Do you think IIT Guwahati certified course can help you in your career?
Introduction
In machine learning, a cost function measures how well a model's predictions match the actual data. It's a crucial tool for training algorithms, helping them improve by minimizing errors.
This article will explain what a cost function is, why it's essential, and the different types used for various machine learning tasks, including regression and classification.
What is Cost Function?
A cost function, or loss function, measures the difference between predicted and actual values in a model. The objective during training is to reduce this difference to enhance accuracy. The cost function plays a key role in the optimization process by highlighting how far the model's predictions deviate from the true values, guiding improvements.
Why Use Cost Function?
Cost functions are important for several reasons:
Model Training: They help assess a model's performance and direct the optimization process.
Error Measurement: They measure errors, enabling adjustments to enhance model accuracy.
Model Comparison: They allow comparing different models to identify which one works best.
Types of Cost Function
Cost functions vary depending on the type of machine learning task. Here, we'll cover the most common types used in regression and classification.
Regression Cost Function
For regression tasks, the cost function evaluates how closely a model’s predicted continuous values align with the actual values. Common cost functions for regression include Mean Error, Mean Squared Error (MSE), and Mean Absolute Error (MAE).
Mean Error
The Mean Error is a simple calculation of the average difference between predicted and actual values. Unlike MSE, which squares the errors, the Mean Error takes the direct average without squaring, offering a more straightforward measure of bias in the predictions.
Formula:
Where:
nis the number of samples
yi is the actual value
y^i is the predicted value
Example Code:
Python
Python
import numpy as np
# Actual values
y_true = np.array([3, -0.5, 2, 7])
# Predicted values
y_pred = np.array([2.5, 0.0, 2, 8])
# Mean Error
mean_error = np.mean(y_true - y_pred)
print(f"Mean Error: {mean_error}")
You can also try this code with Online Python Compiler
Explanation: The Mean Error for this example is -0.25. This value indicates the average error in the predictions. A negative Mean Error suggests that the model tends to predict values that are lower than the actual values on average. Unlike MSE or MAE, the Mean Error can be positive or negative, which means it can sometimes mask the size of the errors.
Mean Squared Error (MSE)
MSE calculates the average of the squares of the errors—i.e., the average squared difference between predicted and actual values.
Formula:
Where:
n is the number of samples
yi is the actual value
y^i is the predicted value
Example Code:
Python
Python
import numpy as np
# Actual values
y_true = np.array([3, -0.5, 2, 7])
# Predicted values
y_pred = np.array([2.5, 0.0, 2, 8])
# Mean Squared Error
mse = np.mean((y_true - y_pred) ** 2)
print(f"Mean Squared Error: {mse}")
You can also try this code with Online Python Compiler
Explanation: The MSE for this example is 0.375. This value indicates the average squared error between the actual and predicted values. Lower MSE values suggest a better fit.
Mean Absolute Error (MAE)
MAE calculates the average of the absolute differences between predicted values and actual values.
Formula:
Example Code:
Python
Python
import numpy as np
# Actual values
y_true = np.array([3, -0.5, 2, 7])
# Predicted values
y_pred = np.array([2.5, 0.0, 2, 8])
# Mean Absolute Error
mae = np.mean(np.abs(y_true - y_pred))
print(f"Mean Absolute Error: {mae}")
You can also try this code with Online Python Compiler
Explanation: The MAE is 0.5, representing the average absolute error. MAE provides a more interpretable measure of error, with lower values indicating better model performance.
Binary Classification Cost Functions
For binary classification tasks, where the goal is to predict one of two classes, the cost function evaluates how accurately the model predicts the probability of class membership.
Binary Cross-Entropy Loss
Also called logistic loss, this function calculates the performance of a classification model that outputs a probability between 0 and 1.
Explanation: The Categorical Cross-Entropy Loss of 1.1379 reflects how well the model's predicted probabilities align with the actual class labels.
Gradient Descent
Gradient descent is a fundamental optimization algorithm used in machine learning to minimize the cost function. Here's an overview of how it is used with different cost functions for linear regression and neural networks, as well as a Python implementation guide:
1. Gradient Descent: Minimizing the Cost Function
