Why do we need smoothing in NLP?
We use Smoothing for the following reasons.
- To improve the accuracy of our model.
- To handle data sparsity, out of vocabulary words, words that are absent in the training set.
Example - Training set: ["I like coding", “Prakriti likes mathematics”, “She likes coding”]
Let’s consider bigrams, a group of two words.
P(wi | w(i-1)) = count(wi w(i-1)) / count(w(i-1))
So, let's find the probability of “I like mathematics”.
We insert a start token, <S> and end token, <E> at the start and end of a sentence respectively.
P(“I like mathematics”)
= P( I | <S>) * P( like | I) * P( mathematics | like) * P(<E> | mathematics)
= (count(<S>I) / count(<S>)) * (count(I like) / count(I)) * (count(like mathematics) / count(like)) * (count(mathematics <E>) / count(<E>))
= (1/3) * (1/1) * (0/1) * (1/3)
=0
As you can see, P (“I like mathematics”) comes out to be 0, but it can be a proper sentence, but due to limited training data, our model didn’t do well.
Now, we’ll see how smoothing can solve this issue.
Types of Smoothing in NLP
-
Laplace / Add-1 Smoothing
Here, we simply add 1 to all the counts of words so that we never incur 0 value.
PLaplace(wi | w(i-1)) = (count(wi w(i-1)) +1 ) / (count(w(i-1)) + V)
Where V= total words in the training set, 9 in our example.
So, P(“I like mathematics”)
= P( I | <S>)*P( like | I)*P( mathematics | like)*P(<E> | mathematics)
= ((1+1) / (3+9)) * ((1+1) / (1+9)) * ((0+1) / (1+9)) * ((1+1) / (3+9))
= 1 / 1800
-
Additive Smoothing
It is very similar to Laplace smoothing. Instead of 1, we add a δ value.
So, PAdditive(wi | w(i-1)) = (count(wi w(i-1)) + δ) / (count(w(i-1)) + δ|V|)
-
Backoff and Interpolation
Backoff
○ Start with n-gram,
○ If insufficient observations, check (n-1)gram
○ If insufficient observations, check (n-2)gram
Interpolation
○ Try a mixture of (multiple) n-gram models
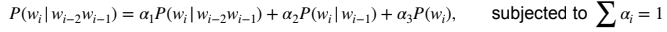
-
Good Turing Smoothing
This technique uses the frequency of occurring of N-grams reallocates probability distribution using two criteria.
For example, as we saw above, P(“like mathematics”) equals 0 without smoothing. We use the frequency of bigrams that occurred once, the total number of bigrams for unknown bigrams.
Punknown(wi | w(i-1)) = (count of bigrams that appeared once) / (count of total bigrams)
For known bigrams like “like coding,” we use the frequency of bigrams that occurred more than one of the current bigram frequency (Nc+1), frequency of bigrams that occurred the same as the current bigram frequency (Nc), and the total number of bigrams(N).
Pknown(wi | w(i-1)) = c* / N
Where c* = (c+1) * (Nc+1) / (Nc) and c = count of input bigram, “like coding” in our example.
-
Kneser-Ney Smoothing
Here we discount an absolute discounting value, d from observed N-grams and distribute it to unseen N-grams.
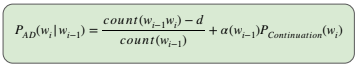
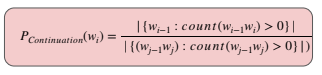
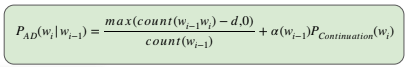

-
Katz Smoothing
Here we combine the Good-turing technique with interpolation. Feel free to know more about Katz smoothing here.
-
Church and Gale Smoothing
Here, the Good-turing technique is combined with bucketing. Every N-gram is added to one bucket according to its frequency, and then good-turing is estimated for every bucket.
Frequently Asked Questions
1. What is smoothing in language models?
Smoothing is a technique used to overcome the problem of the sparsity of training data by adding or adjusting the probability mass distribution of words.
2. Why do we use Smoothing in NLP?
We use Smoothing in NLP to assign non-zero probabilities to unseen words and improve our model accuracy.
3. What is K smoothing (K=1) called?
It is also known as Laplace or Add one smoothing.
4. How do you apply Laplace smoothing?
To apply Laplace Smoothing, we add 1 to all counts of words.
PLaplace(wi | w(i-1)) = (count(wi w(i-1)) +1 ) / (count(w(i-1)) + V)
Where V= total words in the training set.
5. What is Additive smoothing?
It is very similar to Laplace smoothing. Instead of 1, we add a δ value.
So, PAdditive(wi | w(i-1)) = (count(wi w(i-1)) + δ) / (count(w(i-1)) + δ|V|)
Key Takeaways
This article discussed smoothing in NLP, why we need it, and the different types of smoothing techniques present.
We hope this blog has helped you enhance your knowledge regarding Smoothing in NLP and if you would like to learn more, check out our free content on NLP and more unique courses. Do upvote our blog to help other ninjas grow.
Recommended Readings:
Spelling Correction in NLP
Smoothing Images
Naive Bayes and Laplace Smoothing





























 8+ registered
8+ registered 

