Transfer Learning
One of the most critical discoveries in machine learning is transfer learning! It enables us to make use of other people's models.
Because not everyone has access to billions of text samples or GPUs/TPUs to extract patterns from them, if someone can accomplish it and pass on the knowledge, we can use it to solve business problems right away.
When someone else constructs a model based on a sizeable generic dataset and only distributes the model to others, transfer learning is named after the fact that no one has to train the model on a large amount of data; instead, they "transfer" the learnings from others to their system.
In NLP, transfer learning is advantageous. Vectorization of text is especially important because it transforms text into vectors for 50K entries. If we can use other people's pre-trained models, we can address the challenge of transforming text data into numeric data. Other tasks, like categorization and sentiment analysis, can be continued.
In-text vectorization employing transfer learning, Stanford's GloVe and Google's Word2Vec are two popular options.
GloVe
Word Representation using Global Vectors GloVe is an unsupervised learning technique that generates word vector representations. The resulting representations highlight intriguing linear substructures of the word vector space, and training is based on aggregated global word-word co-occurrence statistics from a corpus.
A context window based on the co-occurrence matrix of words is used to generate glove vectors.
Glove Word vectors are word representation that connects the human and computer understanding of language.
They learned text representations in n-dimensional space with equal representations for words with the same meaning. This means that almost identical vectors represent two similar words in size and placement in a vector space.
Context Window
Similar words tend to appear in groups and have similar contexts. Apple, for example, is a fruit. Mango is a type of fruit. Apple and mango are both fruits, so they have a similar context.
The number of times a pair of words, such as w1 and w2, have appeared together in a Context Window for a given corpus is called co-occurrence.
Context Window - A number and a direction define the context window. How many words should be considered before and after a given word?
Now transfer learning can be divided into three steps-
STEP 1: LOAD GLOVE VECTORS
To train on the GloVe embeddings, you must first load the embeddings into your system (surprise, surprise). You may get them by clicking here.
Once you have a file, use the following code to load it.
CODE-
glove_file = datapath('YOUR_DATAPATH_HERE')
tmp_file = get_tmpfile("test_word2vec.txt")
_ = glove2word2vec(glove_file, tmp_file)
glove_vectors = KeyedVectors.load_word2vec_format(tmp_file)

You can also try this code with Online Python Compiler
This converts the.txt file you downloaded from the GloVe website into the Gensim Word2Vec library's format. You may now perform the standard similarity searches to see if everything loaded correctly.
STEP 2: BUILD A TOY MODEL TO UPDATE FROM
Without utilizing GloVe yet, you create a Word2Vec model from your data in this stage. This technique allows you to collect new words and develop a vocabulary that covers your whole dataset, which is useful if you're working with non-standard English texts.
CODE-
# for this to work, your input is going to be a list of tokenized sentences
# since my data was in a dataframe, first I selected the appropriate series
documents = df[df['school'] == 'rationalism']['sent_tokenized']
# then made it into a list
sentences = [sentence for sentence in documents]
# clean your sentences
stopwords = [YOUR_STOPWORDS_HERE]
cleaned_sentences = []
for sentence in sentences:
cleaned = [word.lower() for word in sentence]
cleaned = [word for word in cleaned if word not in stopwords]
cleaned_sentences.append(cleaned)
# build a word2vec model on your dataset
base_model = Word2Vec(size=300, min_count=5)
base_model.build_vocab(cleaned_sentences)
total_examples = base_model.corpus_count
You can also try this code with Online Python Compiler
STEP 3: ADD GLOVE WEIGHTS AND RETRAIN
You will retrain your existing model on your dataset after adding the GloVe vocabulary and beginning weights.