Gradient descent is an optimization technique that iteratively updates model parameters to minimize the cost function. The general update rule for parameters is:
Where:
θ Model parameters.
α: Learning rate, which controls how large the step is during each iteration.
J(θ): The cost function (a measure of how wrong the model is).
∇θJ(θ): The gradient of the cost function with respect to the parameters θ\thetaθ.
The algorithm calculates the gradient of the cost funWhere:
hθ is the hypothesis or prediction function, often defined as hθ(x).
xi: Input features of the i-th training example.
yi : Actual output for the i-th training example.
m: Total number of training examples.ction and moves the parameters in the direction that minimizes the cost (steepest descent).
2. Cost Function for Linear Regression
For linear regression, the most common cost function is the Mean Squared Error (MSE). MSE measures the average squared difference between predicted and actual values, helping to minimize prediction errors.
The MSE cost function is defined as:
Where:
hθ is the hypothesis or prediction function, often defined as hθ(x)=θTx.
xi: Input features of the i-th training example.
yi: Actual output for the i-th training example.
m: Total number of training examples.
3. Cost Function for Neural Networks
For neural networks, particularly in classification tasks, the Cross-Entropy Loss is often used. This loss measures how well the predicted probabilities of the network match the actual labels.
The cross-entropy cost function is:
Where:
K: The number of classes.
yi: Binary indicator (0 or 1) for whether class kkk is the correct label for instance i.
y^ik: Predicted probability that the instance iii belongs to class k.
m: The number of training examples.
4. Implementing Cost Functions in Python
Below is the implementation of both MSE and cross-entropy cost functions in Python:
Python
Python
import numpy as np
# Mean Squared Error for Linear Regression def mse_cost_function(X, y, theta): m = len(y) predictions = X.dot(theta) return (1 / (2 * m)) * np.sum((predictions - y) ** 2)
# Cross-Entropy Loss for Neural Networks def cross_entropy_cost_function(y_true, y_pred): m = y_true.shape[0] epsilon = 1e-15 y_pred = np.clip(y_pred, epsilon, 1 - epsilon) # To avoid log(0) return -np.sum(y_true * np.log(y_pred)) / m
# Example usage:
# For Linear Regression (MSE) X = np.array([[1, 2], [1, 3], [1, 4]]) # Including bias term y = np.array([5, 6, 7]) theta = np.array([0.1, 0.2]) print("MSE:", mse_cost_function(X, y, theta))
MSE: This cost function calculates the average squared difference between the predicted and actual values for linear regression tasks. The smaller the MSE, the better the model fits the data.
Cross-Entropy Loss: It measures how close the predicted probabilities are to the actual classes in classification problems, commonly used in neural networks. The lower the cross-entropy, the better the model.
Both cost functions are critical for optimization algorithms like gradient descent, which aim to minimize the cost and improve model performance over time.
Frequently Asked Questions
What is a cost function in machine learning?
A cost function measures how well a machine learning model's predictions match the actual values. It helps guide the optimization process to improve model accuracy.
Why is the Mean Squared Error (MSE) used?
MSE is used to quantify the average squared difference between predicted and actual values, which helps in minimizing prediction errors in regression tasks.
How do different cost functions affect model training?
Different cost functions assess model performance in various ways, shaping how the model learns. For example, MSE penalizes larger errors more heavily than Mean Absolute Error (MAE), while binary cross-entropy is used in binary classification tasks to evaluate how well predicted probabilities align with actual binary labels. Choosing the appropriate cost function ensures the model is trained effectively and enhances its performance for the task at hand.
Conclusion
In this article, we learned various cost functions in machine learning, including Mean Error, Mean Squared Error (MSE), Mean Absolute Error (MAE), along with cost functions for classification tasks like Binary Cross-Entropy and Categorical Cross-Entropy. Each cost function offers a unique approach to evaluating model performance, helping to guide the training process and improve accuracy. Understanding these cost functions is essential for choosing the right one for specific machine learning tasks and optimizing model performance.
You can also check out our other blogs on Code360.





























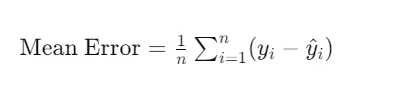





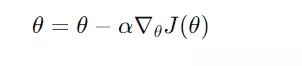




 9+ registered
9+ registered 

