


























Introduction
GloVe represents global vectors for word representation. It is an unaided learning calculation created by Stanford for producing word embeddings by totalling the global word-word co-event network from a corpus.
The fundamental thought behind the GloVe word inserting is to determine the connection between the words from insights. This process is not at all like the event grid, instead, the co-event framework lets us know how frequently a specific word pair happens together. Each worth in the co-event grid addresses a couple of words happening together.
GloVe Implementation
On a fundamental level, all the language models created endeavoured towards accomplishing one average goal which is achieving the chance of progressive learning in NLP. Along these lines, different instructive and business associations looked for changed approaches to accomplishing this objective.
One such conspicuous and all-around demonstrated approach was building a co-event framework for words given an enormous corpus. This approach was taken up by a group of specialists at Stanford University, which ended up being one basic yet compelling strategy for separating word embeddings for a given word.
The GloVe model is prepared on the non-sections of a global word-word co-event grid, which organizes how often words co-happen with each other in a given corpus. Populating this lattice requires a solitary pass through the whole corpus to gather insights. For massive corporations, this pass can be computationally costly. However, it is a one-time straightforward expense. The resulting preparing cycles are much quicker because the quantity of non-zero network sections is commonly a lot more modest than the absolute number of words in the corpus.
The apparatuses given in this bundle mechanize the assortment and readiness of co-event measurements for input into the model. The centre preparation code is isolated from these preprocessing steps and can be executed freely
Word embeddings
Word Embeddings are vector representations of words that assist us with separating straight foundations and interacting with the message so that the model would better comprehend. Regularly, word embeddings are loads of the hidden layer of the brain network engineering after the characterized model unites on the expense work.
Co-occurrence matrix
A co-event framework or co-event conveyance (likewise alluded to as dim level co-event networks GLCMs) is a grid characterized over a picture to be the dispersion of co-happening pixel values (grayscale values, or shadings) at a given offset. A co-event network will have graphic elements in lines (ER) and sections (EC). The motivation behind this network is to introduce the times every ER shows up in a similar setting as every EC. The standardized co-event framework is gotten by isolating every component of G by the absolute number of co-event matches in G. The nearness can be characterized to happen in every one of the four bearings (level, upward, left, and right inclining)
Cost Function
For any AI model to combine, it innately needs an expense or blunder work on which it can enhance. For this situation the expense work is:
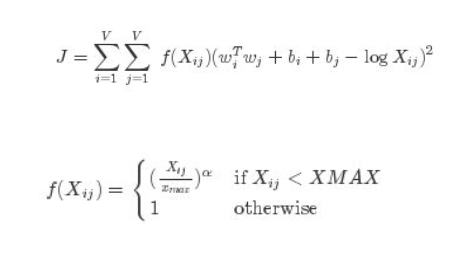
Here, J is the cost function. Along these lines, let us navigate through the terms individually:
Xij is the recurrence of Xi and Xj showing up together in the corpus
Wi and Wj is the word vector for word I and j separately.
bi and bj relate to the inclinations w.r.t words i and j.
Xmax is an edge for the most excellent co-event recurrence, a boundary characterized to forestall loads of the stowed away layer from being passed over. Along these lines, the capacity f(Xij) is a requirement of the model.
Once the expense work is streamlined, loads of the hidden layer turn into the word embeddings. The word embeddings from GLoVE model can be of 50,100 aspects vector relying on the model we pick. The connection underneath gives various GLoVE models delivered by Stanford University, which are accessible for download at their link (Stanford glove).
Python implementation
For the implementation of glove with python there are the following steps:
Step 1: Install Libraries.
Step 2: Define the Input Sentence.
Step 3: Tokenize.
Step 4: Stop Word Removal.
Step 5: Lemmatize.
Step 6: Building model.
Step 7: Evaluate the model.
- As one would expect, ice co-happens more often with strong than gas, while steam co-happens more often with gas than with strong.
- The two words co-happen with their ordinary property water as often as possible, and both co-happen with the inconsequential word design rarely.
Just in the proportion of probabilities commotions from non-discriminative words like water and design counterbalance, enormous qualities (a lot more prominent than 1) connect well with properties explicit to ice and little qualities.
Word2Vec versus GloVe
Word vectors put words in a pleasant vector space, where comparative words combine and various words repulse. The benefit of GloVe is that not normal for Word2vec; GloVe doesn't depend simply on neighborhood insights (nearby setting data of words) yet consolidates worldwide measurements (word co-event) to get word vectors.
Making Corpus
Making corpus in which a circle is made with tqdm (utilized for progress bar) message information section, and bringing down out the words (tweets), and tokenizing the sentence.
def create_corpus(df):
corpus = []
for tweet in tqdm(df["text"]):
words [word.lower() for word in word_tokenize (tweet) if \
((word.isalpha() == 1) & (word not in stop))]
corpus.append(words)
return corpus
Whenever we are finished with articulation, we want to circle through each line in the record, and split the line by each space, into every one of its parts. Subsequent to parting the line, we expect the word to have no spaces in it and set it equivalent to the first (or zeroth) component of the split line. Then we can take the remainder of the line and convert it into a Numpy exhibit. This is the vector of the word's situation.
Toward the end, we can refresh our word reference with the new word and its relating vector:
with open('/content/drive/MyDrive/Projects/Natural Disaster Tweets/glove. 68.100d.txt', 'r') as glove:
for line in glove:
values-line.split()
word = values[0]
vectors = np.asarray(values [1:], 'float32')
embedding_dict[word] = vectors
glove.close()
Cushioning Sentences
Distributing 50 words as length for at any point sentence. Tokenizing each expression of the corpus and later cushioning the sentence to the MAX_LEN apportioned, for example, 50 words for each sentence.
Shortening implies evacuation of the rest of the words staying in the sentence of the corpus and cushioning the left words:
MAX_LEN = 50
tokenizer_obj Tokenizer() = tokenizer_obj.fit_on_texts (corpus)
sequences = tokenizer_obj.texts_to_sequences (corpus)
tweet_pad = pad_sequences (sequences, maxlen = MAX_LEN, truncating = 'post', padding 'post')
Inserting GloVe on Dataset
Each word present in the dataset is inserted with the GloVe downloaded message vectors and an installing lattice is made containing words with their individual vectors:
num_words = len (word_index) + 1 embedding_matrix = np.zeros((num_words, 100))
for word, i in tqdm(word_index.items()):
if i > num_words:
continue
embedding_vector = embedding_dict.get(word) if embedding_vector is not None: embedding_matrix[i] = embedding_vector

 6+ registered
6+ registered 

