Do you think IIT Guwahati certified course can help you in your career?
Introduction
Hey Ninjas! In Natural Language Processing, finding useful information from text is tough but crucial. PLSA is an effective tool for this task. It helps understand the hidden meaning of a document. Using a probabilistic framework, PLSA uncovers the hidden relationships between words and documents.
Let's dive into the details of PLSA.
Probabilistic Latent Semantic Analysis
Imagine having many documents but not enough time to read them all. How can you figure out what they are about? This is where Probabilistic Latent Semantic Analysis comes into play.
PLSA helps us comprehend how words and documents are related and what they mean. Each document has multiple topics, and each topic has its phrase.
Here's how it works:
Suppose you have a collection of documents about animals. PLSA can identify the main topics in documents, like "dogs", "cats", and "birds".
Then, it figures out which words are most important for each topic. If you want to identify the theme of a document, the PLSA algorithm can help. Let's say you have a "dog" theme, with words like "bark," "tail," and "fetch." A "cat" theme might have "meow," "purr," and "claws."
PLSA parses the words to determine which topic it belongs to. To do this, the words used are examined and compared with the words belonging to each topic.
PLSA uses probability to calculate that a document belongs to a particular topic. So if “barking” is mentioned a lot in a document, it's related to “dogs”.
PLSA is a tool that helps you organize and understand large amounts of information quickly.
Mathematical Foundations of PLSA
The PLSA model can be understood in two different ways.
Latent Variable Model
Matrix Factorization
But first, let's define the variables involved in PLSA:
Documents: D = {d1, d2, d3, ..., dN}, where N is the number of documents. Each document di is represented as a bag of words.
Words: W = {w1, w2, ..., wM}, where M is the vocabulary size. Each word represents a unique term.
Topics: Z = {z1, z2, ..., zK}, where K is the specified number of latent topics. Each topic corresponds to a theme or concept.
Latent Variable Model
PLSA, a model for hidden themes, assumes that these themes generate the words we see in a document. Each document is viewed as a mixture of these potential themes. The choice of theme determines the word composition.
The generative process of the LVM can be described using the following probabilities:
Symbol
Meaning
P(d)
Probability of selecting a document d.
P(z|d)
The Conditional probability of selecting a topic z given the document d.
P(w|z)
The Conditional probability of selecting a word w given the topic z.
To generate a word within a document, the model follows these steps:
Select a document d based on the probability distribution P(d).
Choose a topic z from the conditional distribution P(z|d).
Select a word w from the conditional distribution P(w|z).
Now let's look at the formulas of the latent variable model.
Common Probability
The chance of seeing a certain word, document, and topic is shown by P(w,d,z). We can find it using the probabilistic chain rule.
P(w, d, z) = P(w|z) * P(z|d) * P(d)
Marginal Probability
The marginal probability P(w) represents the probability of observing a word w. You can find it out by adding up the chance of each subject with every document.
P(w) = Σ P(w, d, z), for all d, z
Conditional Probability
P(z|d,w) is the probability of a subject z given a document d and word w. It can be calculated using Bayes' theorem.
P(z|d, w) = (P(w|z) * P(z|d)) / P(w)
P(w) is the marginal probability computed in the previous step.
Maximum Likelihood Estimation
PLSA aims to estimate the parameters P(w|z) and P(z|d). PLSA maximizes the likelihood of observations. You can estimate these numbers using the EM algorithm. Just repeat the process until you get the right answer.
The E-step computes the posterior probabilities P(z|d,w). It's computed using the conditional probability formula above.
The M-step updates the parameters P(w|z) and P(z|d). It's computed using the posterior probabilities computed from the E-step.
This iteration between the E-step and M-steps continues until convergence when the parameters reach stable values.
PLSA can help us find the main topics and words in a document by using the probabilities of P(w|z) and P(z|d).
The PLSA model has a math basis that uses formulas and an iterative EM algorithm. Thus, allowing us to infer text data's underlying latent topic structure.
Matrix Factorization
The main components and formulas of the matrix factorization model are:
A term document matrix represents the frequency of occurrence of words in a document.
It is usually denoted by A, and has N x M elements. Here M is the vocabulary size and N is the number of documents.
Element A(i,j) represents the number of occurrences of word j in document i.
We can visualize the matrix as shown below:
Factorization Matrix
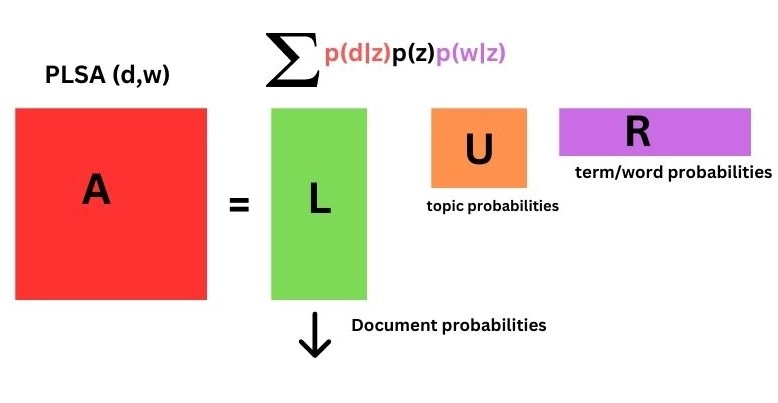
The term and document matrix A get broken down into three matrices by the matrix factorization model.
