Word2Vec Model
Word2Vec generates word vectors, which are distributed numerical representations of word features - these word features could be words that indicate the context of particular words in our vocabulary. Through the produced vectors, word embeddings eventually assist in forming the relationship of a term with another word with similar meaning.
Similar meaning words are closer in space, as demonstrated in the graphic below when word embeddings are plotted, suggesting semantic similarity.
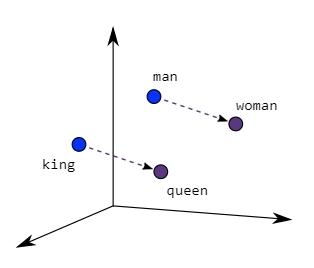
Img_src
Context is used in these models. This means that it looks at neighboring words to learn the embedding; if a set of words is always found close to the exact words, their embeddings will be similar.
To classify how words are similar or close to one another, we must first define the window size, which decides which neighboring terms we wish to select.
The Skip-Gram Continuous Bag of Words models is two distinct architectures that Word2Vec can build word embeddings.
General Algorithm
- Step-1: Initially, we will assign a vector of random numbers to each word in the corpus.
- Step-2: Then, we will iterate through each word of the document and grab the vectors of the nearest n-words on either side of our target word, concatenate all these vectors, and then forward propagate these concatenated vectors through a linear layer + softmax function, and try to predict what our target word was.
- Step-3: In this step, we will compute the error between our estimate and the actual target word and then backpropagate the error, and then modify the weights of the linear layer and the vectors or embeddings of our neighbor's words.
- Step-4: Finally, we will extract the weights from the hidden layer and, by using these weights, encode the meaning of words in the vocabulary.
The Word2Vec model, instead of being a single method, is made up of two preprocessing modules or techniques:
Skip-Gram with the Continuous Bag of Words (CBOW).
Both models are shallow neural networks that map words to a target variable (a word (s). The weights that operate as word vector representations are learned using these strategies. Using word2vec, both methods can be utilized to implement word embedding.
Working Of Word2Vec model
The Continuous Bag of Words (CBOW) and the Skip-Gram model architectures are two distinct model architectures that Word2Vec can employ to build word embeddings.
CBOW Model
Even though Word2Vec is an unsupervised model that can construct dense word embeddings from a corpus without any label information, Word2Vec internally uses a supervised classification model to extract these embeddings from the corpus.
The CBOW architecture includes a deep learning classification model that uses context words as input (X) to predict our target word, Y. Consider the following scenario: Have a wonderful day.
Let the word "excellent" by the input to the Neural Network. It's important to note that we're attempting to predict a target word (day) from a single context input word, amazing. More specifically, we compare the output error of the one-hot encoding of the input word to the one-hot encoding of the target word (day). We learn the vector representation of the target word as part of the prediction process.
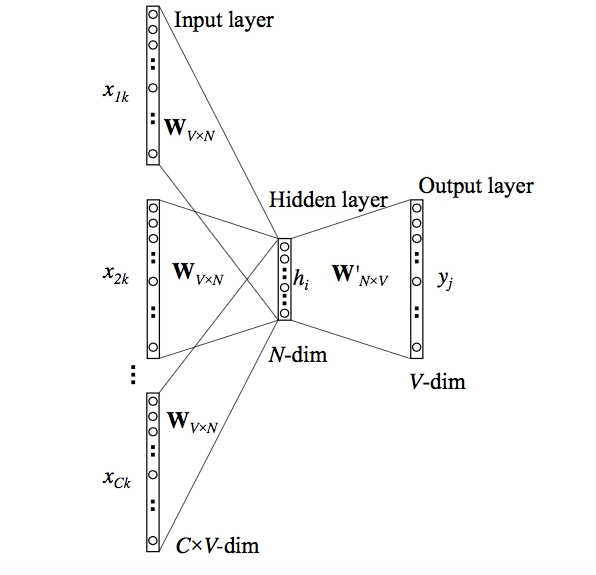
img_src
Steps
The model's operation is described in the steps below:
- As indicated in the Figure below, the context words are initially supplied as an input to an embedding layer.
- The word embeddings are then transferred to a lambda layer, where the word embeddings are averaged.
- The embeddings are then passed to a dense SoftMax layer, predicting our target word. We compute the loss after matching this with our target word and then run backpropagation with each epoch to update the embedding layer in the process.
Once the training is complete, we may extract the embeddings of the required words from our embedding layer.
Advantages
CBOW has the following advantages:
- It is generally thought to outperform deterministic approaches because to its probabilistic character.
- It does not necessitate a large amount of RAM. As a result, it has a low memory capacity.
Disadvantages
CBOW has the following drawbacks:
- It averages the context of a word. Consider the word apple, which can refer to both a fruit and a company, but CBOW averages the two meanings and places it in a cluster for both fruits and companies.
- If we wish to train a CBOW model from scratch, it can take longer if we don't optimize it effectively.
So far, we've seen how context words are used to construct word representations. However, there is another way we can achieve the same. We may anticipate the context using the target word (whose representation we wish to build) and generate the representations in the process. Another variety, known as the Skip Gram model, does this.
