


























Samsung interview experience Real time questions & tips from candidates to crack your interview
SDE - 1
Samsung
3 rounds | 11 Coding
problems

 Selected
Selected Interview preparation journey

Preparation
Duration: 4 Months
Topics: Data Structures, Algorithms, System Design, Aptitude, OOPS
Tip 1 : Must do Previously asked Interview as well as Online Test Questions.
Tip 2 : Go through all the previous interview experiences from Codestudio and Leetcode.
Tip 3 : Do at-least 2 good projects and you must know every bit of them.
Application process
Where: Campus
Eligibility: Above 7 CGPA
Tip 1 : Have at-least 2 good projects explained in short with all important points covered.
Tip 2 : Every skill must be mentioned.
Tip 3 : Focus on skills, projects and experiences more.

Interview rounds
01
Round
Medium
Online Coding Test
Duration120 Minutes
Interview date12 Jul 2018
Coding problem3
This was an online coding round where we had 3 questions to solve under 120 minutes. The questions were of medium to hard difficulty level.
1. Minimum Time in Wormhole Network
Hard
44m average time

0/120
Asked in companies

You will be given a starting point (sx, sy) and a destination point (dx, dy) in the two-dimensional coordinate system representing the universe.
Your spacecraft can move only in X(left or right) or Y(up or down) direction, and not in the diagonal direction. To go from one point (x1, y1) to another point (x2, y2), total time taken is |x2 - x1| + |y2 - y1| seconds.
Also, in this two-dimensional system, N wormholes are present. If you go through a wormhole, spacecraft will take some time to travel from the entry of the wormhole to its exit point. You have to find out the minimum time in which you can go from the source to the destination.
What is a Wormhole?
A wormhole is a sort of tunnel that joins distant points in space, or even two universes, via space-time curvature. Theoretically, such a tunnel could be traversed from one point in space to another without actually travelling the distance between them.
Note:
1. Endpoints of all the wormholes are pairwise distinct.
It means if a wormhole starts or ends at the coordinate (x, y) then no other wormhole will start or end from the same coordinate. This holds true for the source and the destination coordinates as well.
2. If your path intersects with the wormhole, your spacecraft won't get sucked into the wormhole. As soon as you reach the entry/exit point of a wormhole you will come out from the exit/entry point( Wormholes are bi-directional).
Problem approach
Approach(Using Djikstra's Algorithm) :
1) Mark the source point as vertex 0, destination point as vertex 1 and all the wormholes are formed with start point and endpoint so similarly mark the start point as next vertex number 2 and endpoint as next vertex number 3 and so on.
2) Now create a complete graph using adjacency matrix which will store the time to reach from vertex i to vertex j (Calculated using the given formula in the description). This graph contains the time without considering any wormhole.
3) Now, we need to update the time according to wormholes.
4) Since we know that if we reach the start/end point of a wormhole we must use it (we can't bypass the wormhole), so we change the time for all the wormholes to the time given for the wormholes in the input without any other check.
5) Now, we need to apply the Dijkstra algorithm to find minimum time from source to destination in this graph.
TC : O(N^2), where N is the number of vertices which is equal to 2*(Number of wormholes+2)
SC : O(N^2)
2. Substrings differ by one
Moderate
15m average time
85% success
0/80
Asked in company
This time Ninja is fighting with string man, but string man is too powerful for the Ninja to defeat him alone. So Ninja needs your help to defeat him, Ninja has two strings ‘S’ and ‘T’ to defeat string man Ninja has to find the number of substrings in ‘S’ that differ from some substrings of ‘T’ by exactly one character.
Help Ninja by telling him the number of such types of substrings.
For example:
‘S’ = “aba” ‘T’ = “aca” then
(a, c)
(b, a)
(b, c)
(b, a)
(a, c)
(ab, ac)
(ba, ca)
(aba, aca)
Total 8 strings.
Problem approach
Approach (Using DP) :
Let,
DPL[ i ][ j ] : size of matching substring ending at position (i, j)
DPR[ i ][ j ] : size of matching substring starting at position (i, j)
Steps :
1) Declare two 2-d array DPL and DPR of size (N + 1) x (M + 1) initialise both with all ‘0’ and variable ANS= 0
2) Run nested loop
for( i : 1 -> N )
for( j : 1 -> M )
if(S[ i - 1] = T[ j - 1 ])
DPL[ i ][ j ] = 1 + DPL[i - 1][j - 1]
3) Again implemented steps for DPR but in reverse i.e. from N -> 1 and M -> 1
4) After this, for each mismatched character in ‘s’ and ‘t’
ans += DPL[i][j] * DPR[i + 1][j + 1]
5) Return ANS.
TC : O(N*M), where ‘N’ and ‘M’ is the length of the given strings ‘S’ and ‘T’.
SC : O(N*M)
3. Power of Two
Easy
15m average time
85% success
0/40
Asked in companies

