
The job search landscape has undergone a significant transformation in recent years. Gone are the days of simply sending out paper resumes and waiting for a response. Today, Applicant Tracking…

Latest Data Science Interview Questions and How to Answer Them
14 min read
18,040 views
3 likes
Establishing a foothold as a fresher might seem like something of a challenge in the fast-paced field of data science, where creativity and technology meet. The field is rich with potential, but to take advantage of it, one has to be able to negotiate the complex web of data science interviews effectively. As organizations increasingly recognize the value of data-driven decision-making, the demand for skilled data scientists has surged, making the interview process more rigorous and competitive.
- Interview Questions for Data Scientist Freshers PDF
- Advanced Level Data Science Interview Questions PDF
- Data Analytics Interview Questions for Freshers PDF
- Statistics in Data Science Interview Questions PDF
- Machine Learning in Data Science Interview Questions for Freshers PDF
This article serves as a guiding beacon for aspiring data scientists, providing an in-depth exploration of the intricacies involved in the interview process. The aim is not just to pass interviews but to empower freshers with a profound understanding of the field’s core concepts, and technical challenges.
Table of Content
Data Science Interview Questions for Freshers
With this preparation, freshers can confidently embark on their journey of how to become a data scientist and be ready to contribute meaningfully to the ever-expanding realm of data-driven innovation.
What is Data Science?
Data Science is an interdisciplinary field that utilizes scientific methods, algorithms, and systems for extracting insights from structured and unstructured data. It involves data collection, preprocessing, exploratory data analysis (EDA), model building using machine learning algorithms, and the interpretation and communication of findings.
What is the difference between supervised and unsupervised learning?
Supervised learning involves training a model on labeled data, where the algorithm learns to map input to output. In contrast, unsupervised learning deals with unlabeled data, focusing on finding patterns and relationships without predefined output labels.
What is the difference between Data Science and Data Analytics?
Data Science encompasses a broader spectrum, involving the entire data lifecycle from collection to interpretation, often incorporating machine learning. Data Analytics analyzes historical data to uncover trends and make informed business decisions.
What is the difference between variance and bias?
Variance represents the model’s sensitivity to fluctuations in the training data, while bias measures the model’s tendency to deviate from the actual values. Striking a balance between variance and bias is crucial for optimal model performance.
What is overfitting, and how can you avoid it?
Overfitting occurs when a model learns the training data too well, capturing noise and hindering its ability to generalize to new data. Regularization techniques, cross-validation, and using simpler models can help mitigate overfitting.
What is the curse of dimensionality?
The curse of dimensionality refers to the challenges and increased computational complexity that arise when dealing with high-dimensional data. As the number of features increases, data becomes sparse, and traditional algorithms may struggle. Dimensionality reduction techniques can address this issue.
What is regularization, and why is it useful?
Regularization is a technique that introduces a penalty term to the loss function during model training, discouraging overly complex models. It helps prevent overfitting and enhances the model’s ability to generalize to unseen data.
What is the difference between L1 and L2 regularization?
L1 regularization, or Lasso, adds the absolute values of coefficients as a penalty, encouraging sparsity. L2 regularization, or Ridge, adds the squared values of coefficients, preventing large weights. Both techniques contribute to preventing overfitting.
What is the difference between a generative and discriminative model?
A generative model learns the joint probability distribution of the input features and labels, allowing it to generate new samples. A discriminative model focuses on learning the decision boundary between different classes, aiding in classification tasks.
What is cross-validation, and why is it important?
Cross-validation is a model evaluation technique that involves partitioning the dataset into subsets for training and testing iteratively. It provides a more robust estimate of a model’s performance, reducing the risk of overfitting to a specific dataset and improving generalization to unseen data.
Advanced Level Data Science Interview Questions
Landing your dream data science job often hinges on acing the interview. While basic concepts are crucial, showcasing your ability to tackle complex challenges is what truly sets you apart. Here are 10 advanced data science interview questions that will test your mettle and leave a lasting impression:
Explain the bias-variance tradeoff and its implications for model selection.
The bias-variance tradeoff is a crucial consideration in model selection. It involves finding the right balance between a model’s bias (simplistic assumptions) and variance (sensitivity to training data). Optimal performance is achieved by selecting a model complexity that minimizes both bias and variance, avoiding underfitting or overfitting.
Discuss the challenges and potential solutions for handling imbalanced datasets.
