Do you think IIT Guwahati certified course can help you in your career?
Introduction
Breadth First Search (BFS) is a graph traversal algorithm used to explore nodes in a graph or tree data structure. It starts at the tree root or graph source node and explores all the neighboring nodes at the present depth before moving on to the nodes at the next depth level. BFS is commonly used for finding the shortest path, testing biconnectivity, finding connected components, and solving puzzles with only one solution.
In this article, we'll learn about the BFS algorithm, understand how it works, implement it in Python, analyze its complexity, and discuss its applications.
What is Breadth First Search in Python?
Breadth First Search is an algorithm for traversing or searching tree or graph data structures. It explores the neighbor nodes first, before moving to the next level neighbors. BFS is an uninformed search method that aims to expand and examine all nodes of a graph or combination of sequences by systematically searching through every solution. In other words, it exhaustively searches the entire graph or sequence without considering the goal until it finds it. It does not use a heuristic.
BFS is a traversing algorithm where you should start traversing from a selected node (source or starting node) and traverse the graph layer-wise thus exploring the neighbor nodes (nodes which are directly connected to source node). You must then move towards the next-level neighbor nodes.
As the name suggests, BFS traverses the graph breadthwise. That is, it visits all the nodes of a level before going to the next level. The breadth-first search algorithm uses a queue data structure for traversal.
Breadth-First Search Python Algorithm
Steps for performing BFS traversal:
1. First, choose a starting node (source node) and visit it. This node will be the root node in a tree or any random graph node.
2. Check if the current node is the goal state. If it is, stop and return the solution.
3. Else, for the current node, retrieve all of its adjacent nodes. Add the unvisited nodes to the end of the queue.
4. Keep track of all visited nodes to avoid visiting the same node more than once and avoid getting stuck in an infinite loop if there are cycles in the graph.
5. Mark the current node as visited.
6. Dequeue the first node from the queue, and make it the current node.
7. Go back to step 2 and continue traversing until the goal state is reached or the queue is empty (no solution).
Let’s look at the visual representation of the BFS algorithm:
1 procedure BFS(G, start_v) is
2 let Q be a queue
3 label start_v as discovered
4 Q.enqueue(start_v)
5 while Q is not empty do
6 v := Q.dequeue()
7 if v is the goal then
8 return v
9 for all edges from v to w in G.adjacentEdges(v) do
10 if w is not labeled as discovered then
11 label w as discovered
12 w.parent := v
13 Q.enqueue(w)
In summary, BFS starts at a node, visits it, adds its neighbors to a queue, and repeats the process for each node in the queue until the goal is reached or the queue is empty.
How Does the Breadth First Search Algorithm Work?
Let's understand how BFS works with the help of a simple example.
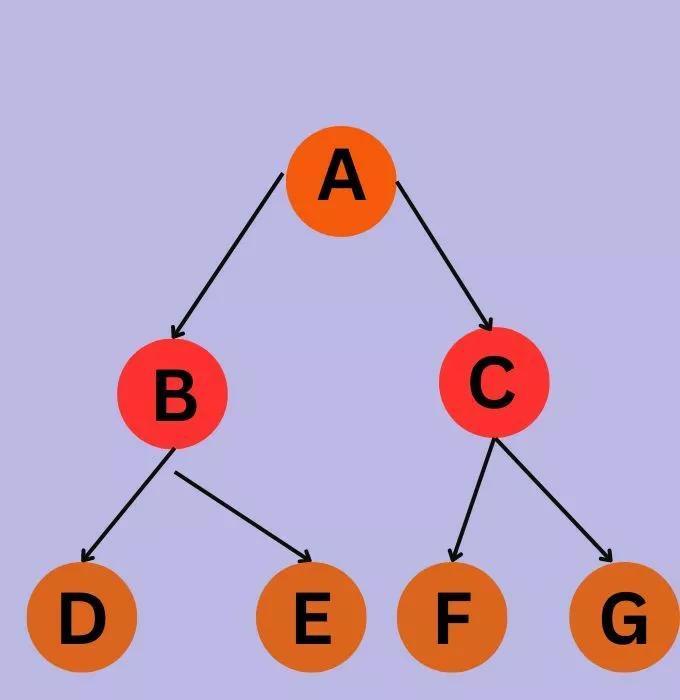
Consider the following graph:
We start from the source node, let's say A. We visit A and add its neighbors B and C to the queue.
Queue: [B, C]
Visited nodes: [A]
Next, we dequeue B from the queue, visit it, and add its unvisited neighbors D and E to the queue.
Queue: [C, D, E]
Visited nodes: [A, B]
We continue this process, dequeuing C from the front of the queue, visiting it, and adding its unvisited neighbors F and G to the queue.
Queue: [D, E, F, G]
Visited nodes: [A, B, C]
We dequeue the next node D, visit it, but it has no unvisited neighbors, so nothing is added to the queue.
Queue: [E, F, G]
Visited nodes: [A, B, C, D]
This process continues until we have visited all the nodes in the graph. The order of visited nodes will be:
A -> B -> C -> D -> E -> F -> G
This is the BFS traversal of the graph. It visits the nodes in a breadth-first manner, exploring all neighbors at the current depth before moving to the next depth level.
Implementation of Breadth First Search in Python
Now let's see how to implement BFS in Python.
