
























Problem
Submissions
Hints & solutions
Discuss
Same Label Nodes
Easy

0/40
Average time to solve is 15m

Contributed by
2 upvotes
Asked in companies
Problem statement
You are given a tree having ‘N’ nodes rooted at node 0. Each node has a label. For every node in the tree, your task is to determine the total number of nodes in the current node’s subtree, having the same label as the current node.
Note:
1. All the edges in the given tree are bidirectional.
2. The tree does not contain any cycle or self-loop.
3. A label can only be any lowercase English letter.
Detailed explanation ( Input/output format, Notes, Images )
Input Format:
The first line contains an integer ‘T’, which denotes the number of test cases to be run. Then, the ‘T’ test cases follow.
The first line of each test case contains an integer, ‘N’, denoting the total number of nodes in the tree.
The second line contains a string having ‘N’ characters, where for every, ‘i’ from 0 to ‘N-1’, the ‘i-th’ character denotes the label of the ‘i-th’ node.
Then 'N-1' lines follow. Each line contains two space-separated integers, denoting an edge between these two integers.
For each test case, return an array of size ‘N’, where the ‘i-th’ integer denotes the total number of nodes in the subtree of the ‘(i-1)-th’ node, having the same label as the ‘(i-1)-th’ node.
You do not need to print anything. It has already been taken care of. Just implement the given function.
Constraints:
1 <= T <= 5
1 <= N <= 10^4
Time Limit: 1sec
Sample Input 1:
1
3
aba
0 1
0 2
Sample Output 1:
2 1 1
Explanation for sample input 1:
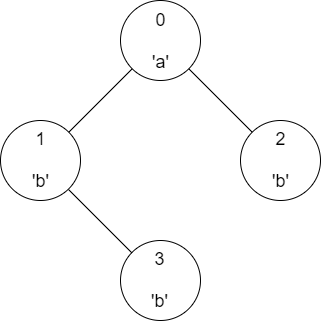
In the first test case, there are just two nodes in the subtree of node 0 that has the same label as node 0 and that is node 0 and node 2. In the subtree of node 1, there is just one such node and it is node 1 itself. Similarly, for node 2, there is again just one such node. So we print 2 1 1.
Sample Input 2:
1
4
abbb
0 1
0 2
1 3
Sample Output 2:
1 2 1 1
Explanation for sample input 2:
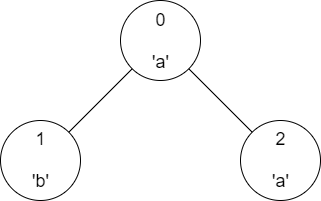
In the second test case, there is just one node that has the same label as node 0 and that is node 0 itself. In the subtree of node 1, there are two nodes having the same label as node 1, these nodes are node 1 and node 3. For node 2, there is just one such node and it is node 2 itself. Similarly, for node 3, there is again just one such node. So we print 1 2 1 1.
Hint
Hint 1
Think of a DFS approach.
Approaches (1)
Approach 1
Using Depth First Search
The approach is to use Depth First Search. We can observe that the number of nodes in the subtree of the current node having the same label as the current node is equal to the total sum of the number of such nodes in each of the current node’s children. We can add 1 to this sum as the current node is also a part of the subtree. For each node, we can maintain a list of the frequencies of each character in the subtree of that node. We can avoid repetitions by keeping a track of all the nodes that we have already VISITED.
Steps
- Initialize a vector, say SAME_LABEL_NODES to store the required values for each node. Initially, all the values must be 0.
- Initialize a vector of adjacency lists, say TREE for all nodes.
- Run a loop for i = 0 to i = EDGES.size and:
- Declare NODE1 = EDGES[i][0] and NODE2 = EDGES[i][1].
- Push NODE1 in TREE[NODE2] and push NODE2 in TREE[NODE1].
- Initialize a boolean vector, say VISITED to keep track of whether a node has already been VISITED or not. Initially, all values must be false.
- Call the function COUNT_FREQUENCIES(TREE, LABELS, 0, VISITED, SAME_LABEL_NODES). For every node, this function will count frequencies of each letter in the subtree of this node and store all the required values in SAME_LABEL_NODES.
- Finally, we can return SAME_LABEL_NODES.
vector<int> COUNT_FREQUENCIES(TREE, LABELS, CURR_NODE, VISITED, SAME_LABEL_NODES)
- Make VISITED[CURR_NODE] = true.
- Create a vector, say CURR_NODE_FREQ to store frequencies in the subtree of CURR_NODE.
- Run a loop for i=0 to i=TREE[CURR_NODE].size and do:
- Declare CHILDE_NODE = TREE[CURR_NODE][i].
- If CHILDE_NODE has already been VISITED, continue.
- Create a vector, say CHILDE_NODE_FREQ to store the result of COUNT_FREQUENCIES(TREE, LABELS, CHILDE_NODE, VISITED, SAME_LABEL_NODES).
- Now, for every letter, add its frequency in the CHILDE_NODE to the corresponding frequency in the CURR_NODE_FREQ. Formally, for every k=0 to k=2 make CURR_NODE_FREQ[k] += CHILDE_NODE_FREQ[k].
- Increase the frequency of the current node’s label in CURR_NODE_FREQ by 1.
- Since the required value for the current node is equal to the frequency of this label in the subtree of the current node, make SAME_LABEL_NODES[CURR_NODE] = CURR_NODE_FREQ[LABELS[CURR_NODE] - 'a'].
- Return CURR_NODE_FREQ.
Time Complexity
O(N), where ‘N’ is the number of nodes in the tree.
We are visiting each node just once and calculating the frequencies using the frequencies for the child nodes so this takes constant time. Since there are ‘N’ nodes, we require O(N) time.
Space Complexity
O(N), where 'N' is the number of nodes in the tree.
We need extra space to maintain the list of frequencies of characters for every node. Since there are ‘N’ nodes, we need O(N) extra space.
Code Solution
(100% EXP penalty)
Same Label Nodes
C++ (g++ 5.4)
Console