Imbalanced datasets pose challenges in machine learning, as models may favor the majority class. Techniques such as resampling (oversampling or undersampling), using different evaluation metrics (precision, recall), and employing advanced algorithms like ensemble methods can address imbalanced data challenges.
Describe the process of building and evaluating a recommender system.
Building a recommender system involves data collection, preprocessing, selecting a suitable algorithm (collaborative filtering or content-based), training the model, and evaluating its performance using metrics like precision, recall, and Mean Average Precision (MAP).
Explain the concept of dimensionality reduction and its applications in data analysis.
Dimensionality reduction involves reducing the number of features in a dataset while preserving its essential information. Techniques like Principal Component Analysis (PCA) and t-distributed Stochastic Neighbor Embedding (t-SNE) are used to visualize high-dimensional data and improve model efficiency.
Discuss the ethical considerations involved in using machine learning models.
Ethical considerations in machine learning include bias in training data, transparency in decision-making processes, privacy concerns, and potential social impacts. Implementing fairness-aware algorithms, diverse and representative datasets, and clear model documentation are crucial in addressing ethical challenges.
Explain the concept of streaming analytics and its applications in real-time data processing.
Streaming analytics involves processing and analyzing data in real time as it is generated. Applications include real-time fraud detection, monitoring IoT devices, and dynamic pricing strategies. Technologies like Apache Kafka and Apache Flink are commonly used in streaming analytics.
Describe the challenges and potential solutions for deploying machine learning models in production.
Deploying machine learning models in production poses challenges such as version control, scalability, and model monitoring. Solutions involve containerization (e.g., Docker), model versioning, and implementing robust monitoring systems to track model performance over time.
Explain the concept of deep learning and its applications in various domains.
Deep learning involves training neural networks with multiple layers to automatically learn hierarchical representations of data. Applications include image recognition, natural language processing, and speech recognition. Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) are common architectures in deep learning.
Describe the concept of transfer learning and its advantages in machine learning.
Transfer learning involves leveraging knowledge gained from one task to improve the performance of a related task. Advantages include reduced training time, improved model generalization, and enhanced performance on tasks with limited labeled data.
How would you approach a data science problem with limited data or resources?
When faced with limited data or resources, strategies include leveraging transfer learning, using data augmentation techniques, exploring pre-trained models, and focusing on feature engineering. Additionally, employing simpler models and implementing rigorous cross-validation can optimize model performance with constrained resources.
Data Analytics Interview Questions for Freshers
Check out these most frequently asked Data Analytics Questions during the interview process.
What is Data Analytics?
Data Analytics involves the exploration, interpretation, and visualization of data to extract valuable insights, support decision-making, and uncover trends or patterns using statistical and computational methods.
What is the difference between Data Analytics and Business Analytics?
While Data Analytics focuses on analyzing and interpreting data to derive insights, Business Analytics encompasses a broader scope, incorporating data analysis into business strategies to drive informed decision-making and optimize overall business performance.
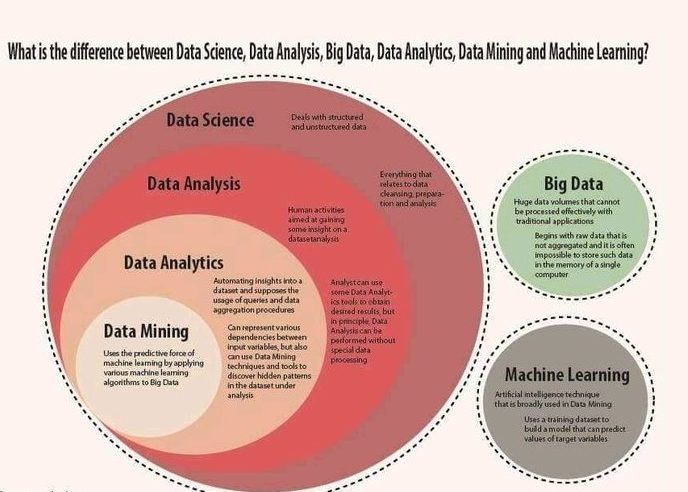
What is the difference between Data Mining and Data Analytics?
Data Mining involves discovering patterns and relationships in large datasets, often using algorithms to identify hidden information. Data Analytics, on the other hand, encompasses a broader range of activities, including data exploration, interpretation, and visualization for decision-making.
What is the difference between Data Warehousing and Data Analytics?