For this,we'll use an adjacency list representation of the graph:
Python
Python
from collections import deque
def bfs(graph, start):
visited = set()
queue = deque([start])
visited.add(start)
while queue:
vertex = queue.popleft()
print(vertex, end=" ")
for neighbor in graph[vertex]:
if neighbor not in visited:
visited.add(neighbor)
queue.append(neighbor)
# Example usage
graph = {
'A': ['B', 'C'],
'B': ['A', 'D', 'E'],
'C': ['A', 'F', 'G'],
'D': ['B'],
'E': ['B'],
'F': ['C'],
'G': ['C']
}
print("BFS traversal:")
bfs(graph, 'A')
You can also try this code with Online Python Compiler
1. We define a function `bfs` that takes the graph and the starting node as parameters.
2. We create a set `visited` to keep track of visited nodes and a queue `queue` to store the nodes to be visited.
3. We add the starting node to the visited set and the queue.
4. We start a loop that continues until the queue is empty.
5. Inside the loop, we dequeue a node from the queue using `popleft()` and print it.
6. We then iterate over the neighbors of the current node.
7. If a neighbor has not been visited, we add it to the visited set and enqueue it.
8. We repeat steps 5-7 until the queue is empty.
Breadth-First Search Python Complexity
Let's analyze the time and space complexity of the BFS algorithm implemented in Python.
Time Complexity
- In the worst case, BFS visits every vertex and edge in the graph.
- The time complexity of BFS is O(V + E), where V is the number of vertices and E is the number of edges in the graph.
- This is because we need to visit each vertex once and traverse through each edge to visit the adjacent vertices.
- The queue operations (enqueue and dequeue) take constant time, O(1).
- Accessing the adjacency list to get the neighbors of a vertex also takes constant time, O(1), on average.
- Therefore, the overall time complexity of BFS is O(V + E).
Space Complexity
- The space complexity of BFS is determined by the size of the queue and the visited set.
- In the worst case, when the graph is connected, and we need to visit all vertices, the queue can contain at most all the vertices.
- The visited set also needs to store all the vertices to keep track of visited nodes.
- Hence, the space complexity of BFS is O(V), where V is the number of vertices in the graph.
- Additionally, the space required for the adjacency list representation of the graph is O(V + E).
It's important to note that the time and space complexity of BFS can vary depending on the graph's structure and the number of connected components. In a sparse graph with multiple connected components, the actual time and space complexity may be lower than the worst-case scenario.
Applications of Breadth-First Search
1. Shortest Path: BFS can be used to find the shortest path between two nodes in an unweighted graph. It guarantees the shortest path because it explores all neighboring nodes at the current depth before moving to the next level.
2. Web Crawling: BFS is used by search engines to crawl websites. Starting from a seed page, BFS explores all the links on that page, then moves to the next level of links, and so on. This allows the search engine to index web pages efficiently.
3. Social Networks: BFS can be used to find the shortest chain of friends between two people in a social network. It can also be used to find all the people within a certain degree of separation from a given person.
4. Peer-to-Peer Networks: In peer-to-peer networks, BFS can be used to find the shortest path between two nodes for efficient data transfer. It helps in minimizing the latency and maximizing the throughput of the network.
5. Garbage Collection: In programming languages with automatic memory management, like Java or Python, BFS is used as part of the garbage collection process. It helps in identifying and collecting objects that are no longer reachable from the root objects.
6. Serialization/Deserialization: BFS can be used to serialize a graph or a tree-like data structure into a linear format. It ensures that the serialized data maintains the original structure and can be deserialized back into the original form.
7. Solving Puzzles: BFS is often used to solve puzzles or games that can be represented as graphs. For example, in a maze, BFS can be used to find the shortest path from the starting point to the exit.
8. Testing Bipartiteness: BFS can be used to test whether a graph is bipartite or not. A bipartite graph is a graph whose vertices can be divided into two disjoint sets such that every edge connects a vertex from one set to a vertex from the other set.
Frequently Asked Questions
Can BFS be used for weighted graphs?
BFS is primarily used for unweighted graphs. For weighted graphs, algorithms like Dijkstra's algorithm or A* search are more suitable.
Is BFS guaranteed to find the shortest path?
Yes, BFS guarantees the shortest path in terms of the number of edges traversed, as it explores all neighboring nodes at the current depth before moving to the next level.
What is the main advantage of using BFS?
The main advantage of BFS is that it finds the shortest path in an unweighted graph efficiently, with a time complexity of O(V + E), where V is the number of vertices and E is the number of edges.
Conclusion
In this article, we discussed the Breadth-First Search (BFS) algorithm and its implementation in Python. We learned that BFS is a graph traversal algorithm that visits nodes level by level, exploring all neighboring nodes at the current depth before moving to the next level. We explained the BFS algorithm steps, provided a Python implementation, and analyzed its time and space complexity. Furthermore, we highlighted various applications of BFS, including finding shortest paths, web crawling, social networks, and solving puzzles.
Live masterclass
Prompt Engineering: Must-have GenAI Skill for 30L+ Roles at Amazon
by Anubhav Sinha
16 Jul, 2026
12:30 PM
Using Netflix Data to Master Power BI
by Ashwin Goyal
13 Jul, 2026
12:30 PM
Top GenAI Skills to crack 30L+ CTC at Amazon & Google
by Sumit Shukla
14 Jul, 2026
11:30 AM
JioHotstar Sports Analytics using IPL Dataset
by Prerita Agarwal
15 Jul, 2026
12:30 PM
Prompt Engineering: Must-have GenAI Skill for 30L+ Roles at Amazon































 9+ registered
9+ registered 

