Do you think IIT Guwahati certified course can help you in your career?
Introduction
MongoDB, a leading NoSQL database, is renowned for its scalability, a critical feature in today's data-driven world. As businesses and applications grow, they generate enormous volumes of data, necessitating efficient management and storage solutions.
MongoDB addresses this challenge through two primary mechanisms: replication and sharding. Replication is designed to ensure data availability and redundancy, while sharding is focused on distributing data across multiple servers to manage large datasets efficiently.
Understanding Replication in MongoDB
What is Replication?
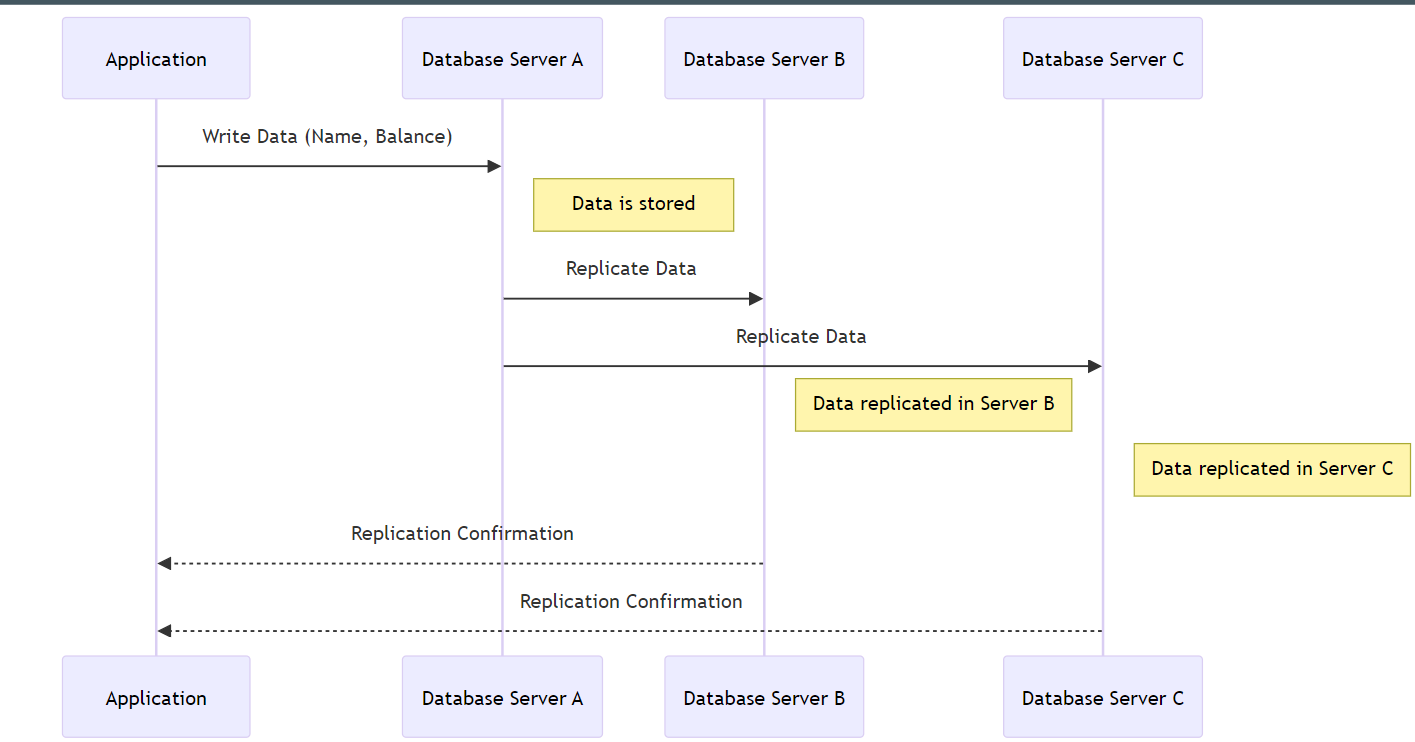
Replication in MongoDB involves creating multiple copies of the same data on different database servers. This approach not only ensures data safety and high availability but also facilitates load balancing for read operations across several servers.
Explanation-
The diagram begins with an application sending a request to store data to the main database.
The database then distributes parts of this data across multiple shards for storage.
Each shard confirms the storage back to the database.
Finally, the database confirms successful data storage back to the application.
Key Features of Replication
Data Redundancy: By creating multiple copies of data across different servers, replication ensures that in the event of a hardware failure, the data remains secure and available.
