Assumptions of Naive Bayes
The two main assumptions are that the vectors are independent, and there is no correlation. Another assumption is that all the features play an equal role, i.e., all the vectors are not correlated with each other and do not cause redundancy. To get an in-depth understanding of Naive Bayes, check out this article.
Must Read : Naive Bayes and Laplace Smoothing
Laplace Smoothing
While testing the model, there could be a situation where the model has faced a new query point, a data point for which it is not trained. According to the Naive Bayes formula, the posterior probability would become zero for that particular data point. Hence the resulting possibility after multiplication will also be zero.
For example, we have built a word finder model, and we have to find the word 'sport' in a sentence, but the model is not trained for that word. Then the probability of sport, i.e., P(word/sport), is zero, and after we multiply the possibilities, the product will be zero.
Laplace smoothing was introduced to overcome this error.
Read about : Smoothing in NLP
How does Laplace Smoothing work?
Let us understand this with the help of the spam classifier example.
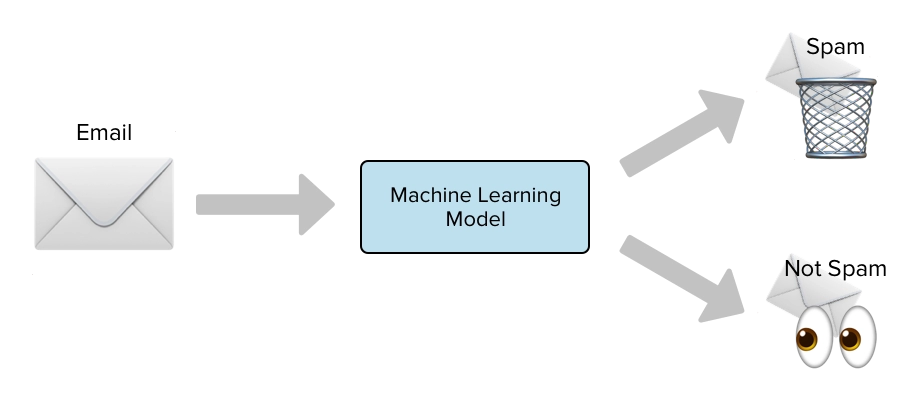
Source: Link
Suppose the word gift was only included in the spam emails during the training period. Therefore, you assume that gift is a spam word and conclude that
P(gift/not-spam)=0
i.e., none of the non-spam emails would have the word gift in them.
The probability of this event occurring is low but not zero. Later as we have to multiply all the probabilities, the final result will be zero, and even the non-spam mail will be concluded as spam.
That is why we need Laplace smoothing; it ensures that the posterior probability is never zero. It increases the zero probability values to small positive values and simultaneously reduces other matters so that the final sum remains to be one.
We modify the posterior probability formula in the following way:

Source: Link
In the formula mentioned above,
Alpha is the number of smoothing parameters
K represents the number of parameters.
N represents the number of reviews considering y is positive.
The advantage and disadvantage of Laplace Smoothing
The advantage of Laplace Smoothing:
It ensures no case of zero prior probability and appropriately executes the classification.
The disadvantage of Laplace Smoothing:
Since the mathematical terms are changed to give a better classification, the actual probabilities of the event are changed. Also, to increase the value of the zero probability data point, the rest of the data point's possibilities are reduced to maintain the law of probability.
Frequently Asked Questions
What does Laplace smoothing do?
Laplace smoothing, often referred to as add-one smoothing, is a statistical technique that prevents zero probability in statistical models by adding a small constant to each count in a frequency distribution.
What is smoothing in NLP?
Smoothing, as applied in NLP, describes methods for resolving the issue of zero probability for unseen words or n-grams in statistical language models, hence enhancing the resilience and generalization of the model.
What is Laplace estimation?
In probability theory and statistics, laplace estimation, also called add-one smoothing, is a method that includes adding one to the count of each result to account for unknown data.
What do you mean by additive smoothing?
By adding a small constant to the recorded counts of each category, a statistical and machine learning approach called additive smoothing—also referred to as Laplace smoothing—is used to smooth categorical data.
Why is Laplace smoothing important in naive Bayes?
Laplace smoothing is crucial because it classifies the terms into more possible classes than only two.
Why do we need smoothing?
Ans. Applying Laplace smoothing gives the classifier more options to classify the probabilities over more diverse events.
Conclusion
Laplace Smoothing is a technique that removes the problem of zero probability in the Naive Bayes Algorithm. This article studied Laplace smoothing, how it works, and its advantages and disadvantages. To build a career in Data Science? Check out our industry-oriented machine learning course curated by our faculty from Stanford University and Industry experts.





























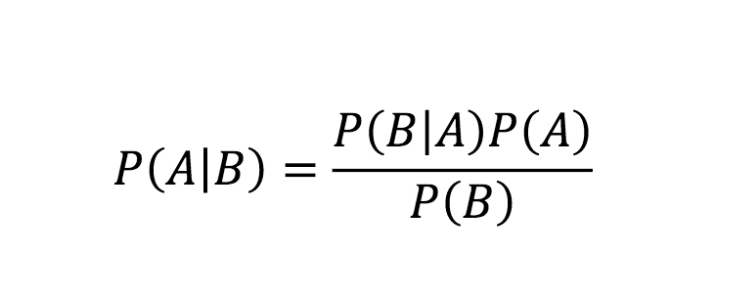


 7+ registered
7+ registered 

