


























Sprinklr interview experience Real time questions & tips from candidates to crack your interview
SDE - 1
Sprinklr
2 rounds | 5 Coding
problems

Rejected
Interview preparation journey

Preparation
Duration: 3 months
Topics: Data Structures, Pointers, OOPS, System Design, Algorithms, Dynamic Programming
Tip 1 : Regarding DSA preparation, I have a theory. 20 percent of the questions will be asked in 80 percent of the interview and 80 percent of the questions will be asked in 20 percent of the interviews. In short, some questions have a very high chance of coming up during the interviews and some have very low chance. We should focus more on the questions that have more chance of coming up in the interview. You can find these questions on Striver SDE Sheet, InterviewBit, Leetcode 100 most liked, Leetcode 100 most important.
Tip 2 : Try to find patterns in the questions. Group them according to a pattern for better understanding. Make notes in Excel, word or hand written and revise them.
Tip 3 : Try to solve the questions that have more chance of coming up in the interview with many different approaches.
Application process
Where: Campus
Eligibility: Above 7 CGPA
Tip 1 : Make Sure that your resume is simple and also try to fit all the information in only one page.
Tip 2 : Have at least 2 projects with the latest technologies,Github link of projects should be provided

Interview rounds
01
Round
Easy
Video Call
Duration45 mins
Interview date5 Aug 2022
Coding problem3
1. Anagram Pairs
Moderate
30m average time
60% success

0/80
Asked in companies

You are given two strings 'str1' and 'str1'.
You have to tell whether these strings form an anagram pair or not.
The strings form an anagram pair if the letters of one string can be rearranged to form another string.
Pre-requisites:
Anagrams are defined as words or names that can be formed by rearranging the letters of another word. Such as "spar" can be formed by rearranging letters of "rasp". Hence, "spar" and "rasp" are anagrams.
Other examples include:
'triangle' and 'integral'
'listen' and 'silent'
Note:
Since it is a binary problem, there is no partial marking. Marks will only be awarded if you get all the test cases correct.
Problem approach
I simply used hashing to solve this problem by checking the frequency of characters in both strings.
2. DBMS Questions
Explain different levels of data abstraction in a DBMS.
Problem approach
Physical Level: it is the lowest level and is managed by DBMS. This level consists of data storage descriptions and the details of this level are typically hidden from system admins, developers, and users.
Conceptual or Logical level: it is the level on which developers and system admins work and it determines what data is stored in the database and what is the relationship between the data points.
External or View level: it is the level that describes only part of the database and hides the details of the table schema and its physical storage from the users.
3. DBMS Questions
Explain the difference between intension and extension in a database.
Problem approach
Intension: Intension or popularly known as database schema is used to define the description of the database and is specified during the design of the database and mostly remains unchanged.
Extension: Extension on the other hand is the measure of the number of tuples present in the database at any given point in time. The extension of a database is also referred to as the snapshot of the database and its value keeps changing as and when the tuples are created, updated, or destroyed in a database
02
Round
Easy
Video Call
Duration45 mins
Interview date5 Aug 2022
Coding problem2
1. Flatten Binary Tree to Linked List
Moderate
25m average time
70% success
0/80
Asked in companies
You are given a binary tree consisting of 'n' nodes.
Convert the given binary tree into a linked list where the linked list nodes follow the same order as the pre-order traversal of the given binary tree.
Use the right pointer of the binary tree as the “next” pointer for the linked list and set the left pointer to NULL.
Use these nodes only. Do not create extra nodes.
Example :
Input: Let the binary be as shown in the figure:
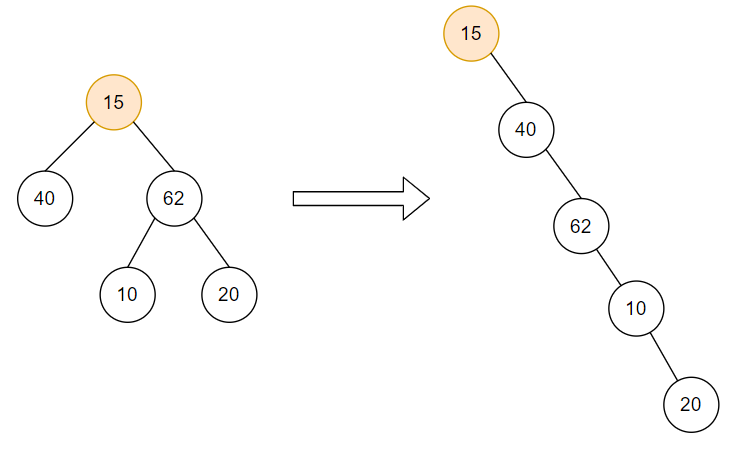
Output: Linked List: 15 -> 40 -> 62 -> 10 -> 20 -> NULL
Explanation: As shown in the figure, the right child of every node points to the next node, while the left node points to null.
Also, the nodes are in the same order as the pre-order traversal of the binary tree.
Problem approach
You are given a binary tree consisting of integer values. Your task is to convert the given binary tree into a linked list where the nodes of the linked list follow the same order as the pre-order traversal of the given binary tree.
2. Implementation: Hashmap
Easy
30m average time
90% success
0/40
Asked in companies

Design a data structure that stores a mapping of a key to a given value and supports the following operations in constant time.
1. INSERT(key, value): Inserts an integer value to the data structure against a string type key if not already present. If already present, it updates the value of the key with the new one. This function will not return anything.
2. DELETE(key): Removes the key from the data structure if present. It doesn't return anything.
3. SEARCH(key): It searches for the key in the data structure. In case it is present, return true. Otherwise, return false.
4. GET(key): It returns the integer value stored against the given key. If the key is not present, return -1.
5. GET_SIZE(): It returns an integer value denoting the size of the data structure.
6. IS_EMPTY(): It returns a boolean value, denoting whether the data structure is empty or not.
Note :
1. Key is always a string value.
2. Value can never be -1.
Operations Performed :
First(Denoted by integer value 1): Insertion to the Data Structure. It is done in a pair of (key, value).
Second(Denoted by integer value 2): Deletion of a key from the Data Structure.
Third(Denoted by integer value 3): Search a given key in the Data Structure.
Fourth(Denoted by integer value 4): Retrieve the value for a given key from the Data Structure.
Fifth(Denoted by integer value 5): Retrieve the size of the Data Structure.
Sixth(Denoted by integer value 6): Retrieve whether the Data Structure is empty or not.
Problem approach
I implemented hashmap using hashing with chaining technique in C++ and interviewer further extended discussion on hashing with chaining.


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
Which collection class forbids duplicates?
Choose another skill to practice
Similar interview experiences
SDE - 1
2 rounds | 4 problems
Interviewed by Sprinklr
Rejected
1461 views
0 comments
0 upvotes
SDE - 1
2 rounds | 4 problems
Interviewed by Sprinklr
Rejected
889 views
0 comments
0 upvotes
SDE - 1
2 rounds | 4 problems
Interviewed by Sprinklr
Rejected
905 views
0 comments
0 upvotes
SDE - 1
3 rounds | 14 problems
Interviewed by Sprinklr
Rejected
4002 views
0 comments
0 upvotes
Companies with similar interview experiences
SDE - 1
5 rounds | 12 problems
Interviewed by Amazon

 Selected
Selected 116551 views
24 comments
0 upvotes
SDE - 1
4 rounds | 5 problems
Interviewed by Microsoft
Selected 59304 views
5 comments
0 upvotes
SDE - 1
3 rounds | 7 problems
Interviewed by Amazon
 Selected
Selected 35700 views
7 comments
0 upvotes