Do you think IIT Guwahati certified course can help you in your career?
Introduction
What should we do when we have a large amount of data with different units like kilograms, meters, and liters and a massive disparity between the values of all the features so that our model is unbiased towards the weighted feature? We feature scale!
We strive to alter the data in Data Processing such that the model can process it without any issues. And one such process is feature scaling, which involves transforming the data into a better version. We can use it to standardize the data set's features into a restricted range.
Why use Feature Scaling?
Consider the house price prediction dataset, which has several attributes with a broad range of values. Many features will be included, such as the number of bedrooms, the house's square footage, and so on.
As you might expect, the number of beds will range from one to five, but the square footage will be between 500 and 2000. In terms of the range of both features, this is a significant difference.
Many machine learning algorithms that use Euclidean distance as a metric to evaluate similarities will fail to recognize the minor feature, in this case, the number of bedrooms, which can turn out to be an essential metric in the real world.
Let's take a closer look at how we could use it in different machine learning algorithms:
The goal of linear regression is to identify the best fit line. To do so, we must first use the concept of gradient descent to locate global minima. We can get faster to the global minima if we scale the data.
In algorithms like KNN, K-means, and Hierarchical Clustering, we use Euclidean distance to locate the closest points; therefore, we should scale the data so that all attributes are equally weighted. If we don’t do this, features with a large magnitude will be weighted far more heavily in distance computations than features with a small extent.
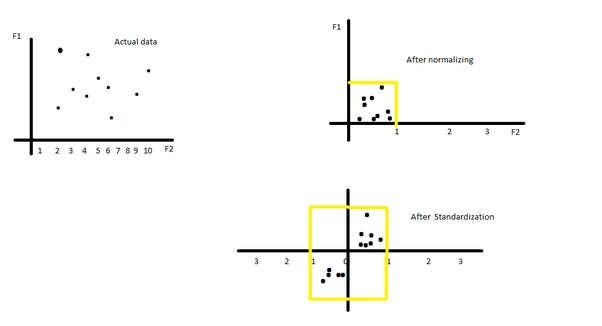
For instance, if we have a dataset that contains the height (Metres) and weight (Kgs) of females (red) and males (blue) of the same age. We have the weight and height of a new person (black), and we have to predict the gender of the new person. In other words, we have to classify the new person into one of the two categories: females and males, based on their height and weight.
Let us look at the KNN algorithm. Assuming that k is 3, we find that the black dot is much closer to 2 of the blue dots than the third red dot. So naturally, we will classify the black dot into the male category. However, we can see that the weight in Kgs has a much larger range than the height in meters, making our model biased towards the males (Don’t want to offend feminists). What should we do about it? We scale the features! After scaling, the graph will look something like this:
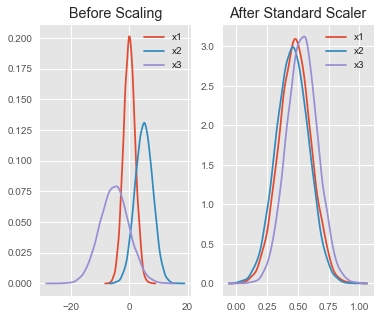
Some models, such as linear and logistic regression, assume that the feature is normally distributed. To make them adequately distributed, we must use transformations such as Logarithmic, Box-Cox, Exponential, and others.
The debate about normalization vs. standardization vs. robust scaling is a perennial one among machine learning newbies. In this section, I'll expand on the response.
Normalization
Standardization
Robust Learning
When you know that your data does notfollow a Gaussian distribution, normalization is a suitable option. Normalization is helpful in algorithms like K-Nearest Neighbors and Neural Networks, which do not presume any data distribution.
The range of Normalization is from 0 to 1. As a result, even if your data contains outliers, normalization will not affect them.
In circumstances where the data follows a Gaussian distribution, on the other hand, standardization can be beneficial. However, this is not the case all the time.
Standardization, unlike normalization, does not have a bounding range.
Standardization subtracts the mean, and then it divides by the standard deviation to ensure that the mean is equal to 0 and the scales become comparable in terms of standard deviation. In the case of outliers, this leads to overperformance.
If your dataset has many outliers, one or both of the most important procedures – Standardization and Normalization – may not perform as well. This problem can be solved with robust scaling.
We can solve the problem of outliers by scaling the dataset suitably with the RobustScaler in Scikit-learn, limiting the range but maintaining the outliers to continue to contribute to feature importance and model performance.
However, whether you use normalization, standardization, or robust learning depends on your problem and the machine learning algorithm you're utilizing at the end of the day. When it comes to normalizing or standardizing your data, there is no hard and fast rule. To get the best results, start by fitting your model to raw, normalized, and standardized data and comparing the results. And if you have a lot of outliers in your dataset, then try using robust learning.
Types of Feature Scaling techniques and how to do it
To demonstrate different feature scaling strategies, we'll use the SciKit-Learn library. You can download the Salary CSV file from here. Let's start coding! We are going to look at the data first before scaling it.
#imports
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#reading the csv file and making it into dataframe
data = pd.read_csv("../Downloads/Salary_Data.csv")
#function to plot graph after feature scaling
def make_scatter_plot(data):
x=data["YearsExperience"].to_numpy()
y=data["Salary"].to_numpy()
plt.xlabel("Years of Experience")
plt.ylabel("Salary")
plt.scatter(x,y)
print(plt.show())
print("Data before Scaling")
data.head(5)
You can also try this code with Online Python Compiler
In this method, we center the feature at 0 with a standard deviation of 1. Hence, bringing all of the parameters to a similar scale. This technique will be affected if there are any outliers. As a result, we use this with only normally distributed features.
This method of rescaling features with a distribution value between 0 and 1 is beneficial for optimization methods like gradient descent, used in machine learning techniques to weight inputs (e.g., regression and neural networks). For algorithms that require distance measurements, such as K-Nearest-Neighbours, rescaling is also used (KNN).
from sklearn.preprocessing import StandardScaler #import
standard_scaler=StandardScaler()
standard_scaled_data=pd.DataFrame(standard_scaler.fit_transform(data),columns=data.columns)
print("Data after Standard Scaling")
standard_scaled_data.head(5)
You can also try this code with Online Python Compiler
This estimator scales each feature separately to fall inside the specified range, between zero to one. This method is primarily utilized in deep learning, although it can also be employed when the distribution is not Gaussian. Outliers are also taken into account by this scaler.
This type of scaling strategy is applied when the data has a wide range of applications and the algorithms used to train the data, such as Artificial Neural Networks, do not make assumptions about the data distribution.
When we have outliers in our data, this is a very reliable technique. This technique removes the median and scales the data according to the quartile range. Scaling with the mean and standard deviation will not work if our data contains many outliers. As a result, it scales the data using the interquartile range.
Calculate the median (50th percentile), as well as the 25th and 75th percentiles. After subtracting the median from each variable's value, the interquartile range (IQR), the gap between the 75th and 25th percentiles, is divided.
value = (value – median) / (p75 – p25)
Where,
p25, p75 = 25th and 75th percentiles
from sklearn.preprocessing import RobustScaler
robust_scaler=RobustScaler()
robust_scaled_data=pd.DataFrame(robust_scaler.fit_transform(data),columns=data.columns)
print("Data after Robust Scaling")
robust_scaled_data.head(5)
You can also try this code with Online Python Compiler
If our features are not normally distributed, and we have skewed data, we can use transformations to make them distributed. I am showing the techniques through the code itself because it is pretty much self-explanatory.
import scipy.stats as stat #import for boxcox tranformation
import pylab
You can also try this code with Online Python Compiler
#data distribution before transformation
plt.title("Before transformation")
plt.xlabel("Target")
sns.histplot(y,kde=True,bins=30)
#data distribution after tranformation
plt.title("After transformation")
plt.xlabel("Target")
sns.histplot(rec_y,kde=True,bins=30)
You can also try this code with Online Python Compiler
#data distribution before transformation
plt.title("Before transformation")
plt.xlabel("Target")
sns.histplot(y2,kde=True,bins=30)
#data distribution after tranformation
plt.title("After transformation")
plt.xlabel("Target")
sns.histplot(sqroot_y,kde=True,bins=30)
You can also try this code with Online Python Compiler
#data distribution before transformation
plt.title("Before transformation")
plt.xlabel("Target")
sns.histplot(y3,kde=True,bins=30)
#data distribution after tranformation
plt.title("After transformation")
plt.xlabel("Target")
sns.histplot(expo_y,kde=True,bins=30)
You can also try this code with Online Python Compiler
Do all machine learning algorithms require feature scaling? Ans. Some algorithms, such as Decision Trees and Ensemble Techniques (including AdaBoost and XGBoost), do not require scaling because their splitting is based on values.
At which step in the code should we do scaling? Ans. It is essential to perform scaling after splitting the data into training and testing. If we don't do this, there will be data leakage from test data to train data.
What is the best scaling technique and why? Ans. There is nothing like the most effective transformation/scaling procedure. It all relies on the type of data you have and how well you know your business. In some cases, some scaling techniques improve the accuracy and performance of the algorithms, while other techniques improve accuracy and performance in different models.
Key Takeaways
In this article, we looked at what Feature Scaling is and how to do it in Python with Scikit-Learn using StandardScaler for standardization and MinMaxScaler for normalization.
The technique of scaling the values of features to a more manageable size is usually done during the preprocessing step. If you want to know about more applications of Feature Scaling, then check out our industry-oriented machine learning course curated by our faculty from Stanford University and Industry experts.

































