


























Introduction
We know that technology is increasing day by day, and the amount of information is also evolving alongside. But wait, will this huge data be important or necessary for any organization's business analysis? No, because this evolving information is unstructured and useless in some cases. But everyone needs things to be done as simple as that. Thus if we require some keywords formation, the task will become easy to find information as simple as that. For this purpose, the evolving Natural Language Processing introduces the concept of Information Extraction. Were using this concept, we can simply extract useful information from a bunch of unstructured data. Let's take a simple look over it.
Information Extraction
Natural Language consists of a huge amount of unstructured and complex data. Processing of it also contains more techniques and methodologies. In this, one of the methods or concepts is Information Extraction, a process of retrieving structured information from unstructured information. For example, Information Extraction is used in Building Chatbots- chatbots will only respond based on some keywords. Thus this concept will help in that. Information Extraction can be seen diagrammatically as shown below:
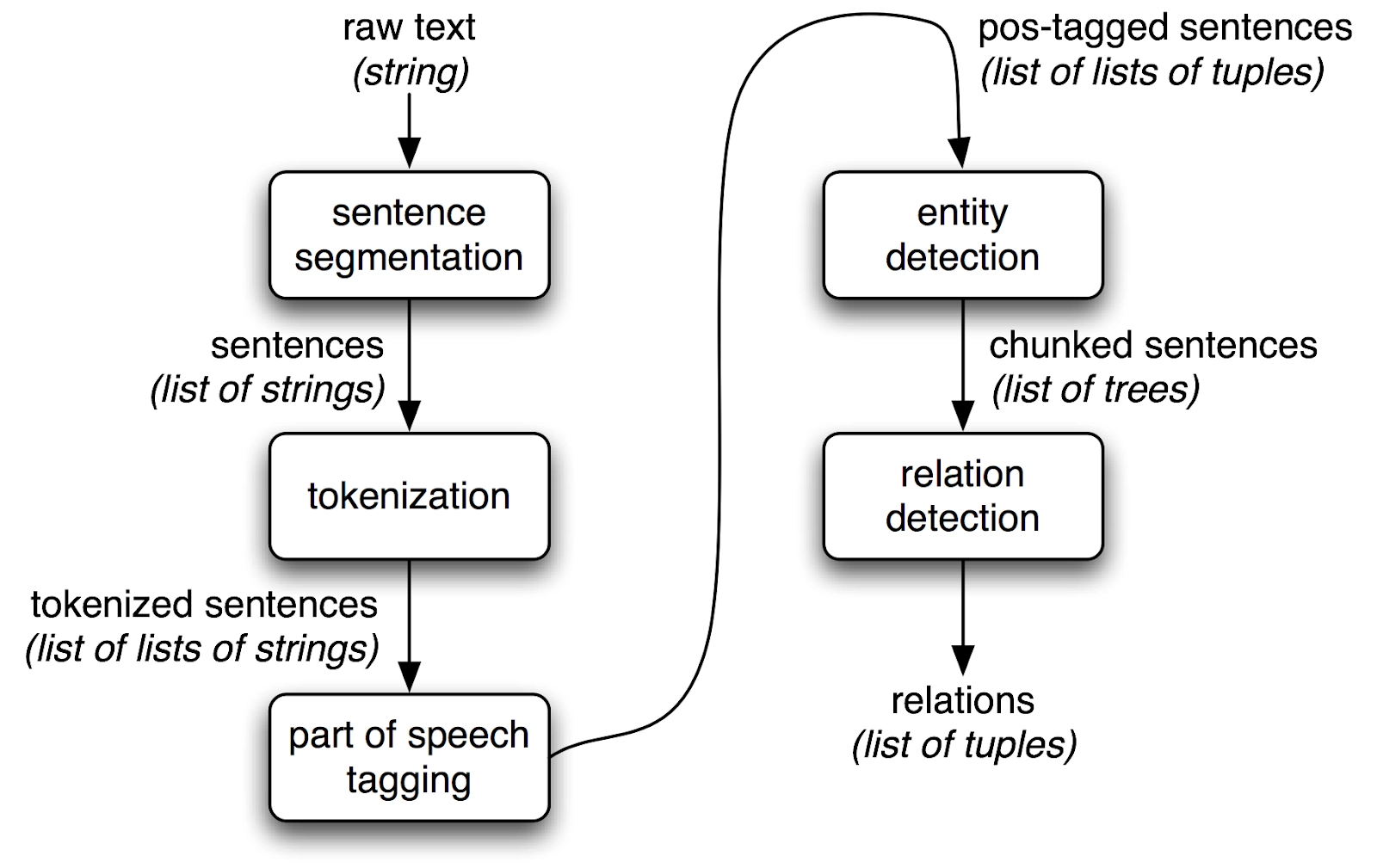
From the above diagram, we can conclude that in the Information Extraction Process, we first need to segment the given raw information into sentences and then the sentences into tokens by using Tokenization technique. And then after some prepocessing like Sentence Tokenization technique. And then, after some preprocessing like Sentence Tokenization, Word Tokenization, and Parts Of Speech Tagging, the next step is to use some Entity Recognition Techniques like some Rule-Based Models, Probabilistic Models, Information Extraction can be done.
The two most important terms to be noticed are
Relation Linkage: a process of finding relationships between named entities.
Record Linkage: a process of linking two or more records of the same entity.
For example, Bangalore and Bengaluru belong to the same entity.
Some of the techniques that involved in Information Extraction are:
1. Regular Expression.
2. Parts Of Speech Tagging.
3. NER (Named Entity Recognition.
4. Topic Modelling.
5. Rule-Based Matching.
Depending on the type of information to be extracted, the methods may vary.
1. Regular Expression:
Regular Expression is one of the most friendly and most popular techniques to match some patterns of information with the provided data. In this technique, we can say that information extraction can be done for a given data. We will prepare some regular expressions/ patterns that match our need for information extraction, and then we will find and extract the information that matches those prepared patterns. In this way, Information extraction can be done by using the Regular Expression Technique.
Example:
To find or extract all the URLs in a given data, we can use the pattern:
url_pattern = "(https?)://(www)?.?(\\w+).(\\w+)/?(\\w+)?"
2. Parts Of Speech Tagging:
Parts Of Speech can be done in many methods, in which we can tag the words with their parts of speech and extract all the information based on these POS. Like, if we need to get all the names, after fetching the parts of speech, we will just match the words with the Proper Nouns. Example:
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp("CodingNinjas is one of the best platform to improve one's portfolio")
for token in doc:
print(token.text, token.pos_)Output:
CodingNinjas PROPN
is AUX
one NUM
of ADP
the DET
best ADJ
platform NOUN
to PART
improve VERB
one PRON
's PART
portfolio NOUN3. Named Entity Recognition:
A sub-task of information extraction that finds and classifies named entities mentioned in the provided text into some pre-defined categories such as names, orgs, locations, etc.
Example:
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp("CodingNinjas is one of the best platform to improve one's portfolio. The course price range from around $75 dollars")
for entity in doc.ents:
print(entity.text, entity.label_)Output:
CodingNinjas ORG
around $75 dollars MONEY4. Topic Modeling:
Topic Modeling is another technique used in Natural Language Processing for Information Extraction. This technique is used to find and extract “topics” that appear in the provided document. This implementation takes more space. Thus you guys can refer to this concept here.
5. Rule-Based Matching:
Rule-Based Matching is the combination of both finding tokens and their relationships within the document. This include:
-> Token-based matching:
This includes Rules formation and annotating Tokens by using those rules. Here we can also attach patterns/rules to entity IDs to provide basic entity linking.
->Phrase Matching:
This includes the Matching of large terminology or complete phrases using some patterns, and then we will extract and use that information. You can refer to more code implementations using this link.


 9+ registered
9+ registered 

