Do you think IIT Guwahati certified course can help you in your career?
Introduction
This paper looked at both the theoretical and practical elements of LexRank. LexRank is a natural language processing method that uses a stochastic graph-based method to compute the relative relevance of textual units.
Let's break down the LexRank algorithm into bits so that we can get to the model output step by step, with mathematical ideas explained along the way:
Input for the model
embeddings of words
The similarity in cosine within a sentence
Adjacency matrix
Matrix of connectivity
Centrality of eigenvectors
The model's conclusion
Input to the model
The model's fundamental input could be a single article or a collection of essays. It depends on whether you want to summarise a single piece or a group of papers.
"This is a sample sentence from the article," LexRank can devour any content. The second statement is as follows: This is the third and most crucial sentence because it states that the preceding sentences are only instances."
In the given example, LexRank is most likely to return only the last sentence to summarize the text.
Ok, but how to train a model with a text?
Word embeddings
We must translate the text input into numbers, usually in real-valued vectors, before we can use any mathematical procedure. Word embeddings are a type of vector representation of words.
Word embeddings are usually calculated so that words represented by similar vectors are anticipated to have similar meanings.
Let’s see a simple example of the cat, dog, and airplane
# example representation vector of a word "cat", "dog" and "aeroplane"
cat_representation = [0, 0, 0, 1, 0, 1]
dog_representation = [0, 0, 0, 1, 1,
airplane_represenatation = [1, 1, 0, 0, 0, 0]
As you can see, the vector representations of "cat" and "dog" are pretty similar; however, "airplane" differs significantly from both animal nouns. In simple terms, the vectors of "cat" and "dog" have standard components, whereas the vector of an airplane has no common parts.
Ok, but why it is important? How can we use it?
Intra-sentence cosine similarity
Word embeddings can be used in a sentence in a variety of ways. However, an intra-sentence of the sentence is employed in LexRank implementation. It refers to the sum of all word embeddings within a sentence compared to other sentences.
Let’s see an example
sentence_1 = "this is a cat"
sentence_2 = "this is a dog"
# example representation of words in the form of vectors where each word is represented as a separate vector
this_vector = [0,0,0]
is_vector = [1,0,0]
cat_vector = [0, 1, 0]
dog_vector = [0, 0, 1]
# how sentence looks in the form of vectors:
sentence_1 = "[0,0,0] [1,0,0] [0, 1, 0]"
sentence_2 = "[0,0,0] [1,0,0] [0, 0, 1]"
# how to calculate intra sentence? Just take an average
intra_sentence_1 = [1/3, 1/3, 0]
intra_sentence_2 = [1/3, 0, 1/3]
But what’s a cosine similarity?
It's also a breeze! It's simply a statistic (like any other) that may be used to determine how similar data objects are, regardless of their size. In this scenario, the use of vectors to express related texts.
The formula for calculating the cosine similarity is:
Cos(x, y) = x . y / ||x|| * ||y||
Where:
x . y - a dot product
|| x || - length of a vector x
|| y || - length of a vector y
How to calculate it?
x = sentence_1
y = sentence_2
x . y = 1/3*1/3 + 1/3*0 + 0*1/3 = 1/9
|| x || = √ (1/3)^2 + (1/3)^2 + (0)^2 = 0.47
|| y || = √ (1/3)^2 + (0)^2 + (1/3)^2 = 0.47
Cos(x, y) = 1/9 / ((0.47) * (0.47)) = 0.024
And now, the algorithm calculates it to every sentence within a given text input.
But how can we represent it?
Adjacency matrix
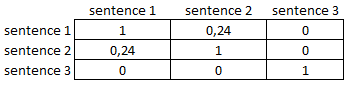
LexRank employs a connectivity matrix to indicate similarity across all sentences. Consider the following scenario:
# Example of adjacency matrix with weights as similarities
Let's use previous sentences and add a new one with example similarities
sentence_1 = "this is a cat"
sentence_2 = "this is a dog"
sentence_3 = "this is an aeroplane"
example of adjacency matrix with similarities
As you can see, sentences 1 and 2 are comparable. However, sentence 3 is unrelated to the others.
There is one major issue here. When you have a lot of articles, one of them may have a lot of similar sentences. In this situation, the model would only be able to output sentences from this single article. In more technical terms, it's known as a local trap, in which a few little sentences vote for each other.
LexRank considers the value of sentences about the importance of the sentences "recommending" to address the issue mentioned above.
But how to do it?
