


























Zeta interview experience Real time questions & tips from candidates to crack your interview
SDE - 1
Zeta
2 rounds | 6 Coding
problems

Rejected
Interview preparation journey

Journey
My journey toward applying for a Software Developer role at Zeta has been both enriching and inspiring. It all began with a strong foundation in data structures and algorithms (DSA). I firmly believe that mastering these fundamental concepts is key to solving real-world problems, which is why I dedicated significant time to honing them.
While preparing, I focused on understanding various data structures and their practical applications. This knowledge not only helped me tackle complex coding problems but also gave me the confidence to approach challenges logically and systematically.
Another crucial part of my preparation was developing strong problem-solving skills through consistent practice. Alongside DSA, I emphasized full-stack development, including backend technologies (databases, APIs, and server-side programming) and frontend frameworks (React.js, HTML, CSS, and JavaScript). I also delved into system design, scalability, and performance optimization to strengthen my overall skill set.
I discovered the opportunity at Zeta through college placements, applied, and was shortlisted for the interview. The selection process involved two rounds. This experience has been instrumental in shaping my technical journey and preparing me for future opportunities in full-stack development.
Application story
I participated in Zeta’s on-campus recruitment drive, where the shortlisting process was based on a set of coding challenges. I successfully solved three coding questions, which secured my spot for the next stages of the selection process. Advancing through the drive allowed me to demonstrate my problem-solving abilities and gain exposure to industry-level technical assessments. The experience not only boosted my confidence but also highlighted key areas where I could further strengthen my technical and interview preparation.
Why selected/rejected for the role?
I believe I was not selected for the role at Zeta because my profile was more inclined towards the AI/ML side rather than being fully focused on backend development with Node.js. While I had worked on backend projects, they were largely integrated with AI-driven solutions, which may not have fully aligned with the company’s requirement for a candidate with a stronger emphasis on core backend development. This experience underscored the importance of aligning my portfolio and preparing more closely with the specific technical expectations of the role to present a more focused skill set.
Preparation
Duration: 1 month
Topics: Arrays, String, Sliding Window, OOPS, Trees, Graphs, LinkedList, HashMap, NodeJS, JavaScript
Tip 1: Understand problem logic, not just solutions (arrays, strings, sliding window).
Tip 2: Practice trees, linked lists, hashmap by coding them from scratch.
Tip 3: Build projects using Node.js, JavaScript, and Flask for hands-on backend skills.
Application process
Where: Campus
Eligibility: Above 7.5 CGPA, (Salary Package: 16 LPA)
Tip 1: Be sure to know your projects thoroughly and be honest about them.
Tip 2: Include relevant projects that effectively showcase your skills and experience.

Interview rounds
01
Round
Hard
Online Coding Interview
Duration90 minutes
Interview date20 Jan 2025
Coding problem3
1. Redundant Network Design
Ninja