CODE-
# add GloVe's vocabulary & weights
base_model.build_vocab([list(glove_vectors.vocab.keys())], update=True)
# train on your data
base_model.train(cleaned_sentences, total_examples=total_examples, epochs=base_model.epochs)
base_model_wv = base_model.wv
You can also try this code with Online Python Compiler
The result will be a new set of word vectors that use GloVe's original weights but are now tuned to incorporate your data. Here's an example of a result:
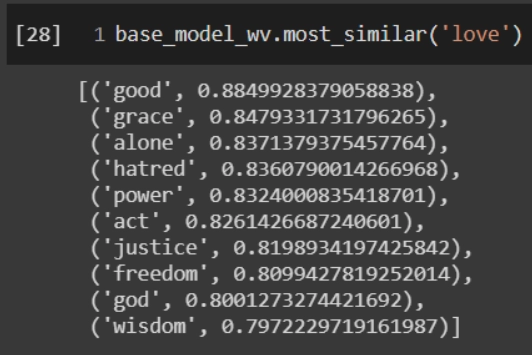
CODE
def train_glove(source, glove_vectors, threshold=10, stopwords=[],
min_count=20):
# isolate the relevant part of your dataframe
documents = df[df['source'] == source]['sent_tokenized']
# format the series to be used
tences = [sentence for sentence in documents]
# remove stopwords, if needed
stopwords = []
cleaned = []
for tence in tences:
claned_sentence = [word.lower() for wrd in tence]
claned_sentence = [wrd for wrd in sentence if wrd not in stopwords]
cleaned.append(claned_sentence)
# these next steps weren't in our original description because they aren't essential to the task
# they enable you to get word vectors for bigrams and even trigrams if those phrases are common enough
# get bigrams
biagram = Phrases(cleaned, min_count=min_count, threshold=threshold,
delimiter=b' ')
biagram_phraser = Phraser(bigram)
biagramed_tokens = []
for sent in cleaned:
tokens = bigram_phraser[sent]
bigramed_tokens.append(tokens)
# run again to get trigrams
trigram = Phrases(bigramed_tokens, min_count=min_count, threshold=threshold,
delimiter=b' ')
trigram_phraser = Phraser(trigram)
trigramed_tokens = []
for sent in bigramed_tokens:
tokens = trigram_phraser[sent]
trigramed_tokens.append(tokens)
# build a toy model to update with
model = Word2Vec(size=300, min_count=5)
model.build_vocab(trigramed_tokens)
total_examples = model.corpus_count
# add GloVe's vocabulary & weights
model.build_vocab([list(glove_vectors.vocab.keys())], update=True)
# train on our data
model.train(trigramed_tokens, total_examples=total_examples, epochs=model.epochs)
model_wv = model.wv
# delete the model to save memory, and return word vectors for analysis
del model
return model_wv
You can also try this code with Online Python Compiler
FAQs
1. What is GloVe method?
The gloVe technique is an unsupervised learning method for obtaining word vector representations. The resulting representations highlight intriguing linear substructures of the word vector space, and training is based on aggregated global word-word co-occurrence statistics from a corpus.
2. Why is it advantageous to use GloVe embeddings?
The gloVe benefits that, unlike Word2vec, it does not rely solely on local statistics (local context information of words) to generate word vectors but also incorporates worldwide statistics (word co-occurrence).
3. How does GloVe embedding work?
The primary idea behind the GloVe word embedding is to use statistics to derive the link between the words. Unlike the occurrence matrix, the co-occurrence matrix informs you how frequently a specific word pair appears together. Each value represents a pair of words that occur together in the co-occurrence matrix.
4. Is GloVe better than word2vec?
GloVe embeddings perform better on some data sets, while word2vec embeddings perform better on others. They both do an excellent job capturing the semantics of analogy, which leads us a long way toward lexical semantics.
Key Takeaways
So that's the end of the article.
In this article, we have extensively discussed Transfer learning with GloVe.
Isn't Machine Learning exciting!! We hope that this blog has helped you enhance your knowledge regarding transfer learning with GloVe and if you would like to learn more, check out our articles on the MACHINE LEARNING COURSE. Do upvote our blog to help other ninjas grow. Happy Coding!





























 6+ registered
6+ registered 