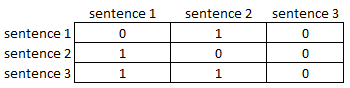
Connectivity matrix
An adjacency matrix is usually a binary matrix that only contains information on whether an edge connects two vertices. A connectivity matrix is often a list of which a line connects vertex numbers.
LexRank adds a count of links from other sentences to eliminate the local trap problem. A statement may contain only two connections in plain English, but they are solid, and they win.
For example:
sentence_1 is similar to10 other sentences sentence_2 is similar to6 other sentences sentence_3 is similar to sentence_1 and sentence_2 sentence_3 is a winner because all connections from sentence_1 and setence_2 counts.
LexRank uses a threshold to count the number of connections. It only counts sentences as similar to itself if the cosine similarity is more significant than 0.3 or 0.1, for example.
Let's look at an example connection matrix with a threshold of 0.2:
example connectivity matrix
As you can see sentence_3 is of the highest importance.
Last step — how to find all sentences with the highest score on the whole matrix?
Eigenvector centrality
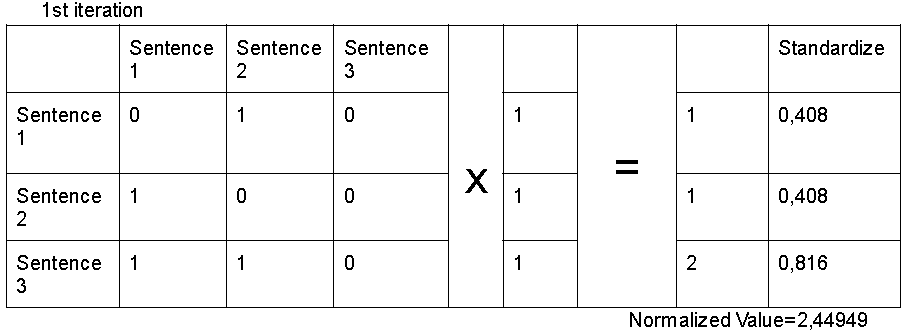
LexRank uses eigenvector centrality to determine the introductory sentences. The power iteration method is the name of the way.
How does it work?
Each matrix row is multiplied by one in the first step.
Second, we square the rows and extract a root of the sum, such as (1² + 1² + 2²)
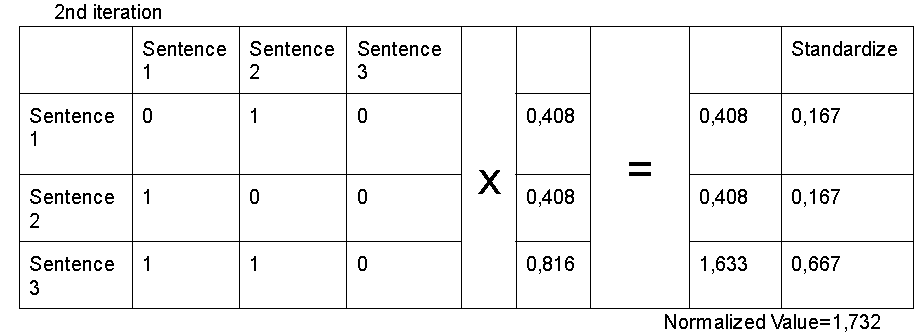
This step is repeated until the normalized value does not change significantly between iterations.
Output
Finally, we have the output. In the above example, sentence_3 got the highest score (0,667).
Frequently Asked Questions
What is the Textrank algorithm?
Textrank is a graph-based ranking algorithm that has been successfully used in citation analysis, similar to Google's PageRank algorithm. We frequently employ text rank for keyword extraction, automatic text summarization, and phrase ranking.
What is extractive text summarization?
The term "extractive text summarization" refers to extracting key information or sentences from a text file or source document. A novel statistical strategy for removing text summarization on a single copy is demonstrated in this research.
What is summarization in NLP?
Constructing a concise, cohesive, and fluent summary of a lengthier text document, which includes highlighting the text's essential points, is known as text summarization.
What are extractive and abstractive summarization?
The extractive summarization approach concatenates excerpts from a corpus into a summary, whereas abstractive summarization entails paraphrasing the material using unique sentences.
What is BERT ML?
BERT is an open-source natural language processing machine learning framework (NLP). BERT is a program that uses surrounding text to provide context to assist computers to interpret ambiguous words in the text.
Conclusion
So that's the end of the article.
In this article, we have extensively discussed LexRank.
After reading about the LexRank, are you not feeling excited to read/explore more articles on the topic of NLP? Don't worry; Coding Ninjas has you covered.




























 8+ registered
8+ registered 