Data Warehousing involves the storage and management of large volumes of structured data in a centralized repository. Data Analytics, however, focuses on the analysis of data to extract insights and inform decision-making processes.
What is the difference between Data Science and Data Analytics?
Data Science is a broader field that encompasses various aspects, including data analytics. While Data Analytics focuses on analyzing and interpreting data, Data Science involves a more comprehensive approach, incorporating data exploration, machine learning, and advanced statistical methods.
What is the difference between Data Analytics and Data Analysis?
Data Analytics and Data Analysis are often used interchangeably, but Data Analytics typically refers to a broader process, including data exploration, interpretation, and visualization. Data Analysis, on the other hand, specifically involves examining data to draw conclusions or make decisions.
What is the difference between Data Analytics and Data Visualization?
Data Analytics involves the entire process of exploring and analyzing data, while Data Visualization specifically refers to the graphical representation of data using charts, graphs, or dashboards to enhance understanding and facilitate effective communication.
What is the difference between Data Analytics and Big Data Analytics?
Data Analytics involves analyzing and interpreting data to extract insights, while Big Data Analytics specifically deals with the analysis of large and complex datasets that may be beyond the capacity of traditional data processing tools.
What is the difference between Data Analytics and Data Engineering?
Data Analytics focuses on the analysis and interpretation of data, while Data Engineering involves the design, construction, and maintenance of data architectures and systems that enable the processing and storage of data for analytics.
What is the difference between Data Analytics and Data Reporting?
Data Analytics involves the entire process of exploring and analyzing data to derive insights, while Data Reporting specifically refers to the creation and presentation of reports that communicate findings and key performance indicators (KPIs) derived from the analyzed data.
Statistics in Data Science Interview Questions
Statistics are the backbone of data science, and mastering them is crucial for success in interviews. Here are 10 frequently asked statistics questions, along with the answers:
Explain the Central Limit Theorem and its implications for data analysis.
The Central Limit Theorem states that, regardless of the original data distribution, the distribution of sample means from sufficiently large samples will be approximately normally distributed. This theorem has profound implications for statistical analysis, as it allows for the application of normal distribution-based methods to analyze sample data, even if the population distribution is unknown.
Describe the difference between hypothesis testing and statistical significance.
Hypothesis testing involves making inferences about a population parameter based on sample data. Statistical significance, on the other hand, indicates whether an observed effect in the data is likely due to a real phenomenon or if it could have occurred by chance. Statistical significance is often assessed using p-values, with smaller values suggesting stronger evidence against the null hypothesis.
Explain the concept of Type I and Type II errors in hypothesis testing.
Type I error occurs when a null hypothesis is wrongly rejected, suggesting an effect that doesn’t exist. Type II error occurs when a null hypothesis is not rejected when there is a real effect. The balance between Type I and Type II errors is controlled by the significance level (alpha) and the power of the test.
Discuss the importance of data visualization in exploratory data analysis (EDA).
Data visualization in EDA is crucial for gaining insights, identifying patterns, and detecting outliers in the data. Visualization techniques, such as histograms, scatter plots, and box plots, provide an intuitive understanding of the dataset’s structure and help guide subsequent analyses.
Explain the concept of bias and its potential impact on statistical analysis.
Bias refers to systematic errors that consistently shift the results in one direction. It can lead to inaccurate conclusions and affect the validity of statistical analyses. Identifying and mitigating bias is essential for obtaining reliable and unbiased estimates from data.
Describe the difference between parametric and non-parametric statistical tests.
Parametric tests assume a specific distribution for the data (e.g., normal distribution), while non-parametric tests make fewer assumptions about the data’s distribution. Parametric tests are powerful but require stricter assumptions, while non-parametric tests are more robust but may have less statistical power.
Explain the concept of confidence intervals and their interpretation.
Confidence intervals provide a range of values within which the true population parameter is likely to fall. A 95% confidence interval, for example, suggests that if we were to repeat the sampling process many times, 95% of the intervals would contain the true parameter. It quantifies the uncertainty associated with point estimates.
Discuss the importance of variable selection in regression analysis.
Variable selection is crucial in regression analysis to identify the most relevant predictors. Including irrelevant variables may lead to overfitting, compromising model generalization. Techniques like stepwise regression or regularization methods help choose the most informative variables.
Explain the concept of collinearity and its potential problems in regression analysis.