High Availability: Replication provides a mechanism for automatic failover. If the primary server fails, a secondary server takes over, minimizing downtime.
Read Scalability: Secondary replicas can handle read operations. This distributes the workload, allowing the system to serve more read queries without overloading the primary server.
Why Use Replication?
The primary rationale for using replication in MongoDB is to maintain uninterrupted data access. In scenarios of server failure, maintenance activities, or network issues, replication allows the database to continue functioning without significant impact on data integrity or availability.
How Replication is Formed
MongoDB uses a group of servers known as a replica set to achieve replication. In a replica set, one server acts as the primary server, handling all write operations, while the other servers, termed secondary nodes, replicate the data from the primary.
Creating Replica Sets in MongoDB
Creating a replica set in MongoDB involves starting multiple MongoDB instances and configuring them to communicate as part of the same group. This process is relatively straightforward and can be customized based on specific requirements like the number of nodes.
Example of Replication Setup
Suppose you want to set up a basic three-member replica set. You'd start by launching three MongoDB instances, each on a different port. For instance, you can use the following commands:
Sharding in MongoDB is a method for distributing data across multiple machines or 'shards'. This technique is essential for managing databases that exceed the capacity of a single server, enabling horizontal scaling and improved query response times.
The Importance of Sharding
As data volume grows, a single server might struggle with storage capacity or processing power, leading to degraded performance. Sharding mitigates this by dividing the data among multiple servers, each handling a manageable portion of the data, thereby enhancing overall performance and scalability.
How Sharding Works
MongoDB sharding involves dividing the dataset into smaller, more manageable chunks, each stored on different shards. The distribution of these chunks is managed automatically by MongoDB, ensuring a balanced load across the shards.
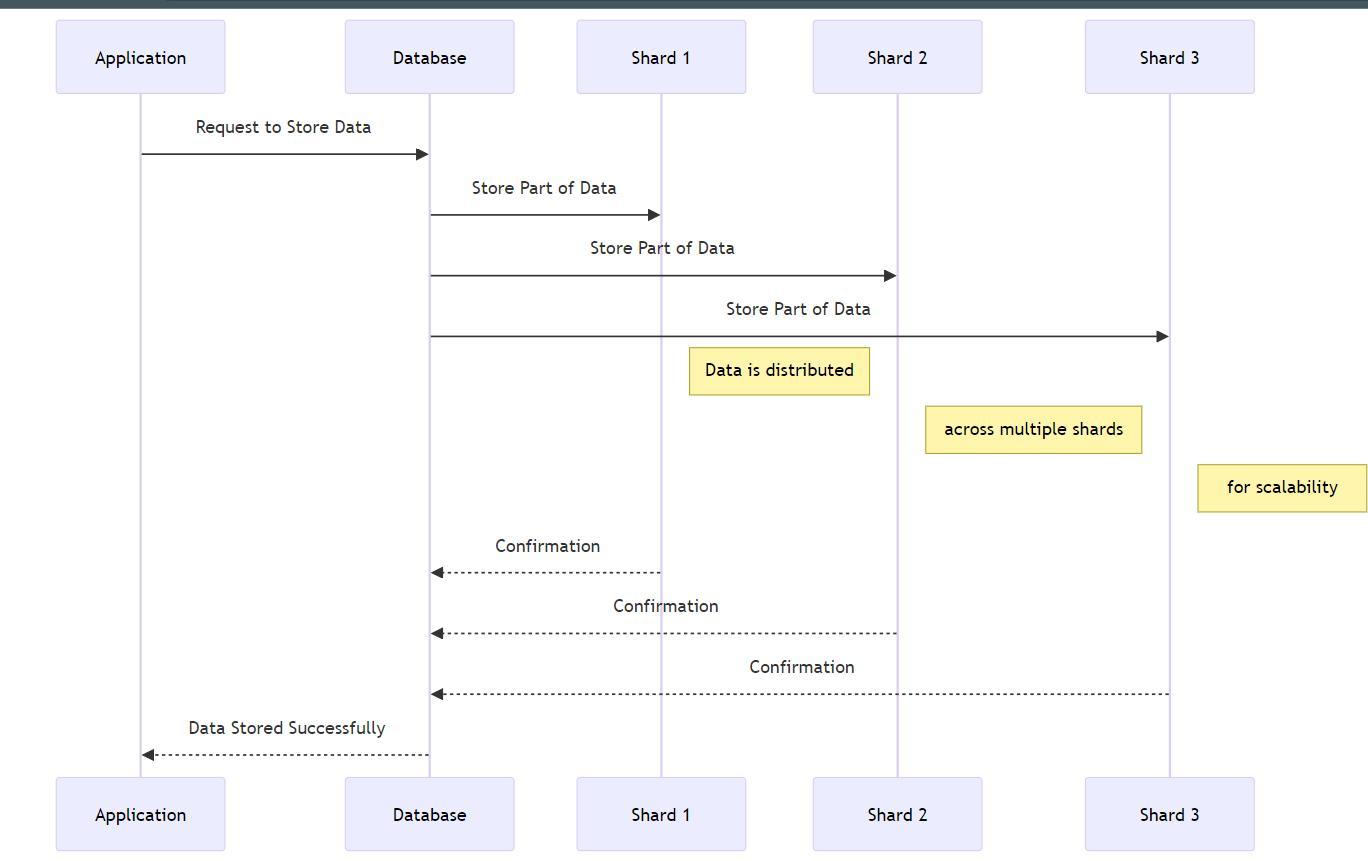
Explanation of diagram-
Application Request:
The process begins with an application that needs to store data. The application sends a request to the main database. This is represented by the line from "Application" to "Database" labeled "Request to Store Data."