Skip Gram Model
The context words are predicted in the skip-gram model given a target (center) word. Consider the following sentence: "Word2Vec uses a deep learning model in the backend." Given the center word 'learning' and a context window size of 2, the model tries to predict ['deep,' 'model'], and so on.
We feed the skip-gram model pairs of (X, Y), where X is our input and Y is our label because the model has to predict many words from a single provided word. This is accomplished by creating positive and negative input samples.
These samples alert the model to contextually relevant terms, causing it to construct similar embeddings for words with similar meanings. This appears to be a multiple-context CBOW model that has been flipped. To a degree, this is correct.
The target term is entered into the network. The model generates C probability distributions. What exactly does this imply?
We receive C probability distributions of V probabilities for each context position, one for each word.
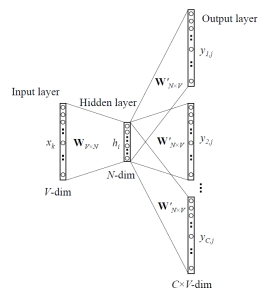
Img_src
Steps
The model's operation is described in the steps below:
- Individual embedding layers are passed both the target and context word pairs, yielding dense word embeddings for each of these two words.
- The dot product of these two embeddings is computed using a 'merge layer,' and the dot product value is obtained.
- The value of the dot product is then transmitted to a dense sigmoid layer, which outputs 0 or 1.
- The output is compared to the actual value or label, and the loss is calculated, then backpropagation is used to update the embedding layer at each epoch.
Advantages
The Skip-Gram Model has the following advantages:
- 1. It can capture two interpretations for a single word. In other words, there are two vector representations of the word Apple. One is for the business, while the other is for the fruit.
- 2. Skip-gram with negative subsampling outperforms all other methods in general.
Both CBOW and skip-gram have their own set of benefits and drawbacks. Skip Gram, according to Mikolov, works well with limited amounts of data and is shown to represent unusual words accurately.
CBOW, on the other hand, is speedier and provides better representations for terms that are used more frequently.
Implementation
Installing Modules
pip install gensim
pip install nltk

You can also try this code with Online Python Compiler
Importing Modules
from nltk.tokenize import sent_tokenize, word_tokenize
import gensim
from gensim.models import Word2Vec
You can also try this code with Online Python Compiler
Reading the text data
import pandas as pd
df = pd.read_csv(r"reviews.csv")
You can also try this code with Online Python Compiler
Preparing the Corpus
Now, we create the list of the words that our corpus has.
corpus = 'n'.join(df[:1000]['Text'])
data = []
# iterating through each sentence in the file
for i in sent_tokenize(corpus):
temp = []
# tokenize the sentence into words
for j in word_tokenize(i):
temp.append(j.lower())
data.append(temp)
You can also try this code with Online Python Compiler
Building the model using genism
To create the word embeddings using CBOW architecture or Skip Gram architecture, you can use the following respective lines of code:
model1 = gensim.models.Word2Vec(data, min_count = 1,size = 100, window = 5, sg=0)
model2 = gensim.models.Word2Vec(data, min_count = 1, size = 100, window = 5, sg = 1)
You can also try this code with Online Python Compiler
That's the basic implementation of the word2vec model using the genism module.
FAQs
-
What are the drawbacks of Word2Vec?
Word2Vec struggles with words that aren't in the dictionary. OOV words assign a random vector representation, which can be unsatisfactory. It is based on word information from the native language.
-
What can you do with Word2Vec?
The Word2Vec model is used to extract concepts like semantic relatedness, synonym recognition, concept classification, selectional preferences, and analogies from words or items. A Word2Vec model discovers meaningful relationships and converts them into vector similarities.
-
What is Word2Vec so important?
Word2vec's objective and use are to the group in vector-space the vectors of similar words. In other words, it uses math to find similarities. Word2vec generates vectors numerical representations of word properties such as context.
-
What exactly is the Skip-gram model?
Skip-gram is one of the unsupervised learning strategies for finding the most similar words for a given term. Skip-gram is a technique for predicting the context word for a target word. It's the opposite of the CBOW algorithm. The target word is entered, and the context words are displayed.
-
How do you go about putting Word2Vec into action?
There are two flavors of Word2Vec to choose from continuous Bag-Of-Words (CBOW) or continuous Skip-gram (SG). In a nutshell, CBOW tries to guess the output (target word) from its surrounding words (context words), whereas continuous Skip-Gram tries to guess the context words from the target word.
Key Takeaways
Let us brief out the article.
Firstly, we saw the purpose of using word2vec, basic definition, and all. Moving on, we saw the general algorithm followed for creating a word2vec model. Later, we saw the working of the word2vec model and two different algorithms to achieve the same. Lastly, we saw the basic implementation of the same. That's all from the article.
I hope you all like it.
Do not worry if you want to have in-depth knowledge of different techniques. We have a perfect tutor to help you out.
Happy Learning Ninjas!




























 8+ registered
8+ registered 

