



























Introduction
Computer vision and Deep Learning have created quite a buzz in the past few years in the tech industry. They’re looked at as Lucrative and future-ready career choices. But have you ever thought about what Computer vision actually deals with? Computer vision is a subsidiary of Artificial Intelligence that aims to derive relevant information from visual input like Images and videos. But how exactly do we make a computer perform image learning? It’s not textual data that we intuitively think can be processed by a machine. We have various techniques for this process. We’ll discuss one such technique known as Convolutional Neural Network.
Also Read, Resnet 50 Architecture
CNNs and how do they work
To understand image learning and how CNN serves the purpose of image learning, let us know a very basic detail about how humans understand images. It’s simple, we look for some salient features which are characteristic of a particular object, and the more these characteristics match with some object, the closer it resembles it. For example, if we were to identify a tiger, we would look for the characteristic features from our acquired knowledge of tigers. So we might look for stripes. But that won’t be enough since there are other striped animals. Then we may look for sharp and long canines. These are some of the defining features of a tiger. Basically, what we do is called feature detection.
CNNs work in a similar manner. Let us first understand how CNNs perceives any image before it begins its operations. An image can be represented by a matrix of 1 and 0 or 1 and -1 in case of a strict shape search.

Source -link
Here we have a number 9, which we have divided into a grid filled with 1 and -1. We see that 1s in the grid make up 9 and empty spaces are filled with -1 in the grid.
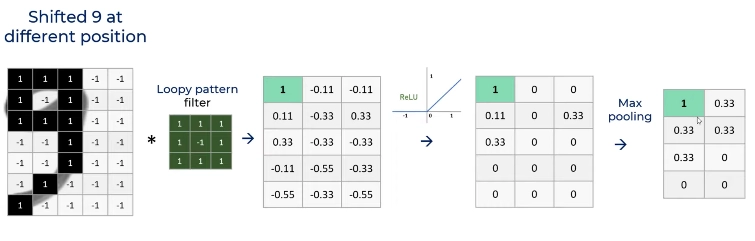
We identify three characteristic features of ‘9’. The loop, the vertical line in the middle and the short diagonal line that makes up the tail. So we have 3 filters, one for each feature. We will superimpose all these filters on an image if we want to detect it has a ‘9’.
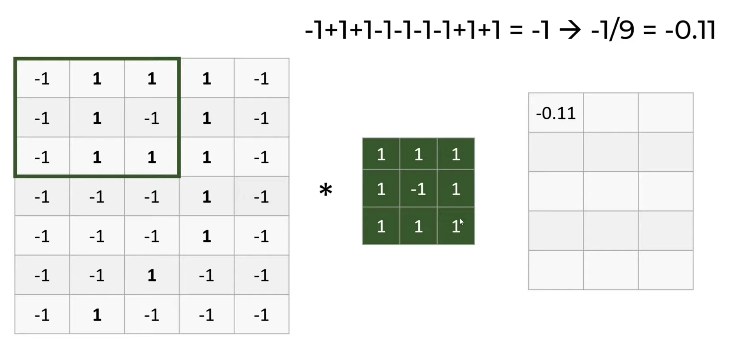
We took the loop filter (refer to figure (c)) we identified in number 9 and moved it over the grid of 1 and -1 of the image we wanted to check for. We map, multiply and then take the average of the numbers generated by superimposing the filter on the grid image. The filter is superimposed on the entire grid one by one. Think of the image as the parent matrix and the filter as a submatrix. Look at the image below. We multiply every cell in the filter to the corresponding submatrix in the grid image and then take the average of the sum of the numbers generated.
In the case below, we do the following math-
1*(-1) + 1*1 + 1*1 + 1*(-1) + (-1)*1 + 1*(-1) + 1*(-1) + 1*1 + 1*1 = -1
Taking the average we get , -1/9 = - 0.11
Source -link
Source -link
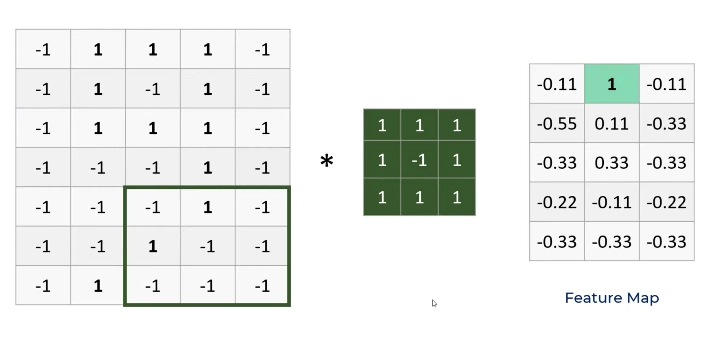
So for the submatrix that exactly matches the filter, the resultant is 1. This implies that there was a feature detection and the location of the detected feature can be identified in the resultant matrix. This resultant matrix is known as a feature map. A feature map is created for every filter we have. After this, we may have feature map aggregation to form another feature map that would essentially represent all the details of its component feature maps. Look at the example given for a better understanding.

Source -link
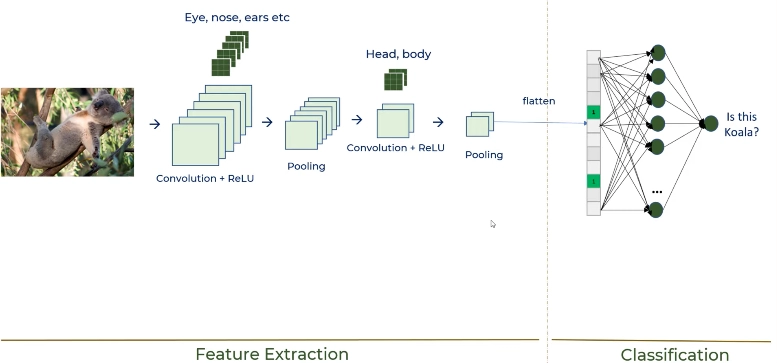
Suppose we train a model to detect a koala. We identify 5 filters namely -eyes, nose, ears, hands and legs. From feature maps, we detect the presence of all 5 features. And eyes, nose and ears feature maps can be combined to derive the presence of a koala head.
Similarly, legs and hands feature maps can be aggregated to derive the presence of a koala body. This results in two new feature maps, depicting the head and the body of the koala.
These features maps are 2D arrays. Hence they’re converted to a single-dimensional array for the deep neural network to process the image. This process is known as ‘Flattening’. This forms a fully connected neural network. The neural network can then classify the image based on the input it received from the feature map aggregation.


 6+ registered
6+ registered 