You have been given an integer 'N'.
Your task is to return true if it is a power of two. Otherwise, return false.
An integer 'N' is a power of two, if it can be expressed as 2 ^ 'K' where 'K' is an integer.
For example:
'N' = 4,
4 can be represented as 2^2. So, 4 is the power of two, and hence true is our answer.
Problem approach
Approach : If a number N is power of 2 then bitwise & of N and N-1 will be zero. We can say N is a power of 2 or not based on the value of N&(N-1). The expression N&(N-1) will not work when N is 0.
So,handle that case separately.
TC : O(1)
SC : O(1)
02
Round
Medium
Face to Face
Duration60 Minutes
Interview date12 Jul 2018
Coding problem4
This round had 2 questions related to DSA where I was first expected to explain my approaches and then discuss the time and space complexities of my solution. After that , I was asked some core concepts related to OS.
1. Reverse Linked List
Moderate
15m average time
85% success
0/80
Asked in companies

Given a singly linked list of integers. Your task is to return the head of the reversed linked list.
For example:
The given linked list is 1 -> 2 -> 3 -> 4-> NULL. Then the reverse linked list is 4 -> 3 -> 2 -> 1 -> NULL and the head of the reversed linked list will be 4.
Follow Up :
Can you solve this problem in O(N) time and O(1) space complexity?
Problem approach
Iterative(Without using stack):
1) Initialize three pointers prev as NULL, curr as head and next as NULL.
2) Iterate through the linked list. In loop, do following.
// Before changing next of current,
// store next node
next = curr->next
// Now change next of current
// This is where actual reversing happens
curr->next = prev
// Move prev and curr one step forward
prev = curr
curr = next
3)Finally the prev pointer contains our head , i,e. ,head=prev .
TC : O(n)
SC: O(1)
Recursive:
1) Divide the list in two parts - first node and rest of the linked list.
2) Call reverse for the rest of the linked list.
3) Link rest to first.
4) Fix head pointer
TC:O(n)
SC:O(n)
Iterative(Using Stack):
1) Store the nodes(values and address) in the stack until all the values are entered.
2) Once all entries are done, Update the Head pointer to the last location(i.e the last value).
3) Start popping the nodes(value and address) and store them in the same order until the stack is empty.
4) Update the next pointer of last Node in the stack by NULL.
TC: O(n)
SC:O(n)
2. Cycle Detection In Undirected Graph
Moderate
0/80
Asked in companies
You have been given an undirected graph with 'N' vertices and 'M' edges. The vertices are labelled from 1 to 'N'.
Your task is to find if the graph contains a cycle or not.
A path that starts from a given vertex and ends at the same vertex traversing the edges only once is called a cycle.
Example :
In the below graph, there exists a cycle between vertex 1, 2 and 3.
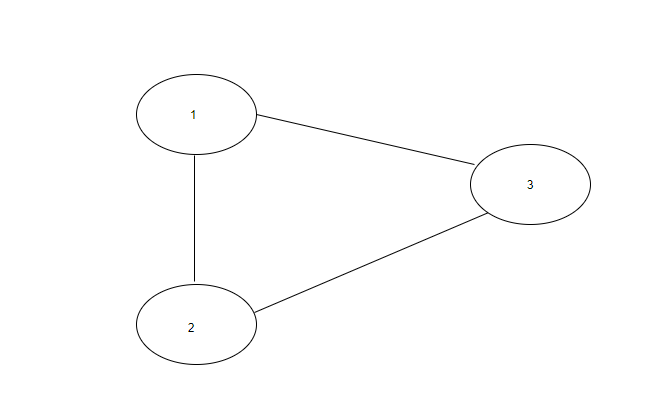
Note:
1. There are no parallel edges between two vertices.
2. There are no self-loops(an edge connecting the vertex to itself) in the graph.
3. The graph can be disconnected.
For Example :
Input: N = 3 , Edges = [[1, 2], [2, 3], [1, 3]].
Output: Yes
Explanation : There are a total of 3 vertices in the graph. There is an edge between vertex 1 and 2, vertex 2 and 3 and vertex 1 and 3. So, there exists a cycle in the graph.
Problem approach
The main question did boil down to cycle detection in an undirected graph and hecne I put forward my approach as follows :
Appraoch 1 (Using DFS) :
1) We create a graph using the ‘EDGES’ array and initialise an array ‘VISITED’ to keep track of the visited vertices.
2) We iterate over all vertices of the graph and if the vertex is unvisited, we call the ‘IS_CYCLE’ function from that vertex. The ‘IS_CYCLE’ function works as follows:
2.1) Mark the current vertex true in the ‘VISITED’ array.
2.2) Find all the adjacent vertices of the current vertex.
2.3) If an adjacent vertex is not visited
2.4) Recursively call the ‘IS_CYCLE’ function for the adjacent vertex.
2.5) If the recursive function returns true, then return true.
2.6) Else if the adjacent vertex is already visited and is not the parent vertex of the current vertex.
2.7) Return true.
2.8) Finally, return false.
