


























If A = “aab”, B = “abc”, C = “aaabbc”
Here C is an interleaving string of A and B. Because C contains all the characters of A and B and the order of all these characters is also the same in all three strings.
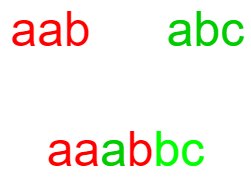
If A = “abc”, B = “def”, C = “abcdefg”
Here C is not an interleaving string of A and B as neither A nor B contains the character ‘g’.
The first line contains an integer 'T' which denotes the number of test cases or queries to be run. Then, the T test cases follow.
The first and only line of each test case contains three strings A, B, and C each separated by a single space.
For each test, print True, if C is an interleaving string of A and B, otherwise print False
Output for each test case will be printed in a separate line.
You do not need to print anything; it has already been taken care of. Just implement the given function.
1 <= T <= 100
1 <= |A|, |B| <= 1000
1 <= |C| <= 2000
where |A|, |B|, |C| denotes the length of string A, B and C respectively.
All the characters of the strings A, B, and C contain lowercase English letters only.
Time limit: 1 second
To solve this problem, let us solve a smaller problem first. Let’s assume that the length of the string A and B is one and the length of the string C is two. Now to check whether C is formed by interleaving A and B or not, we consider the last character of string C, and if this character matches neither with the character of the string A nor with the character of string B, then we return false. But if it matches with any of the characters either from A or from B, we check the same for the other character in C. So, let's further expand this idea, for bigger problems. So, suppose the last character of C, matches with either the last character of A or B. In that case, we check recursively for the second last element and then the third last element and so on, until we finally reach the base case when all the strings eventually become empty.
bool isInterleaveUtil( A, B, C, n1, n2, n3):
In the previous approach, the algorithm recursively calculates and compares every possible A and B character with C, which has many overlapping subproblems. i.e. a recursive function computes the same sub-problems again and again. So we can use memoization to overcome the overlapping subproblems. To reiterate, memoization is when we store the results of all previously solved subproblems and return whether C is formed by interleaving A and B or not, from the dp[i][j] if we encounter the problem that has already been solved.
Since there are three states those are changing in the recursive function, but the change in the string C is just a result of a change in string A and string B, so we use the 2-dimensional array dp[][] to store all the subproblems where dp[i][j] will store whether C is formed by interleaving A from 0 to i th character and B from 0 to j th character or not.
bool isInterleaveUtil( A, B, C, n1, n2, n3, dp):
The idea is to use a bottom-up dynamic programming approach instead of a memoization approach. In this, we use the recurrence relation of memoization approach as dp[i][j] = (dp[i-1][j] && A[i-1] == C[i+j-1]) || (dp[i][j-1] && B[j-1] == C[i+j-1]); where i is in [0, N] and j is in [0, M], where N and M is the length of string A and string B respectively.
The space complexity for the last two approaches is O(N*M), however, it can be improved further to O(min(M,N)), if we use 1D dp array. The approach is the same as the previous approach except for the fact that here we use 1D dp array to store the results of the prefixes of the strings processed so far. We update dp[i] by using the value of dp[i-1] and the previous value of dp[i].

