Do you think IIT Guwahati certified course can help you in your career?
Introduction
In natural language processing (NLP) and word embedding techniques, Continuous Bag-of-Words (CBOW) and Skip-Gram are two popular algorithms used for generating word embeddings from large text corpora. Both approaches are part of the Word2Vec model, developed by Tomas Mikolov et al. at Google. In this blog, we'll delve into the differences between CBOW and Skip-Gram.
Word Embedding
Word Embedding is a technique used in natural language processing (NLP) to represent words as dense vectors of real numbers in a high-dimensional space. These vectors capture semantic relationships between words, allowing machines to understand and process language more effectively.
In word embedding, each word is mapped to a continuous vector in a multidimensional space, where words with similar meanings are closer together, and dissimilar words are farther apart. This representation enables algorithms to capture the contextual meaning of words based on their usage in a corpus of text.
CBOW Model
Even though Word2Vec is an unsupervised model that can construct dense word embeddings from a corpus without any label information, Word2Vec internally uses a supervised classification model to extract these embeddings from the corpus.
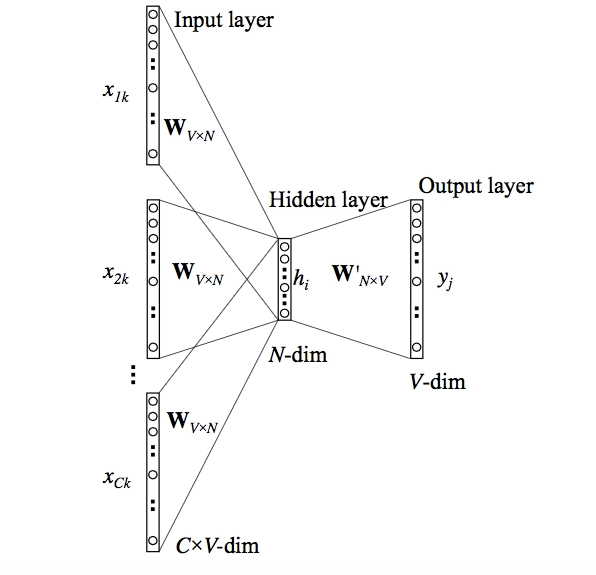
The CBOW architecture includes a deep learning classification model that uses context words as input (X) to predict our target word, Y. Consider the following scenario: Have a wonderful day.
Let the word "excellent" be the input to the Neural Network. It's important to note that we're attempting to predict a target word (day) from a single context input word, unique. More specifically, we compare the output error of the one-hot encoding of the input word to the one-hot encoding of the target word (day). We learn the vector representation of the target word as part of the prediction process.
The model's operation is described in the steps below:
As indicated in the Figure below, the context words are initially supplied as an input to an embedding layer.
The word embeddings are then transferred to a lambda layer, where the word embeddings are averaged.
The embeddings are then passed to a dense SoftMax layer, predicting our target word. We compute the loss after matching this with our target word and then run backpropagation with each epoch to update the embedding layer in the process.
Once the training is complete, we may extract the embeddings of the required words from our embedding layer.
Advantages
CBOW has the following advantages:
It is generally thought to outperform deterministic approaches because of its probabilistic character.
It does not necessitate a large amount of RAM. As a result, it has a low memory capacity.
Disadvantages
CBOW has the following drawbacks:
It averages the context of a word. Consider the word apple, which can refer to both a fruit and a company, but CBOW averages the two meanings and places it in a cluster for both fruits and companies.
If we wish to train a CBOW model from scratch, it can take longer if we don't optimize it effectively.
So far, we've seen how context words are used to construct word representations. However, there is another way we can achieve the same. We may anticipate the context using the target word (whose representation we wish to build) and generate the representations in the process. Another variety, known as the Skip Gram model, does this.
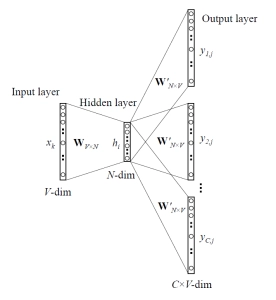
The context words are predicted in the skip-gram model given a target (center) word. Consider the following sentence: "Word2Vec uses a deep learning model in the backend." Given the center word 'learning' and a context window size of 2, the model tries to predict ['deep,' 'model'], and so on.
We feed the skip-gram model pairs of (X, Y), where X is our input and Y is our label, because the model has to predict many words from a single provided word. This is accomplished by creating positive and negative input samples.
These samples alert the model to contextually relevant terms, causing it to construct similar embeddings for words with similar meanings. This appears to be a multiple-context CBOW model that has been flipped. To a degree, this is correct.
The target term is entered into the network. The model generates C probability distributions. What exactly does this imply?
We receive C probability distributions of V probabilities for each context position, one for each word.
Steps
The model's operation is described in the steps below:
Individual embedding layers are passed both the target and context word pairs, yielding dense word embeddings for each of these two words.
The dot product of these two embeddings is computed using a 'merge layer,' and the dot product value is obtained.
The value of the dot product is then transmitted to a dense sigmoid layer, which outputs 0 or 1.
The output is compared to the actual value or label, and the loss is calculated, then backpropagation is used to update the embedding layer at each epoch.
