Do you think IIT Guwahati certified course can help you in your career?
Introduction
Hello Ninjas, data management is crucial while working on a large and complex project. We want to make sure that the data should make sense while implemented. The most effective way to do so is data flow analysis.
Data flow analysis refers to the analysis of data that determines the data used in the program.
In this article, we will learn about the foundations of data flow analysis in compiler design.
Data Flow Analysis
Data flow analysis refers to analyzing the data flow through a program. Data flow analysis helps in optimizing the code. It also helps in increasing efficiency and identifying bugs in the code. In data flow analysis, we track down the variables and how they change over time.
The code optimization associated with data flow analysis uses dead code elimination. It is tacking the variables. It identifies the constant expressions. These measures reduce unnecessary computations.
Code efficiency is related to the optimal use of variables. We can identify the unused variables to reduce overhead computations. It also helps to identify the unreachable code that can be eliminated. Thus, allowing to make computations faster and code smaller. Data flow analysis can curb potential vulnerabilities by analyzing reaching definitions.
Data Flow Analysis Schema
The data flow value for a program point represents a set. The set is a set of all possible program states that can be used for that point. The set of all the possible data flow is the domain for the application under consideration. The domain of data flow values is the set of all the subsets of the definitions in the program.
The data flow analysis follows two constraints
Based on the semantics of statements - Transfer Functions
Based on the flow of control
The data flow analysis schema consists of
A control flow graph
A direction of Data flow
A set of data flow values
A confluence operator ( can be Intersection or Union)
Transfer Function for each block
Basic Terminologies
Some of the frequently used terminologies in data flow analysis are:
Definition Point: The point where the definition for a variable is done.
Reference Point: The point where there is a reference to a data item previously used.
Evaluation Point: The point where the evaluation of an expression is done.
Building Blocks of Data Flow Analysis
The foundations of data flow analysis in compiler design follow basics concepts:
Lattices- These are partially ordered sets. The sets represent the state of the program during data flow analysis. They perform two operations - join operation and meet operation. The set elements' lower bound is calculated in the join operation. In meet operation, there is a merge of two lattices.
Reaching Definition-It determines which definition may reach a specific code point. It tracks the information flow in a code. It tracks the information flow in a code. A definition is said to reach a point such that there has been no variable redefinition. Reaching definitions track the variables and the values they hold at different points.
Control Flow Graph is a graphical representation of the control flow in compiler design. The control flow refers to the computations during the execution of a program. Control flow graphs are process-oriented directed graphs. The control flow graph has two blocks: the entry and exit. It helps to analyze the flow of computations and identify potential performance loopholes.
Iterative Algorithms- Iterative algorithms are used to solve data flow analysis problems. The iterative algorithms used are for reaching problems and for available expressions. Iterative algorithms for reaching problems assume that all definitions reach all points. It then iteratively solves and updates the reachable points for different definitions. For available expressions, it assumes that all expressions are available at all points. It then iteratively solves and updates the point of use of the expressions.
Lattices, Reaching Definition, and Control Flow are all important. They provide foundations of data flow analysis in compiler design. All three of them help in code optimization and data flow tracking.
The Types Of Data Flow Analysis Performed By Compiler
Constant Propagation Analysis
Reaching Definition Analysis
Live Variable Analysis
Available Expression Analysis
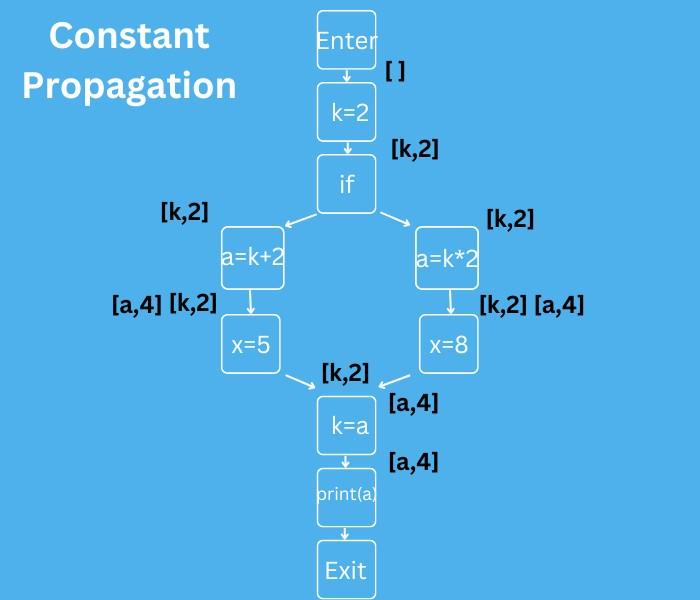
Constant Propagation Analysis
It determines the point where the program variable guarantees a constant value. The value computed is represented as a pair of (variable, value). If we have (x,v) as a pair, then x is guaranteed to have a value v whenever that block is reached during program execution.