Database Distributes Data:
Upon receiving the request, the main database takes the data and begins the process of sharding. Sharding is the division of data into smaller, more manageable pieces, known as shards. In this diagram, the database distributes the data across three different shards - Shard 1, Shard 2, and Shard 3. This is shown by the lines from "Database" to each of the shards.
Storage in Shards:
Each shard receives a portion of the data to store. This is indicated by the notes "Data is distributed," "across multiple shards," and "for scalability" next to Shard 1, Shard 2, and Shard 3, respectively. These notes emphasize that the data is split and stored across multiple locations, which is a key aspect of sharding for scalability and performance.
Confirmation of Storage:
After each shard stores its respective portion of the data, they send a confirmation back to the main database. This is represented by the lines from each shard back to the database, labeled "Confirmation."
Final Acknowledgment to Application:
Once the main database receives confirmations from all the shards, it sends a final acknowledgment back to the application, indicating that the data has been successfully stored. This is shown by the line from "Database" back to "Application," labeled "Data Stored Successfully."
The Role of Shards in MongoDB
In a sharded cluster, each shard is responsible for storing a specific subset of the data. To the application, these shards appear as a single database, but behind the scenes, they collectively store the entire dataset.
Routing Servers and Data Distribution
The Mongos process acts as a query router in a MongoDB sharded cluster. It understands the cluster's topology and routes each query to the appropriate shard(s) based on the shard key. This ensures efficient and accurate data retrieval.
Configuration Servers in Sharding
Configuration servers are crucial in a sharded MongoDB setup. They hold metadata about the cluster, like the structure of shards and the location of different data chunks. This information is vital for the cluster to operate correctly and efficiently.
Advantages of Sharding
Scalability: Sharding is the key to horizontal scaling, allowing a database to grow in capacity and throughput beyond the limits of a single server.
Performance: By distributing the data, sharding reduces the load on individual servers, leading to faster query responses and better overall performance.
High Availability: Sharding, in conjunction with replication, can significantly increase the availability and fault tolerance of the database system.
Setting Up Sharded Clusters in MongoDB
Setting up a sharded cluster involves several steps, including initializing configuration servers and adding shards to the cluster. For instance, you might start with the following commands:
Start the configuration servers (usually three for redundancy):
Add shards to the cluster using the sh.addShard command.
Frequently Asked Questions
Can MongoDB automatically handle replication and sharding?
While MongoDB automates the process of replication, setting up and managing a sharded environment requires initial configuration and ongoing management.
How does MongoDB decide to shard data?
MongoDB uses a sharding key, specified at the time of sharding setup, to distribute data across shards. This key determines how data is partitioned and distributed.
What happens if a primary server in a replica set fails?
If the primary server in a replica set fails, MongoDB automatically elects a new primary from the existing secondary nodes. This ensures continuous data availability and minimal interruption in operations.
Conclusion
MongoDB's approach to handling large-scale data through replication and sharding is a cornerstone of its popularity and effectiveness. Replication ensures data safety and availability, while sharding provides the means to scale horizontally, addressing the challenges of data growth.






























 8+ registered
8+ registered 