0/200
Asked in company
You are given an undirected, weighted graph representing a network of servers, with 'V' servers and a list of potential connections. Each connection [u, v, w] represents a cable that can be laid between server u and server v with a cost of w.
Your primary goal is to build the cheapest possible network that connects all servers. This is known as the Minimum Spanning Tree (MST).
However, for reliability, you also need to find the second-best MST. The second-best MST is a spanning tree whose total cost is the next-smallest possible value that is strictly greater than the cost of the first MST. It is known that any second-best MST can be formed from an MST by swapping one of its edges with one of the graph's edges not in the MST.
Your task is to calculate and return the total cost of the second-best MST.
Problem approach
Step 1: I first thought of just using Kruskal’s algorithm to find MST. That gave me the minimum cost tree.
Step 2: The interviewer asked about the second MST, so I realized I need to explore alternative edges.
Step 3: My approach would be:
Build MST using Kruskal’s.
For each non-MST edge, try adding it → this creates a cycle.
Remove the maximum weight edge in that cycle → compute new cost.
Keep track of the minimum among these costs greater than MST.
Step 4: Due to time, I wasn’t able to code the full solution, but I knew the approach.
2. Diameter Of Binary Tree
Easy
10m average time
90% success
0/40
Asked in companies
You are given a Binary Tree.
Return the length of the diameter of the tree.
Note :
The diameter of a binary tree is the length of the longest path between any two end nodes in a tree.
The number of edges between two nodes represents the length of the path between them.
Example :
Input: Consider the given binary tree:
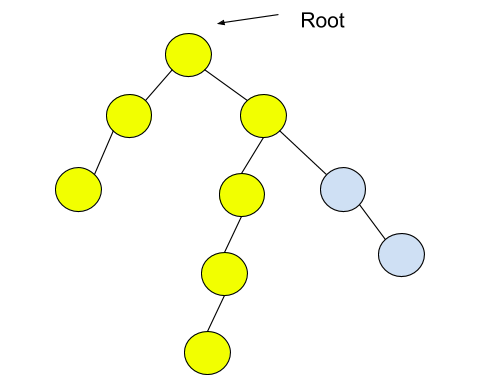
Output: 6
Explanation:
Nodes in the diameter are highlighted. The length of the diameter, i.e., the path length, is 6.
Problem approach
Step 1: At first, I tried brute force → calculate height for every node’s left & right, then take max. This was O(n²).
Step 2: Interviewer asked me to optimize, so I modified DFS:
At each node, return height.
While doing so, also update a global max for leftHeight + rightHeight.
Step 3: This gave me an O(n) solution.
Result: Interviewer was happy with the optimized approach.
3. DAG Path Counter
Hard
0/120
Asked in company
You are given a Directed Acyclic Graph (DAG) with 'V' vertices, a list of 'E' directed edges, a source vertex src, and a destination vertex dest.
Your task is to count the total number of distinct paths from the src vertex to the dest vertex.
Problem approach
Step 1: I first thought of brute force DFS to count all paths, but realized it could explode in complexity.
Step 2: Interviewer hinted about DP with Topological Sort. The idea is:
Do a topological ordering.
Use DP: dp[v] = sum(dp[u]) for all edges u→v.
Step 3: I wasn’t able to implement within time, but I knew the direction.
02
Round
Hard
Face to Face
Duration60 minutes
Interview date30 Jan 2025
Coding problem3
1. System Design
Suppose you are working at Twitter and you want to fetch tweets within a certain proximity (say 5 km radius) of a given location. How would you approach solving this problem?
Problem approach
Tip 1: I first thought of storing tweets with their latitude/longitude values in a hashmap keyed by location buckets. This way, retrieval within an area becomes easier.
Tip 2: Then I realized for accurate proximity search, we’d need to use spatial indexing instead of plain hashmap. I mentioned data structures like Quadtrees or Geohash for dividing locations into grids.
Tip 3: To further optimize, I suggested that we could use a database with geospatial indexing (like PostgreSQL with PostGIS or MongoDB’s geo-queries). These can efficiently query points within a given radius using something like a Haversine formula for distance.
Tip 4: For scalability (since Twitter has huge data), I added that tweets could be partitioned and indexed geographically, so the system queries only relevant partitions instead of scanning all tweets.
2. Vertical Order Traversal of Binary Tree
Hard
35m average time
80% success
0/120
Asked in company
You are given a binary tree having 'n' nodes.
Vertical order traversal is a traversal in which we traverse the nodes from left to right and then from top to bottom.
In the case of multiple nodes in the same place, we traverse them in the non-decreasing order of their value.
Formally, assume for any node at position (x, y), its left child will be at the position (x - 1, y + 1), and the right child at position (x + 1, y + 1). Assume the root is at coordinate (0, 0).
Run vertical lines from 'x' = -infinity to 'x' = +infinity. Now whenever this vertical line touches some nodes, we need to add those values of the nodes in order starting from top to bottom with the decreasing 'y' coordinates.
If multiple nodes have the same 'x' and 'y' coordinates, they will be accessed in non-decreasing order of values.
Find the vertical order traversal of the given tree.
Example :
Input: Let the binary tree be:
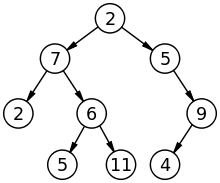
Output: [2, 7, 5, 2, 6, 5, 4, 11, 9]
Explanation: The nodes having the same 'x' coordinates are:
'x' = -2 : [2]
'x' = -1 : [7, 5]
'x' = 0 : [2, 6]
'x' = 1 : [5, 4, 11]
'x' = 2 : [9]
Here 4 and 11 have the same 'x' and 'y' coordinates. So they are considered in non-decreasing order.
Problem approach
Step 1: At first, I thought of doing a simple BFS/DFS and grouping by depth, but that wouldn’t separate vertical columns.
Step 2: Then I realized I need to map each node with its horizontal distance (column index).
Left child → col - 1
Right child → col + 1
Step 3: I used a BFS traversal with a queue, where each entry stores (node, row, col).
Maintain a hashmap → col → [(row, value)].
After traversal, sort each column first by row, then by value.
Step 4: Finally, I collected all columns in ascending order of col index and built the output list.
3. System Design
Imagine you are building a notification service like Twitter. When a user sends a message, it should be delivered instantly to all devices of the receiver. How would you design this system to handle millions of users concurrently?
Problem approach
Tip 1: My first thought was a simple client-server model, where the server stores the message and pushes it to the receiver. But this wouldn’t scale well with millions of concurrent connections.
Tip 2: Then I suggested using WebSockets to maintain a persistent connection between server and client. This allows real-time push instead of polling.
Tip 3: To ensure scalability, I proposed:
Use a message queue (Kafka/RabbitMQ) to handle spikes in message traffic.
Maintain user sessions in a distributed cache (like Redis) to quickly identify active devices.
Use load balancers to distribute connections across multiple servers.
Tip 4: For reliability:
If the receiver is offline, messages should be stored in a persistent DB (like Cassandra or DynamoDB).
Once the user comes online, the system pushes all pending messages.


Here's your problem of the day 
Solving this problem will increase your chance to get selected in this company
Skill covered: Programming
Which collection class forbids duplicates?
Choose another skill to practice
Similar interview experiences
SDE - 1
3 rounds | 7 problems
Interviewed by OYO
 Selected
Selected 5572 views
0 comments
0 upvotes
SDE - 1
2 rounds | 5 problems
Interviewed by Meesho
Rejected
6978 views
0 comments
0 upvotes
SDE - 1
3 rounds | 9 problems
Interviewed by Salesforce
 Selected
Selected 4114 views
0 comments
0 upvotes
SDE - 1
3 rounds | 9 problems
Interviewed by Zeta
Selected 3532 views
0 comments
0 upvotes
Companies with similar interview experiences
SDE - 1
5 rounds | 12 problems
Interviewed by Amazon
 Selected
Selected 116551 views
24 comments
0 upvotes
SDE - 1
4 rounds | 5 problems
Interviewed by Microsoft
Selected 59304 views
5 comments
0 upvotes
SDE - 1
3 rounds | 7 problems
Interviewed by Amazon
 Selected
Selected 35700 views
7 comments
0 upvotes