Do you think IIT Guwahati certified course can help you in your career?
Introduction
DBSCAN stands for Density-Based Spatial Clustering of Applications with Noise, a density-based clustering algorithm similar to K-Means (a centroid Based clustering algorithm) and Agglomerative (a Hierarchical clustering algorithm). The DBSCAN algorithm grows regions with sufficiently high Density into clusters and discovers clusters of arbitrary shape in spatial datasets with noise. It basically defines a cluster as a maximal set of density-connected points. Generally, we partition points into dense regions by not-so-dense regions in a density-based clustering algorithm.
DBSCAN
We need to learn some new definitions before diving deep into how the DBSCAN algorithm finds the clusters and how it exactly works.
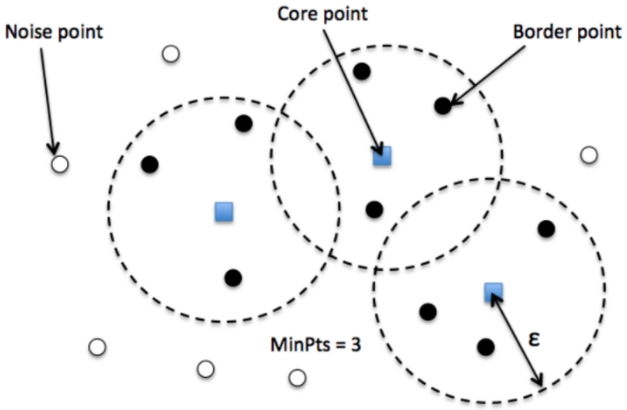
Density at a point P: number of points within a region of radius 𝛜 (Epsilon).
𝛜-neighborhood: The neighborhood within a radius 𝛜 of a given object is called 𝛜-neighborhood of the object
Density Region: A region of radius 𝛜 that contains at least MinPts (Minimum Points) points.
A point is said to be a core point if it has more than a specified number of points (MinPts) within a 𝛜. A core point will belong to the interior of the dense region.
A point is said to be a border point if it has fewer than MinPts, but it is a neighborhood of the core point.
A noise point is any point that is not a core point or a border point.
Density Edge: An edge is a connection between two core points, p and q if they are within distance 𝛜.
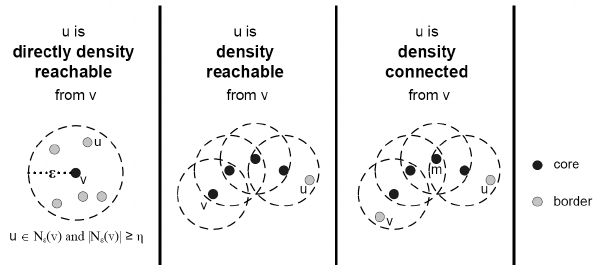
Directly density-reachable: An object p is directly density reachable from object q if p is 𝛜-neighborhood of q and q is a core object.
Density reachable: An object p is density-reachable from object q if q is a core object and p and q are density-connected objects.
Density Connected: A point p is density connected to point q if there is a path of edges from p to q.
How Does DBSCAN actually find the clusters?
DBSCAN searches for clusters for a given dataset by checking the 𝛜-neighborhood of each point in the database. If the 𝛜-neighborhood of a point p contains more than MinPts, a new cluster with p as a core object/point is created. DBSCAN then iteratively collects directly density-reachable objects from these core objects, which may involve merging the density-reachable clusters. The process terminates when no new point can be added to any cluster.
For Each data point of the dataset, label the points as core, border, and noisy points.
Remove the noisy points from the game.
For every core point p of the dataset that has not been assigned to a cluster,
Create a new cluster with core point and all the points that are density-connected to p
Then Assign the border points to the cluster of the closest core point.
This process continues until no new point cannot be added to any cluster.
MinPts and 𝛜
MinPts:
In General, the MinPts must be greater than or equal to d+1, d = dimensionality of the dataset. Or in most cases, the Minpts will be twice the dimensionality.
If the dataset is too noisy, then the value of MinPts should be large.
Or, based on the user/domain interest, we can use their defined MinPts.
Eps (𝛜):
We can use the Knee/Elbow method to find the best Eps value. You can get more details regarding this method here: Finding Best Epsilon Value.
