Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
In our fast-paced digital age, the ability to organize and interpret vast amounts of data is not just a skill but a necessity. One fascinating aspect of data science, especially for those with a keen interest in machine learning, is the concept of clustering. Clustering involves grouping sets of objects in such a way that objects in the same group are more similar to each other than to those in other groups. Among the various clustering techniques, agglomerative clustering stands out for its approach and applications.
This article aims to smplify agglomerative clustering, providing insights into how it functions and its significance in machine learning. We’ll explore hierarchical clustering, will talk about the mechanics of agglomerative clustering, and understand its implementation through practical examples.
Hierarchical Clustering in Machine Learning
When we talk about hierarchical clustering, we're referring to a method of cluster analysis which seeks to build a hierarchy of clusters. In machine learning, it's a popular technique used for grouping data points without having to pre-specify the number of clusters to be generated.
Unlike other clustering methods, hierarchical clustering doesn't just find a single partitioning of the dataset but rather a hierarchy of clusters that can be represented as a tree (or dendrogram). This tree structure can be incredibly insightful, showing not only how the data points are grouped but also how they're related in the broader structure.
One key advantage of hierarchical clustering is its flexibility. It can adapt to various kinds of data and research questions, making it a valuable tool in any data scientist's arsenal.
Agglomerative Hierarchical Clustering
Now, let's zoom into agglomerative clustering, a specific type of hierarchical clustering. In simple terms, agglomerative clustering is a "bottom-up" approach. Each data point starts in its own cluster, and pairs of clusters are merged as one moves up the hierarchy.
The process of agglomerative clustering can be broken down into several steps:
Initialization: Start by treating each data point as a single cluster. So, if you have N data points, you initially have N clusters.
Finding the Closest Clusters: Calculate the distance between all pairs of clusters and find the pair that's closest.
Merging Clusters: Combine the closest pair of clusters into a single cluster.
Updating the Distance Matrix: After merging, update the distance matrix to reflect the distances between the new cluster and each of the old clusters.
Repeating: Repeat steps 2 to 4 until all data points are clustered into a single group.
The key to understanding agglomerative clustering lies in the distance measure used to determine the closeness of clusters. Common measures include Euclidean distance, Manhattan distance, and more complex methods like Ward's method.
How Agglomerative Hierarchical Clustering Works
Understanding how agglomerative hierarchical clustering works is essential for anyone diving into the world of machine learning. This clustering technique is like putting together a puzzle, where each piece finds its place based on similarity and proximity to others.
Starting with Individual Points:
Imagine you have a scatter plot of data points. Initially, each point is considered a separate cluster. If you have 100 points, you start with 100 clusters.
Measuring Distances:
The next step is to determine how close these clusters are to each other. This is done using distance measures like the Euclidean distance (think of it as the straight-line distance between two points on a graph).
Pairing Up
The algorithm then finds the two closest clusters and pairs them up, reducing the total number of clusters by one. So, from 100 clusters, you now have 99.
Creating a Dendrogram
Each time two clusters merge, this action is represented in a tree-like diagram called a dendrogram. This dendrogram is a visual representation of the clustering process, showing at what distance each pair of clusters merged.
Repeating the Process
This process of finding the closest clusters and merging them continues until all the data points form a single cluster. The order and level at which these merges occur are crucial in understanding the data's structure.
Deciding Cluster Numbers
One critical decision in agglomerative clustering is determining the number of clusters that best represents the data. This is often done by analyzing the dendrogram and identifying a level where the merge distances suddenly increase, indicating a natural division in the data.
Practical Implementation
To see agglomerative clustering in action, let's consider an example using Python and the Scikit-learn library. Here's a simple code snippet:
Python
Python
from sklearn.cluster import AgglomerativeClustering
import numpy as np
# Sample data
X = np.array([[1, 2], [1, 4], [1, 0],
[4, 2], [4, 4], [4, 0]])
# Initialize the model
clustering = AgglomerativeClustering().fit(X)
# Print cluster labels for each point
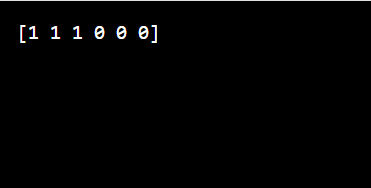
print(clustering.labels_)
You can also try this code with Online Python Compiler
In this example, we create a small dataset X and apply agglomerative clustering. The print statement outputs the cluster label for each data point, showing how the algorithm grouped the data.
Frequently Asked Questions
What is the main advantage of using agglomerative clustering?
Agglomerative clustering is flexible in handling various data shapes and sizes, making it ideal for exploratory data analysis.
How does agglomerative clustering differ from K-means clustering?
Unlike K-means, which partitions the data into a predetermined number of clusters, agglomerative clustering gradually merges data points based on their proximity, creating a hierarchy of clusters.
Can agglomerative clustering handle large datasets effectively?
Agglomerative clustering can be computationally intensive with large datasets due to its pairwise distance calculations, making it less efficient for very large data volumes.
Conclusion
Agglomerative clustering stands out in the realm of machine learning for its unique approach to data grouping. It doesn’t just lump data points together; it builds a story of their relationships, layer by layer, giving us deeper insights into the inherent structures within the data. This method’s flexibility and the rich hierarchical structure it provides make it a powerful tool for exploratory data analysis.































 8+ registered
8+ registered 