Collinearity occurs when two or more predictors in a regression model are highly correlated, making it challenging to distinguish their individual effects on the response variable. It can inflate standard errors, leading to unreliable coefficient estimates. Techniques like variance inflation factor (VIF) help diagnose and address collinearity.
Describe the importance of model validation in data science projects.
Model validation ensures that a predictive model performs well on new, unseen data. It involves assessing metrics like accuracy, precision, recall, and F1 score, and using techniques such as cross-validation to estimate a model’s performance robustly. Validating models is crucial for ensuring their reliability in real-world applications.
Machine Learning in Data Science Interview Questions for Freshers
Landing your first data science role is exciting! To ace your interview, showcasing your understanding of machine learning (ML) concepts is crucial. Here are some common ML interview questions for freshers:
Explain the bias-variance tradeoff and its implications for model selection.
The bias-variance tradeoff is a critical consideration in model selection, as it involves finding the right balance between model complexity and performance. High bias (underfitting) and high variance (overfitting) can impact a model’s generalization to new data. Optimal model selection involves minimizing both bias and variance to achieve the best predictive performance.
Discuss the challenges and potential solutions for handling imbalanced datasets.
Handling imbalanced datasets presents challenges in machine learning, such as biased model training. Solutions include resampling techniques (oversampling or undersampling), using different evaluation metrics (precision, recall), and employing advanced algorithms like ensemble methods to address class imbalance.
How would you approach a data science problem with limited data or resources?
When faced with limited data or resources, strategies include leveraging transfer learning, using data augmentation techniques, exploring pre-trained models, and focusing on feature engineering. Additionally, employing simpler models and implementing rigorous cross-validation can optimize model performance with constrained resources.
Compare and contrast supervised and unsupervised learning, providing real-world examples.
Supervised learning involves training a model on labeled data, while unsupervised learning deals with unlabeled data. Real-world examples of supervised learning include spam classification, where the model is trained on labeled spam and non-spam emails. An example of unsupervised learning is clustering customer data to identify segments without predefined labels.
Explain the concept of dimensionality reduction and its applications in data analysis.
Dimensionality reduction involves reducing the number of features in a dataset while preserving essential information. Applications include visualizing high-dimensional data, reducing computational complexity, and enhancing model efficiency, especially in scenarios with a large number of variables.
Discuss the ethical considerations involved in using machine learning models.
Ethical considerations in machine learning include bias in training data, transparency in decision-making processes, privacy concerns, and potential social impacts. Implementing fairness-aware algorithms, diverse and representative datasets, and clear model documentation are crucial in addressing ethical challenges.
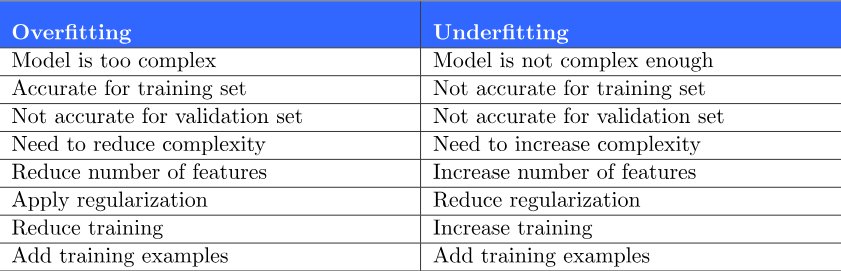
Describe the concept of overfitting and underfitting in machine learning models.
Overfitting occurs when a model learns the training data too well, capturing noise and hindering its ability to generalize to new data. Underfitting happens when a model is too simple to capture underlying patterns. Balancing model complexity through techniques like regularization helps prevent overfitting and underfitting.
Explain the concept of Gradient Descent in machine learning, using an analogy.
Gradient Descent is an optimization algorithm used to minimize the error in a model by adjusting its parameters. An analogy is descending a mountain by taking steps proportional to the steepest slope. The goal is to reach the lowest point (minimum error) efficiently.
Explain the difference between precision, recall, and F1-score, and when to use each.
Precision is the ratio of correctly predicted positive observations to the total predicted positives, recall is the ratio of correctly predicted positive observations to all actual positives, and F1-score is the harmonic mean of precision and recall. Precision is useful when false positives are critical, recall when false negatives matter, and the F1-score provides a balance between the two.
Discuss the concept of model validation and its importance in data science projects.
Model validation ensures that a predictive model performs well on new, unseen data. It involves assessing metrics like accuracy, precision, recall, and F1 score and using techniques such as cross-validation to estimate a model’s performance robustly. Validating models is crucial for ensuring their reliability in real-world applications.
