Do you think IIT Guwahati certified course can help you in your career?
Introduction
In interviews, questions related to strings and anagrams are quite common because they test several important skills such as problem-solving, algorithm design, and string manipulation.
Additionally, these types of questions are used to assess a candidate's knowledge of data structures, such as arrays, maps, and sets.
This article discusses a similar problem based on string. Let us now quickly start with the problem statement.
Problem Statement
You are given two strings, 'X' and 'Y'. Check if any anagram of 'X' is lexicographically smaller than any anagram of string 'Y'.
Example
1. X = "cbar", Y = "ab"
Output = true
Explanation:
If we change X from "cbar" to "abcr" and Y from "ab" to "ba". Then "abcr" < "ba". Hence, return true.
2. X = "rt" ,Y = "ab"
Output = false
Explanation:
No anagram of X is smaller than any anagram of Y. Smallest anagram of X = "rt" and Largest anagram of Y = "ba". Since "rt" > "ba", return false.
Now that we've understood the problem, let's dive into the solution.
Intuition
An anagram is a word or phrase formed by rearranging the letters of another word or phrase.
For example, "listen" and "silent" are anagrams of each other because they have the same letters but in different order.
Now, let's say we want to check if any anagram of string S is lexicographically smaller than that of string T.
What is lexicographically small?
The lexicographically smaller string refers to the string that comes first in alphabetical order when comparing two or more strings character by character.
To determine which string is lexicographically smaller, we begin by comparing the first character of each string.
If the first character of the first string is less than the first character of the second string, the first string is lexicographically smaller or vice versa.
If the first characters are the same, we continue to compare the second characters, and so on, until we find a character that is different.
For example, consider the following strings:
"apple"
"banana"
"cheery"
"date"
=> In this example, "apple" is lexicographically smaller than "banana" because 'a' comes before 'b' in the alphabet.
=>"banana" is lexicographically smaller than "cheery" because the first two characters are the same, but 'b' comes before 'c' in the alphabet.
=>"cheery" is lexicographically smaller than "date" because 'c' comes before 'd' in the alphabet.
Approach - Using Sorting
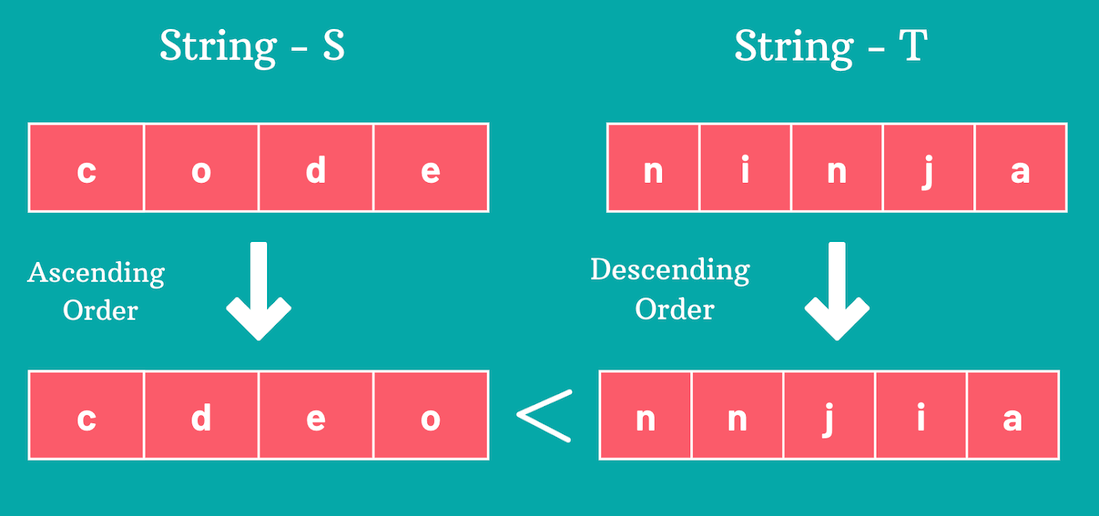
In this approach, we will be using the sorting algorithm to sort the string S in ascending order and String T in descending order.
If you think carefully about the problem statement, we need to find the anagram that may come smaller than any anagram of String T.
By using the Sorting algorithm, we can compare the sorted strings to see if the lexicographically smallest anagram of S is smaller than the lexicographically largest anagram of T.
If it is so, i.e., means there exists an anagram that satisfies the condition.
Otherwise, we will return false.
Algorithm
Sort the characters of string S in ascending order.
Sort the characters of string T in descending order.
Compare the sorted strings to see if the lexicographically smallest anagram of S is smaller than the lexicographically largest anagram of T.
Code in C++
#include <iostream>
#include <algorithm>
#include <string>
using namespace std;
bool isLexicographicallySmallerAnagram(string S, string T) {
// Sort string S in ascending order
sort(S.begin(), S.end());
// Sort string T in descending order
sort(T.begin(), T.end(), greater<char>());
// Compare the sorted strings to check if the lexicographically smallest anagram of S is smaller than the lexicographically largest anagram of T
return S < T;
}
int main() {
string S = "code";
string T = "ninja";
if (isLexicographicallySmallerAnagram(S, T)) {
cout << "Yes, there exists an anagram of " << S << " which is lexicographically smaller than any anagram of " << T << endl;
} else {
cout << "No, there is no anagram of " << S << " which is lexicographically smaller than any anagram of " << T << endl;
}
return 0;
}
You can also try this code with Online C++ Compiler
Yes, there exists an anagram of code which is lexicographically smaller than any anagram of ninja.
Code in Java
import java.util.*;
class Main {
static boolean isLexicographicallySmallerAnagram(String S, String T) {
// Sort string S in ascending order
char[] sChars = S.toCharArray();
Arrays.sort(sChars);
S = new String(sChars);
// Sort string T in descending order
char[] tChars = T.toCharArray();
Arrays.sort(tChars);
T = new StringBuilder(new String(tChars)).reverse().toString();
// Compare the sorted strings to check if the lexicographically smallest anagram of S is smaller than the lexicographically largest anagram of T
return S.compareTo(T) < 0;
}
public static void main(String[] args) {
String S = "code";
String T = "ninja";
if (isLexicographicallySmallerAnagram(S, T)) {
System.out.println("Yes, there exists an anagram of " + S + " which is lexicographically smaller than any anagram of " + T);
} else {
System.out.println("No, there is no anagram of " + S + " which is lexicographically smaller than any anagram of " + T);
}
}
}
You can also try this code with Online Java Compiler
O(n log n), where n is the length of the input string. The function calls sort twice, so the overall time complexity is O(2n log n) which simplifies to O(n log n).
Space Complexity
O(1), since we are not using any extra space.
Frequently Asked Questions
What is an anagram? Give an example of an anagram.
An anagram is a word or phrase formed by rearranging the letters of another word or phrase. In other words, two words are said to be anagrams of each other if they use the same letters in a different order to form a new word.
For example, abba is an anagram of baba.
Which sorting algorithm is the fastest?
In practice, Quick Sort is usually the fastest sorting algorithm. Its performance is measured most of the time in O(N × log N).
What is the stability of sorting algorithms?
A stable sorting algorithm maintains the relative order of the items with equal sort keys.
Conclusion
This article discussed the problem of checking if any anagram of string S is lexicographically smaller than that of string T. We have discussed one approach to solve this problem.
We have also discussed the time and space complexity of the approach.
































 8+ registered
8+ registered 