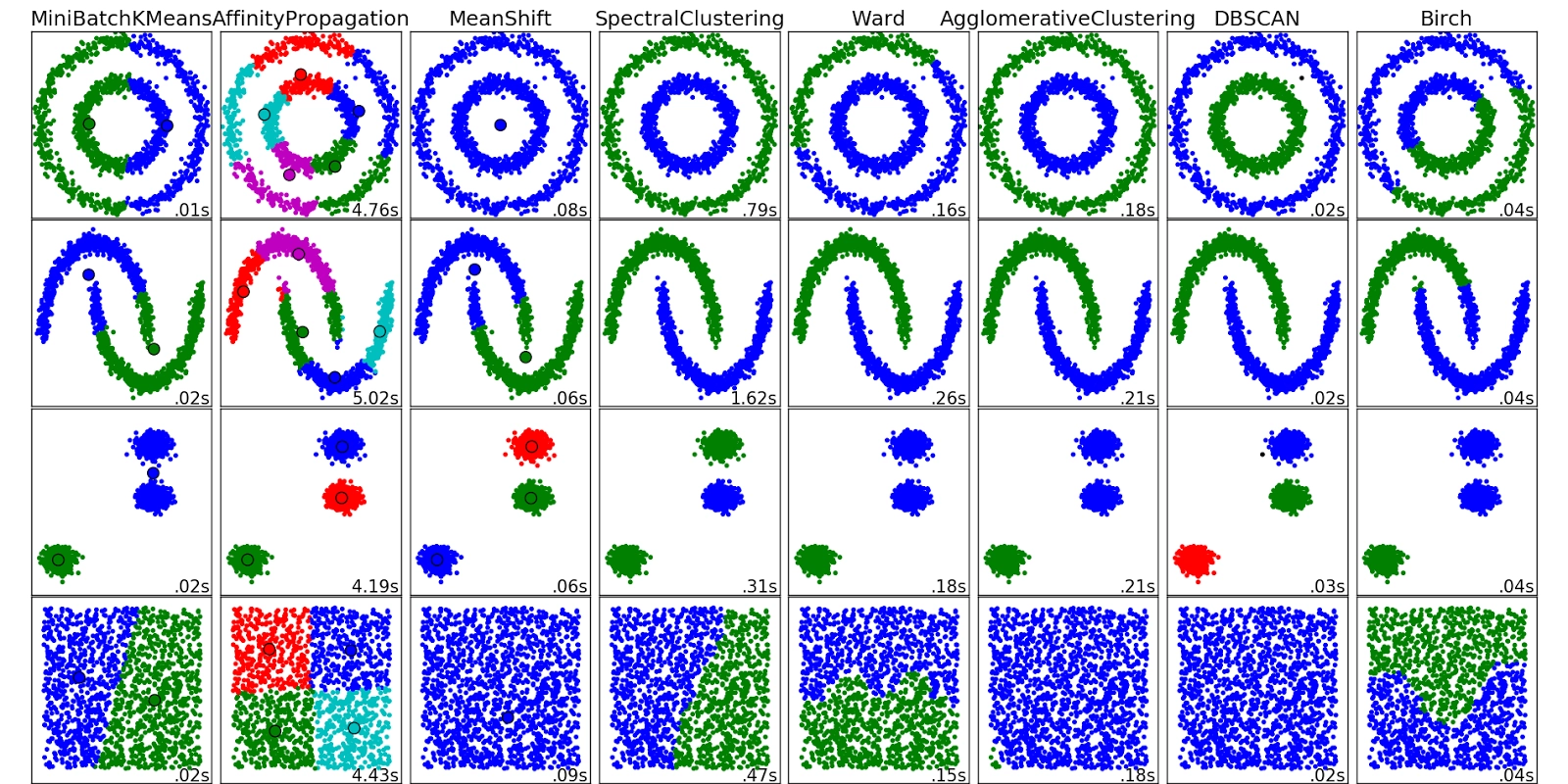
Examples or Comparison of DBSCAN with Other clustering methods
We can view how the clusters formed using clustering.labels_
This line gives an array of values of length of the dataset containing values ranging from 0 to n and -1, where each value represents a cluster and -1 represents a noise point.
Code Example
from sklearn.cluster import DBSCAN
import numpy as np
X = np.array([[1, 5], [2, 3], [5,10],
[8, 5], [8, 6], [70, 8]])
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
print(clustering.labels_)
You can also try this code with Online Python Compiler
What is DBSCAN stands for? DBSCAN, a clustering technique, stands for Density-Based Spatial Clustering of Applications with Noise. Here Density-Based refers that this technique uses Density as a concept to cluster the points on considering noise points removal.
What are the parameters of the DBSCAN algorithm? There are majorly two parameters used in the DBSCAN algorithm: Epsilon and MinPts, where epsilon is the radius of arbitrary shape, and MinPts is the number of minimum points that are to be considered to be in a cluster.
What are the time and space complexities of DBSCAN? Time Complexity: O(n), can be reduced to O(n*logn) by using efficient hyperparameters such as Eps and MinPts. Space Complexity: The space complexity is O(n), n is the number of points to be clustered.
Is there any built-in fancy method to use using Python? Python’s scikit-learn library provides a DBSCAN method that can be imported from sklearn.cluster module and can be used easily.
Key Takeaways
We have discussed more briefly the DBSCAN algorithm in this article, how it works, what are the essential features that this algorithm supports, what is the exact process of this clustering technique, and how it can be used using the scikit-learn built-in method, etc.,
Hey Ninjas! You can check out more unique courses on machine learning concepts through our official website, Coding Ninjas, and checkout Coding Ninjas Studio to learn through articles and other important stuff to your growth.
Happy Learning!
Live masterclass
Top 5 GenAI Projects to Crack 25 LPA+ Roles in 2026
by Shantanu Shubham
27 Apr, 2026
03:00 PM
Resume Building for Amazon SDE roles: 20L+ CTC Roadmap
by Anubhav Sinha
26 Apr, 2026
08:30 AM
Python + AI Skills to ace 30L+ CTC Data roles at Amazon
by Prerita Agarwal
26 Apr, 2026
06:30 AM
Zero to Data Analyst: Amazon Analyst Roadmap for 30L+ CTC
by Abhishek Soni
27 Apr, 2026
11:30 AM
Top 5 GenAI Projects to Crack 25 LPA+ Roles in 2026
by Shantanu Shubham
27 Apr, 2026
03:00 PM
Resume Building for Amazon SDE roles: 20L+ CTC Roadmap






























 13+ registered
13+ registered 