Related Reads:
- Career Options After Engineering
- Career Opportunities in the IT Sector
- Software Development Engineer [SDE]
- Top 11 Emerging Careers In India For Freshers
FAQs on Data Science Interview Questions
What are the most common data science interview questions for freshers?
As a data science fresher, nailing basic concepts is crucial. Expect questions on:
- Types of machine learning algorithms: Supervised, unsupervised, and reinforcement learning.
- Model evaluation metrics: Accuracy, precision, recall, and F1-score.
- Overfitting and underfitting: Balancing model complexity and accuracy.
- Real-world applications of data science: Recommender systems, image recognition, fraud detection.
How can I prepare for technical coding questions in a data science interview?
Practice your coding skills in programming languages like Python and R. Focus on solving data manipulation, analysis, and visualization problems. Platforms like Naukri Campus offer practice challenges. Remember, efficient code and clear communication are key!
What are some commonly used statistical tests in data science interviews?
Brush up on your hypothesis testing basics with questions on:
- Central Limit Theorem: Understanding sampling distributions and drawing inferences.
- Type I and Type II errors: Balancing false positives and false negatives.
- T-tests, ANOVA, and Chi-square tests: Analyzing relationships and differences between variables.
How can I showcase my domain knowledge in a data science interview?
Research the company and its industry. Be prepared to discuss how your data science skills could solve specific problems they face. Showcase relevant projects or experience you have in their domain.
What are some red flags to watch out for in a data science interview?
Be wary of companies overly focused on buzzwords or specific tools. Look for interviews that emphasize problem-solving skills, critical thinking, and understanding of core data science concepts.
How can I stay calm and confident during a data science interview?
Practice mock interviews, prepare common interview questions and answers, and focus on your strengths. Remember, enthusiasm and communication skills are just as important as technical knowledge.
Should I get a data science certification before interviews?
Certifications can demonstrate your commitment to the field. However, real-world experience and strong problem-solving skills are often more valued by employers. Focus on building your skillset and portfolio before prioritizing certifications.
What salary range can I expect as a data science fresher?
Salary depends on factors like location, experience, and specific skills. Research average salaries for your region and experience level to negotiate effectively. Remember, highlighting your potential and long-term value is key.
What’s the most important tip for acing a data science interview?
Be passionate, curious, and eager to learn! Showcase your understanding of core concepts, your ability to solve problems, and your drive to contribute to the field. A genuine interest in data science will shine through and leave a lasting impression.
Latest Posts
How Does an AI Resume Analyzer Work? Everything You Need to Know
An AI resume analyzer is a tool that uses artificial intelligence to scan your resume the same way a recruiter or an Applicant Tracking System (ATS) would, checking your formatting,…
Best Fintech Companies for Freshers to Work at in India
India is one of the fastest-growing fintech markets in the world, with over 10,000 registered fintech startups and a market valuation projected to cross $150 billion by 2025. For freshers…
How to Become a CA (Chartered Accountant)
Every year, thousands of students in India ask the same question: “Should I do CA?” Some are fresh out of Class 12, weighing their options between B.Com, MBA, and the…
How To Become A Cybersecurity Analyst In India
Every time you log into your bank account, your college portal, or your favorite app, there’s a team of professionals working silently in the background, making sure no one gets…
Popular Posts
Best CV Formats for Freshers: Simple, Professional & Job-Winning Templates
Creating an effective CV (Curriculum Vitae) is the first step towards landing your dream job or internship as a fresh graduate. Your CV is your initial introduction to potential employers…
How to Pass the TCS NQT Aptitude Test?
Every year, lakhs of engineering and graduation students apply to TCS, one of India’s largest IT employers. And almost every single one of them hits the same first wall: the…
How to Make a Fresher Resume That Recruiters Notice
If you are a college student or a fresher stepping into the professional world, creating a well-structured resume is your first step to success. A polished and ATS-friendly resume can…
What is SSC CGL Exam? – Complete Details for 2026
If you’re a college student or a fresh graduate wondering, “Should I appear for SSC CGL?” you’re in the right place. Every year, over 30 lakh students apply for this…
How to Start an AI Career in India: Skills and Future of Work
Artificial Intelligence (AI) is revolutionizing industries worldwide. From automating routine tasks to enabling self-driving cars and intelligent healthcare diagnostics, AI is reshaping the future of work. For college students and…