A ≈ L*U*R
Matrix L
The L matrix represents the distribution of documents and topics. It has dimension N x K. K is the specified number of latent topics. L has a row for each document's subject probability distribution.
Matrix U
The U matrix is a diagonal matrix of size K x K. This includes prior subject probabilities P(z), where z represents the subject.
Array R
The R matrix represents the distribution of topic words and has dimension K x M. R has columns representing the probability of words for each topic.
Probability Calculation
The probabilities associated with matrix factorization models can be computed as follows:
The chance of a topic in a document, P(d|z), comes from matrix L.
The chance of a word for a topic, P(w|z), comes from matrix R.
These probabilities represent relationships between documents, topics and words learned through factorization.
We can see the above formulations in the below diagram:
So, PLSA(d,w) will be equal to Σ p(d|z)p(z)p(w|z).
Extensions and Variations of PLSA
PLSA led to many different versions that fixed its problems.
Let's explore some of them in more detail.
Latent Dirichlet Allocation
LDA addresses the limitation of predefining the number of potential topics. LDA models topics as word distributions. It uses the Dirichlet precedence principle for these topics. This preset encourages economy; we expect each document to contain relevant topics. LDA is a model that creates categories based on the data. This helps it learn how many topics there are.
Supervised PLSA
PLSA is an unsupervised learning algorithm. It does not rely on externally tagged information. SPLSA extends PLSA by incorporating supervised information. This helps control the learning process. Achieving this goal is easy. It involves labeling documents or attaching class labels to them. SPLSA can monitor and improve topic modeling. This is especially true when labeled data is available.
Non-negative Matrix Factorization
NMF is a matrix factorization technique that can be viewed as a variation of PLSA. NMF uses non-negativity constraints on the factor matrix. So it can achieve more interpretable factorization. NMF is commonly used to model topics and is computationally efficient.
Author Topic Model
The Author Topic Model is an expansion of PLSA. It considers the author's role in topic modeling for a document. This idea is document subject is affected by both what the document says and what the author likes. An author-topic model can capture the way writers write by using authorship.
Applications of PLSA
PLSA can be useful in many areas that need to find hidden patterns in written information.
Let's take a closer look at some of the main uses of PLSA.
Theme Modeling
PLSA is best known for its application to topic modeling. The goal is to find out what subjects and ideas are in a set of documents.
PLSA can find the topics in a text by looking at how often words appear. This is useful for document clustering and text summarization tasks.
Information Recovery
PLSA makes search systems better by understanding the meaning of requests and files. PLSA helps to map documents and queries by presenting them in a subject space. PLSA helps rank documents based on how relevant they are to a search. This improves the accuracy of search results in applications.
Text Classification
PLSA can be applied to text classification. It assigns documents to predefined categories. Using latent topics, PLSA captures what a document is about. It then puts it in the right categories. This technique is useful in message classification and content filtering applications.
Image Annotation
PLSA has been extended to handle multimodal data such as text. PLSA can associate text descriptions or tags with images for image annotation tasks. By modeling visual content, PLSA bridges semantic gaps and improves understanding.
Frequently Asked Questions
How does PLSA handle word ambiguity or polysemy?
PLSA assumes that a single topic generates each word in a document. Therefore, it does not explicitly model word ambiguity. It might give more than one topic to a document if the writing is unclear.
Can PLSA handle languages other than English?
Yes, PLSA can handle languages other than English. This approach can work with any language. It looks at how often words appear together in a group of documents.
How can the number of topics in PLSA be determined?
The number of topics in PLSA is determined by manual selection or through heuristics. It involves experimenting with different numbers of topics. To improve the topics, we can check if they make sense and are easy to understand. We can do this by using metrics like coherence or human judgment.
Are there any open-source libraries or tools available for implementing PLSA?
Libraries and tools exist for using PLSA, like Genism and sci-kit-learn. These libraries provide implementations of PLSA and other topic modeling algorithms.
How can the performance of PLSA be evaluated?
It can be evaluated using metrics like topic coherence, perplexity, or human evaluation. In addition, you can check the quality of topics by looking at them and analyzing them intently.
Conclusion
In conclusion, PLSA is a valuable tool in NLP. It gives a way to understand the hidden meaning in written words. It models the relationships between documents, words, and latent topics.





























 5+ registered
5+ registered 

