Azure Synapse offers analytic capabilities that improve the time to breakthrough across data warehouses and big data platforms. It integrates the greatest SQL technology for enterprise data warehousing, as well as Data Explorer for log and time-series analytics, Pipelines, Power BI, CosmosDB and AzureML, and Spark Technology. In this blog, we will learn Azure Synapse SQL, its architecture components, azure storage, cloud node, compute node, data movement service and distributions. Let us dive into the topic.
Synapse SQL
Synapse SQL is a distributed query solution for Transact-SQL or T-SQL and an industry-leading SQL. It supports data warehouse and data visualization situations, as well as streaming and machine learning scenarios. It offers both serverless and dedicated resource models and has build-in capabilities to stream, i.e. fetches data from cloud data sources into SQL tables.
Synapse SQL Architecture Component
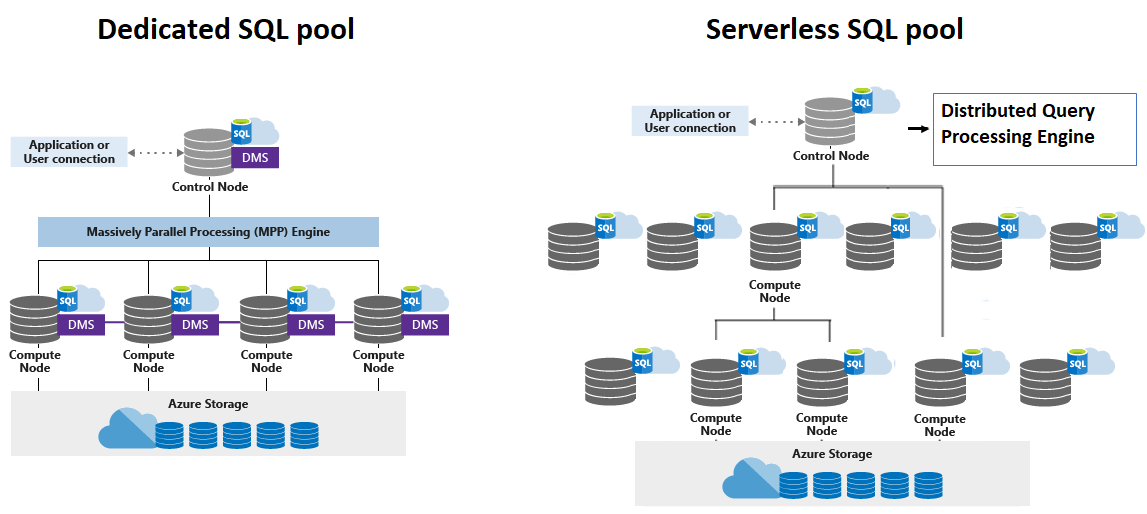
Synapse SQL has a scale-out architecture to distribute data processing across multiple nodes. Compute is distinct from storage, which enables to scale compute independently of the data in your system.
The unit of scale for a dedicated SQL pool is an abstraction of computational power known as a data warehouse unit and because the serverless SQL pool is serverless, scalability is done automatically to meet query resource requirements. In a serverless SQL pool, as topology changes by adding nodes, removing nodes or failures, it adapts to changes and makes sure the query has enough resources and finishes successfully.
Synapse SQL employs a node-based architecture in which Control nodes i.e. single entry points for Synapse SQL, are linked and T-SQL commands are executed. The control node optimizes queries for parallel processing using a distributed query engine and then sends operations to compute nodes to execute their job in parallel.
The serverless SQL pool Control node makes advantage of the Distributed Query Processing (DQP) engine to optimize and organize distributed execution of user queries by breaking them down into smaller queries that will be run on Compute nodes. The compute nodes are responsible for storing all user data in Azure Storage and doing parallel queries. The Data Movement Service (DMS) is an internal system service that transfers data across nodes as needed to run queries concurrently and properly.
When using Synapse SQL with decoupled storage and computation, you can benefit from independent sizing of computing power regardless of your storage requirements. Scaling is done automatically for serverless SQL pools, while for dedicated SQL pools, one can:
Increase/ Decrease compute power within a dedicated SQL pool without relocating data.
You only pay for storage if you pause computational capacity while leaving data intact.
During operational hours, resume computing capacity.
Azure Storage
Synapse SQL uses Azure Storage to protect your user data. Because your data is stored and managed by Azure Storage, your storage consumption is charged separately. You can query your data lake files using a serverless SQL pool, whereas a dedicated SQL pool can query and import data from your data lake files. When data is imported into a dedicated SQL pool, it is sharded into distributions to enhance effective system performance. When you define the table, you can specify which sharding pattern to employ to distribute the data. The following sharding patterns are supported:
Replicate
Hash
Round Robin
Cloud Node
The Control node is the architecture's brain. It is the front end that interacts with all applications and connections. The distributed query engine of Synapse SQL operates on the Control node to optimize and organize parallel queries. When you submit a T-SQL query to a dedicated SQL pool, the Control node converts it into queries that run in parallel against each distribution. The DQP engine operates on the Control node in a serverless SQL pool to optimize and coordinate distributed execution of user queries by breaking them into smaller queries that will be executed on Compute nodes. It also assigns groupings of files to each node for processing.