Advantages
The Skip-Gram Model has the following advantages:
1. It can capture two interpretations for a single word. In other words, there are two vector representations of the word Apple. One is for the business, while the other is for the fruit.
2. Skip-gram with negative subsampling outperforms all other methods in general.
Both CBOW and skip-gram have their own set of benefits and drawbacks. Skip Gram, according to Mikolov, works well with limited amounts of data and is shown to represent unusual words accurately.
CBOW, on the other hand, is speedier and provides better representations for terms that are used more frequently.
Disadvantages
The Skip-Gram model, a popular word embedding technique, has several disadvantages:
Training Complexity: Skip-Gram requires training a separate model for each target word, resulting in increased computational complexity compared to Continuous Bag-of-Words (CBOW). This complexity can lead to longer training times, especially for large vocabularies and datasets.
Sparse Representations: Skip-Gram often produces sparse word embeddings, particularly for infrequent or out-of-vocabulary words. Since Skip-Gram generates embeddings independently for each word, words with limited context in the training data may have less meaningful representations.
Limited Context: Skip-Gram focuses solely on predicting neighboring words given a target word, which may result in embeddings that capture limited contextual information. In contexts where word order is crucial, such as syntactic or grammatical analysis, Skip-Gram may not capture long-range dependencies effectively.
Noise Sensitivity: Skip-Gram is more sensitive to noise in the training data compared to CBOW. Since it attempts to predict multiple context words for each target word, noisy or irrelevant context words can negatively impact the quality of the learned embeddings.
Difficulty in Handling Polysemy: Polysemous words, which have multiple meanings depending on context, can pose challenges for Skip-Gram. Since Skip-Gram treats each occurrence of a word as a distinct entity, it may struggle to disambiguate between different senses of a word, resulting in less precise embeddings.
Large Memory Footprint: Skip-Gram models often require storing large matrices for word embeddings, especially in scenarios with extensive vocabularies and high-dimensional embedding spaces. This large memory footprint can be impractical for deployment in memory-constrained environments or on resource-limited devices.
CBOW Vs Skip-Gram
CBOW (Continuous Bag-of-Words) and Skip-Gram are two popular algorithms for generating word embeddings in natural language processing (NLP). CBOW predicts a target word based on its context words, while Skip-Gram predicts context words given a target word. CBOW is faster to train and tends to perform well with frequent words, making it suitable for smaller datasets. In contrast, Skip-Gram is more effective with rare words and captures better semantic relationships between words. However, Skip-Gram requires more computational resources and training time due to its task complexity. Ultimately, the choice between CBOW and Skip-Gram depends on the specific requirements of the NLP task and the characteristics of the dataset being used.
Representation Of Word Embeddings
One-hot Encoding
One-hot encoding is a typical representation. Each word is encoded using a distinct vector in this manner. The number of words is equal to the size of the vectors. As a result, if there are 1.000 words, the vectors are 1x1.000 in size. Except for a value one that distinguishes each word representation, all values in the vectors are zeros. Each word is given its vector, but this representation has its problems.
To begin with, if the vocabulary is extensive, the vectors will be enormous. Employing a model with this encoding would result in the curse of dimensionality. Adding or removing terms from the vocabulary will also affect the display of all words.
Word2Vec
Word2Vec generates word vectors, which are distributed numerical representations of word features - these word features could be words that indicate the context of particular words in our vocabulary. Through the produced vectors, word embeddings eventually assist in forming the relationship of a term with another word with a similar meaning. Context is used in these models. This means that it looks at neighboring words to learn the embedding; if a set of words is always found close to the exact words, their embeddings will be similar.
To classify how words are similar or close to one another, we must first define the window size, which decides which neighboring terms we wish to select.
The Skip-Gram and Continuous Bag of Words models are two distinct architectures that Word2Vec can build word embeddings.
Frequently Asked Questions
Why do skip-gram models outperform CBOW models for unusual words?
There is no averaging of embedding vectors in skip-gram. When the vectors of rare words are not averaged with the other context words in the prediction process, it appears that the model can acquire superior representations for them.
Should I use CBOW or skip-gram?
Skip-gram performs well with a limited quantity of training data and can accurately represent even uncommon words or phrases. CBOW: faster to train than skip-gram, with better accuracy for frequent words.
What is CBOW and Skip-Gram?
CBOW predicts a target word from its context, while Skip-Gram predicts context words from a target word.
When to use Skip-Gram?
Use Skip-Gram for capturing semantic relationships among rare words in large datasets.
Why is Skip-Gram better than CBOW?
Skip-Gram excels in capturing semantic nuances and relationships among words, particularly with rare words, albeit with higher computational cost.
Does Word2Vec use CBOW?
Yes, Word2Vec includes implementations for both CBOW and Skip-Gram algorithms to generate word embeddings in NLP tasks.
Conclusion
In this article, we learn about word-embedding, the reason behind using word-embedding, and the different representations of word embeddings,i.e., one-hot encoding and word2vec. Finally, we saw the CBOW and Skip-gram model in detail, highlighting the specific differences between the two in between. Thus, both the techniques have advantages and disadvantages and can be used depending on the condition.
I hope you all like this article. Want to learn more about Data Analysis? Here is an excellent course that can guide you in learning. Can also refer to our Machine Learning course.






























 6+ registered
6+ registered 

