Apply quick sort on right partition recursively
//Pseudo Code :
quickSort(arr[], low, high)
{
if (low < high)
{
pivot_index = partition(arr, low, high);
quickSort(arr, low, pivot_index - 1); // Before pivot_index
quickSort(arr, pivot_index + 1, high); // After pivot_index
}
}
partition (arr[], low, high)
{
// pivot - Element at right most position
pivot = arr[high];
i = (low - 1);
for (j = low; j <= high-1; j++)
{
if (arr[j] < pivot)
{
i++;
swap(arr[i], arr[j]);
}
}
swap(arr[i + 1], arr[high]);
return (i + 1);
}
Complexity Analysis :
TC : Best Case - O(N*log(N))
Worst Case - O(N^2)
SC : Average Case - O(log(N))
Worst Case - O(N)
3. OOPS Question
What are Friend Functions in C++?
Problem approach
Answer :
1) Friend functions of the class are granted permission to access private and protected members of the class in C++. They are defined globally outside the class scope. Friend functions are not member functions of the class.
2) A friend function is a function that is declared outside a class but is capable of accessing the private and protected members of the class.
3) There could be situations in programming wherein we want two classes to share their members. These members may be data members, class functions or function templates. In such cases, we make the desired function, a friend to both these classes which will allow accessing private and protected data members of the class.
4) Generally, non-member functions cannot access the private members of a particular class. Once declared as a friend function, the function is able to access the private and the protected members of these classes.
Some Characteristics of Friend Function in C++ :
1) The function is not in the ‘scope’ of the class to which it has been declared a friend.
2) Friend functionality is not restricted to only one class
3) Friend functions can be a member of a class or a function that is declared outside the scope of class.
4) It cannot be invoked using the object as it is not in the scope of that class.
5) We can invoke it like any normal function of the class.
6) Friend functions have objects as arguments.
7) It cannot access the member names directly and has to use dot membership operator and use an object
name with the member name.
8) We can declare it either in the ‘public’ or the ‘private’ part.
4. OOPS Question
What is Early Binding and Late Binding in C++ ?
Problem approach
Answer :
OOP is used commonly for software development. One major pillar of OOP is polymorphism. Early Binding and Late Binding are related to that. Early Binding occurs at compile time while Late Binding occurs at runtime. In method overloading, the bonding happens using the early binding. In method overriding, the bonding happens using the late binding. The difference between Early and Late Binding is that Early Binding uses the class information to resolve method calling while Late Binding uses the object to resolve method calling.
Early Binding : In Early Binding, the class information is used to resolve method calling. Early Binding occurs at compile time. It is also known as the static binding. In this process, the binding occurs before the program actually runs. Overloading methods are bonded using early binding.
Late Binding : In Late Binding, the object is used to resolve method calling. Late Binding occurs at runtime. It is also known as dynamic binding. In this process, the binding occurs at program execution. Overridden methods are bonded using late binding.


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
How do you remove whitespace from the start of a string?
Choose another skill to practice
Similar interview experiences
SDE - 1
4 rounds | 6 problems
Interviewed by Samsung
Selected 1921 views
0 comments
0 upvotes
SDE - 1
3 rounds | 4 problems
Interviewed by Samsung
Selected 1221 views
0 comments
0 upvotes
SDE - 1
3 rounds | 6 problems
Interviewed by Samsung
Rejected
2229 views
0 comments
0 upvotes
SDE - 1
3 rounds | 5 problems
Interviewed by Samsung
Rejected
419 views
0 comments
0 upvotes
Companies with similar interview experiences
SDE - 1
5 rounds | 12 problems
Interviewed by Amazon
 Selected
Selected 115097 views
24 comments
0 upvotes
SDE - 1
4 rounds | 5 problems
Interviewed by Microsoft
Selected 58237 views
5 comments
0 upvotes
SDE - 1
3 rounds | 7 problems
Interviewed by Amazon
 Selected
Selected 35147 views
7 comments
0 upvotes