Compute Node
The computing power is provided by the compute nodes.Distributions are mapped to compute nodes in a dedicated SQL pool for processing. Pool remaps distributions to available compute nodes as you pay for extra compute resources. The dedicated SQL pool's service level determines the number of compute nodes, which spans from 1 to 60. Each Compute node has a unique node ID that may be seen in system views. Each Compute node in a serverless SQL pool is allocated a task and a set of files to execute the task on. The task is a distributed query execution unit that is part of the query that the user provided. Automatic scaling is in place to ensure that enough Compute nodes are available to execute user queries.
Data Movement Service
Data Movement Service (DMS) is a data transport solution that manages data movement across compute nodes in a dedicated SQL pool. Some searches necessitate data transfer in order for simultaneous queries to produce appropriate results. When the data transfer is required, DMS guarantees that the correct data is sent to the correct location.
Distributions
Distribution is the fundamental unit of storage and processing for parallel queries that operate on distributed data in a dedicated SQL pool. When a dedicated SQL pool conducts a query, the effort is divided into 60 smaller queries that run in parallel.
Distributed Tables
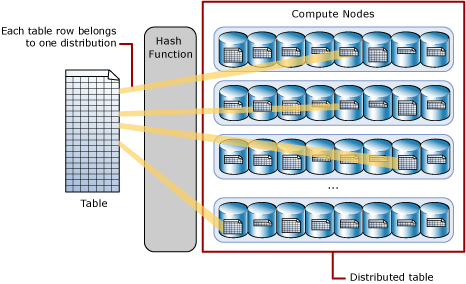
A hash distributed table can provide the best query performance for joins and aggregations on huge tables. A dedicated SQL pool utilizes a hash function to deterministically assign each row to one distribution while sharding data into a hash-distributed database.
Each row in a hash distributed table belongs to a single distribution.
A deterministic hash method assigns one distribution to each row.
The amount of table rows per distribution varies with table size.
A round-robin table is the simplest to build and provides rapid performance when used as a load staging table. A round-robin distributed table distributes data uniformly over the table but without further optimization. A distribution is picked at random, and then buffers of rows are assigned to distributions successively. Although it is faster to load data into a round-robin table, hash distributed tables frequently provide better query speed.
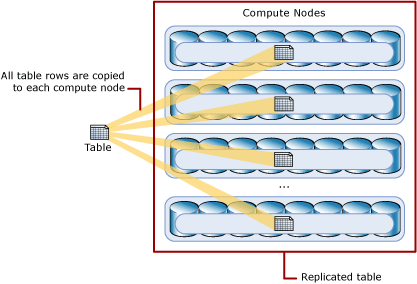
For small tables, the fastest query performance is provided by a replicated table. A replicated table stores a complete copy of the table on each computing node. As a result, duplicating a table eliminates the need for data to be transferred across compute nodes prior to a join or aggregate. With small tables, replicated tables work well.
Frequently Asked Questions
What is difference between Azure synapse and Azure SQL data warehouse?
Azure SQL database is a good fit for a data warehouse with a small data size and low volume data loads. It provides ease of maintenance, predictable cost and flexible RPOs. On the other hand, Azure Synapse with SQL pool is able to support a large data size for a data warehouse with greater complexity.
Is Synapse same as SQL Server?
Generally, Synapse SQL Pools are part of an Azure SQL Server instance and can be browsed using tools like SSMS as well.
Is Azure SQL Database free?
Using an Azure free account, you can try Azure SQL Database for free for 12 months
Conclusion
In this article, we have extensively discussed Azure Synapse SQL, its architecture components, azure storage, cloud node, compute node, data movement service and distributions. Having gone through this article, I am sure you must be excited to read similar blogs. Coding Ninjas has got you covered. Here are some similar blogs to redirect: How to Prepare for a Microsoft Azure Certification Exam?, Microsoft Azure, AWS Vs Azure Vs Google Cloud?, Microsoft Azure Certification. We hope that this blog has helped you enhance your knowledge, and if you wish to learn more, check out our Coding Ninjas Blog site and visit our Library. Here are some courses provided by Coding Ninjas: Basics of C++ with DSA, Competitive Programming and MERN Stack Web Development. Do upvote our blog to help other ninjas grow.
Happy Learning!
Live masterclass
Get hired as an Amazon SDE : Resume building tips
by Anubhav Sinha, SDE2 @ Amazon
05 Nov, 2024
01:30 PM
Google Data Analyst Roadmap: Get Practical Insights
by Maaheen Jaiswal, Data Analyst @ Google
30 Oct, 2024
01:30 PM
Get hired as an Amazon SDE : Resume building tips
by Anubhav Sinha, SDE2 @ Amazon
05 Nov, 2024
01:30 PM
Google Data Analyst Roadmap: Get Practical Insights




























 408+ registered
408+ registered 