
























Problem
Submissions
Hints & solutions
Discuss
City And Bridges
Moderate

0/80
Average time to solve is 50m
Contributed by
2 upvotes
Asked in companies

Problem statement
Ninja got a map in his hand with ‘N’ cities numbered 0 to ‘N’, connected with bridges. He asks his sister to delete some cities from the map.
He will ask his sister a ‘Q’ query. Each query is denoted by an integer ‘X’, meaning that he will delete the city ‘X’. He wants to see if the new map obtained after deleting the city node will have more connected components than the previous map.
He wants to build the program for the queries given by his sister for the above condition.
Ninja knows that you are a very good programmer and can help him in writing the code for the above. Help Ninja!
Note:
A connected component in the map is the maximum subset of cities that are connected i.e we can go from one city to any other in that subset.
Detailed explanation ( Input/output format, Notes, Images )
Input format :
The first line of input contains an integer ‘T’, which denotes the number of test cases. Then each test case follows.
The first line of each test case contains two separated integers ‘N’ and ‘M’ denoting ‘N’ cities and ‘M’ bridges.
Each of the next ‘M’ lines contains 2 integers ‘A’ and ‘B’, meaning that there is an edge between city A and city B.
The next line contains a single integer ‘Q’ denoting the number of queries
The next line contains ‘Q’ space-separated integers denoting the value of the nodes to be deleted.
For each query, if deleting the city on the map results in more number of connected components then print ‘Yes’, else print ‘No’.
Output for each query will be printed separated by a single space.
Constraints:
1 <= T <= 5
1 <= N <= 10^5
1 <= M <= 10^5
0 <= A <= N
1 <= B <= N
1 <= X <= N
Time Limit : 1 sec.
Sample Input 1 :
2
5 5
0 1
1 2
2 3
3 4
2 4
1
0
5 5
0 1
1 2
2 3
3 4
2 4
1
1
Sample Output 1 :
No
Yes
Explanation for sample test case 1:
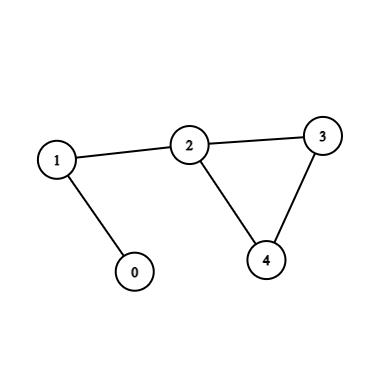
Test Case 1 :
If we remove the node with value 0 from the graph, The graph will have only 1 connected component with nodes 1, 2, 3, 4 which is not more than the connected components in the graph before deleting the node. Therefore the output will be “No”.
Test Case 2:
If we remove node with value 1 from the graph, the graph will have 2 connected components i.e one with 0 and one with 2, 3, 4. which is more than the connected components in the graph before deleting the node. Therefore the output will be “Yes” .
Sample Input 2 :
2
5 5
1 2
2 3
3 4
4 5
3 5
2
3 5
5 5
1 2
2 3
3 4
4 5
3 5
1
4
Sample Output 2 :
Yes No
No
Hint
Hint 1
Try to think of Depth First Search.
Approaches (1)
Approach 1
Depth First Search :
The idea is to find the articulation nodes in the graph. The articulation node is the node if removing it along with the edges will disconnect the graph.
For eg.

In the above figure, nodes with values 2 and 3 are Articulation nodes. As removing them along with edges will disconnect the graph.
After removing the node with value 2, the graph will look like

After removing the node with value 3, the graph will look like

The idea is to use DFS (Depth First Search). In DFS, we follow vertices in tree form called DFS tree. In the DFS tree, a vertex ‘u’ is the parent of another vertex ‘v’, if ‘v’ is discovered by ‘u’. In a DFS tree, a vertex ‘u’ is an articulation point if one of the following two conditions is true.
1) ‘u’ is the root of the DFS tree and it has at least two children.
2) ‘u’ is not the root of the DFS tree and it has a child ‘v’ such that no vertex in the subtree rooted with ‘v’ has a back edge to one of the ancestors (in DFS tree) of ‘u’.
We do a DFS traversal of a given graph to find out Articulation Points. In DFS traversal, we maintain a parent[] array where parent[u] stores the parent of the vertex ‘u’. For every vertex, count children. If the currently visited vertex ‘u’ is root (parent[u] is -1) and has more than two children, then store it in an unordered_set.
For the second case. We maintain an array discovery[] to store the discovery time of vertices. For every node ‘u’, we need to find out the earliest visited vertex (the vertex with minimum discovery time) that can be reached from the subtree rooted with ‘u’. So we maintain an additional array low[] for that.
Approach :
- First make a recursive function, say ‘articulation()’ to find articulation points using DFS taking ‘arr’, current node, say ‘u’ and parent, say ‘par’ as arguments.
- Initialize variable ‘time’ to 0 globally.
- Initialize count of children in variable ‘children’ with 0.
- Mark the current node as visited.
- Intitialise ‘discovery[]’ and ‘low[]’ as discovery[u] = time, low[u] = time and increase time.
- Make an iteration to traverse the adjacency list for ‘u’ vertex.
- Store the adjacent node of ‘u’ in a variable, say ‘adjacent’
- If ‘adjacent’ vertex is not visited then:
- Increment the variable ‘children’ with a value of 1.
- Store ‘u’ in par[adjacent].
- Call the function ‘articulation()’ recursively making ‘adjacent’ as ‘u’, as an argument for the DFS traversal.
- Check if the subtree rooted with ‘adjacent’ has any connection to ancestors of ‘u’
- low[u] = min(low[u], low[adjacent])
- For condition 1 of articulation - Check if the parent of ‘u’ is -1 i.e. root of the graph and has more than 1 children then insert the value of ‘u’ in unordered_set ‘art’.
- For condition 2 of articulation - Check if ‘u’ is not the parent node and the low value of one of its children is more than the discovery value of ‘u’ then insert the value of ‘u’ in unordered_set ‘art’.
- Else, update the low value of ‘u’ for parent function calls.
- Low[u] = min(low[u], discovery[adjacent]).
- In the given function, First, initialize an array ‘ans’ in which our required answer gets stored.
- iterate throughout the ‘query’ array with the help of iterator pointer ‘i’.
- If query[i] is present in the set ‘art’ then make the value ans[i] as true.
- Else make the value ans[i] as false.
- Return the ‘ans’ array to the given function.
Time Complexity
O(N + M), where ‘N’ is the number of cities and ‘M’ is the number of bridges in the graph.
As we are simply implementing Depth First Search for the above algorithm which takes O(N + M) time complexity for adjacency list representation.
Space Complexity
O(N), where ‘N’ is the number of cities in the graph.
As we are taking an auxiliary space to store the count of discovery time and low time of size = number of vertices. Therefore overall space complexity will be O(N).
Code Solution
(100% EXP penalty)
City And Bridges
C++ (g++ 5.4)
Console