Below is the CFG that can be used to understand the constant propagation information.
Here, we have the variable and their associated values listed down adjoining the block. We can see that for block 2 where k=2 the variable k is propagated with value 2 until associated with a new value.
Live Variable Analysis
The live variable analysis determines which variables are alive at each point in a program. The variable is alive if we can use its current value before it is overwritten. For a CFG node, the information of the live variables is a set of variables that are alive immediately after that node.
Below is the CFG annotated with live variable information.
Here, we have the variable, and their associated alive status is listed adjoining the block. We can see that for block 2, where k=2, the variable k is alive. Similarly, inside the if in block 4 where a=k+2, status a is set to alive. Likewise, in definition x=5, now both x and a are alive.
Reaching Definition Analysis
The reach definition analysis determines which set of definitions will reach a given point in a program. The variable is said to reach a certain point in a program if it is not reassigned or becomes dead before that point. The reach definition analysis for a variable is the blocks to which the variable is reachable.
Below is the CFG where the reaching definition for some variables is defined.
Here we can see that the definition D2 is reachable to all blocks. The definition D1 gets killed in block B2. The definition D3 gets killed in block B4. The definition D3 is alive in B4 and B5.
Available Expression Analysis
The available expression analysis determines which expression is available at a given point in a program. An expression is said to be available at a given point if none of its operands are affected by the assignment statement from the start to that point.
Below is the Control flow graph that shows the available expression analysis.
It shows that the expression a = b + c can be used in blocks B3 and B2. Since the expression operands are not modified, the expression can be reused.
Advantages of Data Flow Analysis
We have now discussed the foundations of data flow analysis in compiler design. It is clear to us how the data flow analysis is performed. Now, we will discuss some of the advantages of Data flow analysis.
Code Optimization- Data flow analysis is used in code optimization. Data flow analysis identifies the dead code and constant expressions. Therefore, eliminating dead code and removing redundant expressions reduces the computation.
Code Debugging- Data flow analysis is also used to identify potential vulnerabilities. The bugs are associated with buffer overflows and information leakage. These can be analyzed using the data flow analysis.
The phases of compiler design are - Lexical Analysis, Syntax Analysis, Semantic Analysis, Intermediate Code Generation, Code Optimization, Code Generation, and Error Handling. All these phases are followed to design an efficient compiler.
What is semantic analysis in compiler design?
Semantic analysis is the phase of compiler design where the correctness of a program is checked. In this phase, the compiler follows - type checking, scope checking, and control flow checking.
What is lexical analysis in compiler design?
Lexical analysis is the starting phase of compiler design for converting a given piece of code into a sequence of tokens. It is important as it converts the high-level code into structured tokens which are easy to handle.
This article taught us about the foundations of data flow analysis in compiler design. We learned the different basic concepts necessary for understanding data flow analysis. We understood some important types of data flow analysis. We learned all the types in detail with examples. Lastly, we discussed some advantages of data flow analysis in compiler design.
To learn more about data flow analysis in compiler design, you can check out our other blogs


































 6+ registered
6+ registered 

