Working
When the model predicts an output word, it only uses input bits where the most critical information is concentrated rather than the complete sequence. Put another way. It merely pays attention to a few input words.
Attention is a connection between the encoder and the decoder that transmits information from every encoder concealed state to the decoder. The model can selectively focus on valuable bits of the input sequence using this framework and learn their relationship. It makes it more accessible for the model to deal with extended input sentences.
The goal is to maintain the same decoder and replace sequential RNN/LSTM in the encoder with bidirectional RNN/LSTM.
By considering a window size of Tx, we pay special attention to specific words (say four words x1, x2, x3, and x4). We'll generate a context vector c1 with these four words and provide it to the decoder as input. Using these four words, we'll create a context vector c2. We also have weights of a1, a2, and a3, with the sum of all weights within one window equaling 1.
Similarly, we construct context vectors from various word sets with varying values. Because not all of the inputs are used in generating the associated output, the attention model computes a set of attention weights denoted by a(t,1), a(t,2),..., a(t,t). The weighted total of the annotations is used to construct the context vector ci for the output word yi:
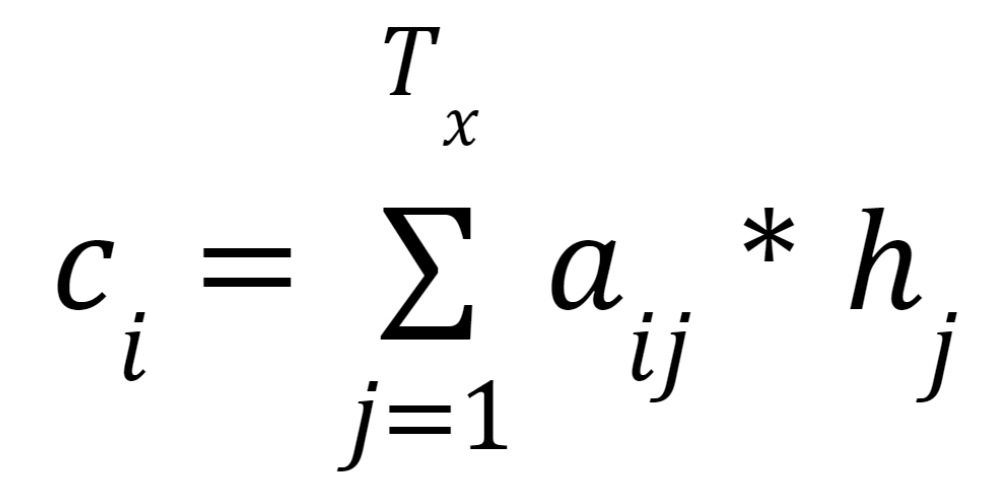
Normalizing the output score of a feed-forward neural network represented by the function that captures the alignment between input at j and output at I yields the attention weights.

Algorithm
By assigning a score to each word, attention exerts varied emphasis on different terms. The context vector is generated by aggregating the encoder hidden states using the softmax scores and a weighted sum.
An attention layer's algorithm can be split down into four steps.
Step 1: Get ready for the hidden states.
Step 2: Apply a softmax layer to all of the scores.
Step 3: Multiply the softmax score of each encoder's hidden state.
Step 4: Add all of the alignment vectors together.
Step 5: Feed the decoder the context vector.
Implementation
This section will look at using Python's NumPy and SciPy modules to build the general attention mechanism.
We'll compute the attention for simplicity's first word of a four-word sequence. Next, the function will be generalized to calculate an attention output in matrix form for all four words.
As a result, let's begin by defining the word embeddings of the four different words for calculating attention. An encoder would usually create these word embeddings, but we'll explain them manually for this example.
from numpy import array
from numpy import random
from numpy import dot
from scipy.special import softmax

You can also try this code with Online Python Compiler
word_1 = array([1, 0, 1])
word_2 = array([0, 1, 0])
word_3 = array([1, 1, 0])
word_4 = array([0, 0, 1])
You can also try this code with Online Python Compiler
Now, we stack the word embeddings into a single array
words = array([word_1, word_2, word_3, word_4])
You can also try this code with Online Python Compiler
The weight matrices are generated next, multiplied by the word embeddings to generate the queries, keys, and values. These weight matrices will be generated at random here, but in actuality, they will have been learned throughout the training.
random.seed(42) # to allow us to reproduce the same attention values
W_Q = random.randint(3, size=(3, 3))
W_K = random.randint(3, size=(3, 3))
W_V = random.randint(3, size=(3, 3))
You can also try this code with Online Python Compiler
Generating the keys, queries and values
Q = words @ W_Q
K = words @ W_K
V = words @ W_V
You can also try this code with Online Python Compiler
Calculating the scores of the query vectors against all key vectors
scores = Q @ K.transpose()
You can also try this code with Online Python Compiler
The scores are then processed via a softmax procedure to construct the weights. We generally divide the score values by the square root of the key vectors' dimensionality to keep the gradients constant.
weights = softmax(scores / K.shape[1] ** 0.5)
You can also try this code with Online Python Compiler
Finally, we calculate attention values that are calculated by a weighted sum of all four value vectors.
attention = weights @ V
print(attention)
You can also try this code with Online Python Compiler
Output
[[9.92901880e-01 1.62883281e+00 6.35930933e-01]
[1.22920950e-05 1.90485723e-05 6.75647734e-06]
[3.95390534e-03 5.93279494e-03 1.97888961e-03]
[3.08678210e-03 5.06988081e-03 1.98309872e-03]]
That’s the basic implementation of the attention mechanism.
FAQs
-
Why does the attention mechanism work?
The Attention mechanism has revolutionized how we build NLP models, and it is now a standard feature in most modern NLP models. This allows the model to "remember" all words in the input and focus on select terms when forming a response.
-
How does the attention mechanism aid in resolving RNNS and Lstms issues?
The Long sentences, especially those that are longer than those in the training corpus, may be challenging for the neural network to cope with. Unlike the traditional Encoder-Decoder approach, the attention mechanism allows us to look at all hidden states from the encoder sequence to make predictions.
-
What are the advantages of focusing on a local audience?
It's differentiable, like soft attention, and easier to execute and train. It takes less time to compute than global or soft attention. Local attention finds the best-matched point pt in the input sequence based on the decoder's current state.
-
What problem does attention solve?
The Encoder-Decoder model's limitation of encoding the input sequence to one fixed-length vector to decode each output time step is addressed. This difficulty is thought to be more prevalent when decoding extended sequences.
Key Takeaways
Let us brief out the article.
Firstly, we saw the basic definition of attention and causes, which led to the discovery of the attention mechanism. Later, we saw the working and the algorithm of the attention mechanism. Lastly, we implemented a primary attention mechanism using numpy and pandas.
I hope you all like this article.
Happy Learning Ninjas!




























 17+ registered
17+ registered 