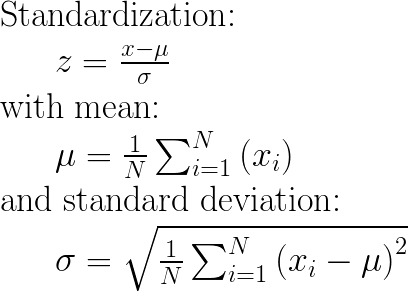


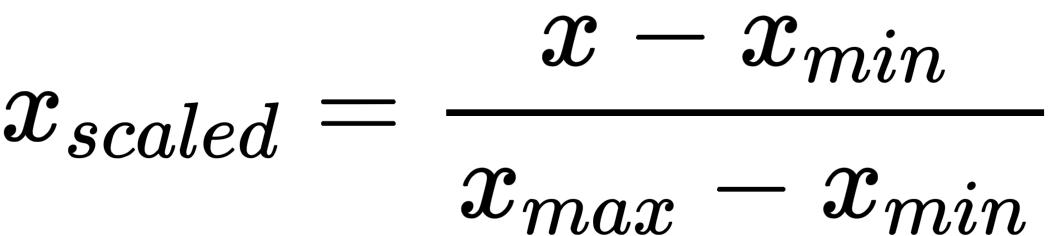



















 13+ registered
13+ registered 