3) If the ‘IS_CYLCE’ function returns true, then return “Yes”. Else return “No”.
TC : O(N+M), where ‘N’ is the number of vertices and ‘M’ is the number of edges in the graph.
SC : O(N)
Approach 2 (Using BFS) :
1) We push the current vertex in the queue.
2) We then run a while loop until the queue becomes empty.
2.1) Pop the front vertex from the queue.
2.2) We mark it true in the ‘VISITED’ array.
2.3) Find all the adjacent vertices of the current vertex.
2.4) If the adjacent vertex is not visited:
2.5) We mark it true in the ‘VISITED’ array and push it in the queue.
2.6) Else if the adjacent vertex is visited and it is not the parent vertex of the current vertex.
2.7) Return true
3) Finally, return false.
TC : O(N+M), where ‘N’ is the number of vertices and ‘M’ is the number of edges in the graph.
SC : O(N)
3. OS Question
What are the differences b/w mutex and semaphore?
Problem approach
Answer :
Semaphore : Semaphore is simply a variable that is non-negative and shared between threads. A semaphore is a signaling mechanism, and a thread that is waiting on a semaphore can be signaled by another thread. It uses two atomic operations, 1)wait, and 2) signal for the process synchronization.
A semaphore either allows or disallows access to the resource, which depends on how it is set up.
Mutex : The full form of Mutex is Mutual Exclusion Object. It is a special type of binary semaphore which used for controlling access to the shared resource. It includes a priority inheritance mechanism to avoid extended priority inversion problems. It allows current higher priority tasks to be kept in the blocked state for the shortest time possible. However, priority inheritance does not correct priority- inversion but only minimizes its effect.
Main Differences b/w Mutex and Semaphore :
1) Mutex is a locking mechanism whereas Semaphore is a signaling mechanism
2) Mutex is just an object while Semaphore is an integer
3) Mutex has no subtype whereas Semaphore has two types, which are counting semaphore and binary semaphore.
4) Semaphore supports wait and signal operations modification, whereas Mutex is only modified by the process that may request or release a resource.
5) Semaphore value is modified using wait () and signal () operations, on the other hand, Mutex operations are locked or unlocked.
4. OS Question
What is meant by Multitasking and Multithreading in OS?
Problem approach
Answer :
Multitasking : It refers to the process in which a CPU happens to execute multiple tasks at any given time. CPU switching occurs very often when multitasking between various tasks. This way, the users get to collaborate with every program together at the same time. Since it involves rapid CPU switching, it requires some time. It is because switching from one user to another might need some resources. The processes in multi-tasking, unlike multi-threading, share separate resources and memories.
Multithreading : It is a system that creates many threads out of a single process to increase the overall power and working capacity of a computer. In the process of multi-threading, we use a CPU for executing many threads out of a single process at any given time. Also, the process of creation depends entirely on the cost. The process of multithreading, unlike multitasking, makes use of the very same resources and memory for processing the execution.
03
Round
Medium
Face to Face
Duration60 Minutes
Interview date12 Jul 2018
Coding problem4
This round had 2 Algorithmic questions wherein I was supposed to code both the problems after discussing their
approaches and respective time and space complexities . After that , I was grilled on some OOPS concepts related to C++.
1. Trapping Rain Water
Moderate
15m average time
80% success
0/80
Asked in companies

You have been given a long type array/list 'arr’ of size 'n’.
It represents an elevation map wherein 'arr[i]’ denotes the elevation of the 'ith' bar.
Print the total amount of rainwater that can be trapped in these elevations.
Note :
The width of each bar is the same and is equal to 1.
Example:
Input: ‘n’ = 6, ‘arr’ = [3, 0, 0, 2, 0, 4].
Output: 10
Explanation: Refer to the image for better comprehension:

Note :
You don't need to print anything. It has already been taken care of. Just implement the given function.
Problem approach
Approach 1 (Brute Force) :
1) Iterate over every elevation or element and find the maximum elevation on to the left and right of it. Say, the maximum elevation on to the left of the current elevation or element that we are looking at is ‘maxLeftHeight’ and the maximum elevation on to the right of it is ‘maxRightHeight’.
2) Take the minimum of ‘maxLeftHeight’ and ‘maxRightHeight’ and subtract it from the current elevation or element. This will be the units of water that can be stored at this elevation.
3) Compute units of water that every elevation can store and sum them up to return the total units of water that can be stored.
TC : O(N^2), where ‘N’ is the total number of elevations in the map.
SC : O(1)
Approach 2 (Efficient Approach) :
1) Create two lists or arrays, say, ‘leftMax’ and ‘rightMax’.
2) At every index in the ‘leftMax’ array store the information of the ‘leftMaxHeight’ for every elevation in the map.
3) Similarly, at every index in the ‘rightMax’ array store the information of the ‘rightMaxHeight' for every elevation in the map.
4) Iterate over the elevation map and find the units of water that can be stored at this location by getting the left max height and right max height from the initial arrays that we created.
TC : O(N), where ‘N’ is the total number of elevations in the map.
SC : O(N)
2. Find The Repeating And Missing Number
Easy
10m average time
90% success
0/40
Asked in companies
You are given an array 'nums' consisting of first N positive integers. But from the N integers, one of the integers occurs twice in the array, and one of the integers is missing. You need to determine the repeating and the missing integer.
Example:
Let the array be [1, 2, 3, 4, 4, 5]. In the given array ‘4’ occurs twice and the number ‘6’ is missing.
Problem approach
Approach 1 :
1) We use a count array to store the frequency.
2) We initialize the count array to zero for all the numbers.
3) Now, iterate through the array and increment the corresponding frequency count of the numbers.
4) Now, we iterate through the count (frequency) array.
5) The number with a frequency equal to zero is the missing number while the number with a frequency equal to two is the repeating number.
TC : O(N), where N=size of the array
SC : O(N)
Approach 2 :
1) Traverse the array and mark the index corresponding to the current number.
2) While traversing if the index corresponding to the current number has already been marked. Then the current number is the repeating number in the array.
3) In order to determine the missing number, traverse the array again and look for a positive value.
4) The index corresponding to the positive number gives us the missing number (= index + 1).
TC : O(N), where N=size of the array
SC : O(1)
3. OOPS Question
What is Diamond Problem in C++ and how do we fix it?
Problem approach
Answer :
The Diamond Problem : The Diamond Problem occurs when a child class inherits from two parent classes who both share a common grandparent class i.e., when two superclasses of a class have a common base class.
Solving the Diamond Problem in C++ : The solution to the diamond problem is to use the virtual keyword. We make the two parent classes (who inherit from the same grandparent class) into virtual classes in order to avoid two copies of the grandparent class in the child class.
4. OOPS Question
What are Friend Functions in C++?
Problem approach
Answer :
1) Friend functions of the class are granted permission to access private and protected members of the class in C++. They are defined globally outside the class scope. Friend functions are not member functions of the class.
2) A friend function is a function that is declared outside a class but is capable of accessing the private and protected members of the class.
3) There could be situations in programming wherein we want two classes to share their members. These members may be data members, class functions or function templates. In such cases, we make the desired function, a friend to both these classes which will allow accessing private and protected data members of the class.
4) Generally, non-member functions cannot access the private members of a particular class. Once declared as a friend function, the function is able to access the private and the protected members of these classes.
Some Characteristics of Friend Function in C++ :
1) The function is not in the ‘scope’ of the class to which it has been declared a friend.
2) Friend functionality is not restricted to only one class
3) Friend functions can be a member of a class or a function that is declared outside the scope of class.
4) It cannot be invoked using the object as it is not in the scope of that class.
5) We can invoke it like any normal function of the class.


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
How do you remove whitespace from the start of a string?
Choose another skill to practice
Similar interview experiences
SDE - 1
4 rounds | 6 problems
Interviewed by Samsung
Selected 1921 views
0 comments
0 upvotes
SDE - 1
3 rounds | 4 problems
Interviewed by Samsung
Selected 1221 views
0 comments
0 upvotes
SDE - 1
3 rounds | 6 problems
Interviewed by Samsung
Rejected
2229 views
0 comments
0 upvotes
SDE - 1
3 rounds | 5 problems
Interviewed by Samsung
Rejected
419 views
0 comments
0 upvotes
Companies with similar interview experiences
SDE - 1
5 rounds | 12 problems
Interviewed by Amazon
 Selected
Selected 115097 views
24 comments
0 upvotes
SDE - 1
4 rounds | 5 problems
Interviewed by Microsoft
Selected 58237 views
5 comments
0 upvotes
SDE - 1
3 rounds | 7 problems
Interviewed by Amazon
 Selected
Selected 35147 views
7 comments
0 upvotes