


























Introduction
Hello Ninjas! Welcome back. Are you new to Cinder? Do you want to explore more about it? Do you want to explore what QuickTime MovieWriter is? If you answered any of these questions as yes, you're at the right place.

In this article, we will learn about Quicktime Moviewriter and discuss topics like XML in Cinder and Logging in Cinder. So let's get started. We will begin with the essential concept-building topics like what Cinder is and what XML is.
Cinder
Cinder is a cross-platform library for professional-level quality and creative coding in C++. It is used to develop applications for desktop platforms like Linux, Windows, and macOS and mobile platforms like Android and iOS.

XML
XML is a text-based format and stands for an extensible markup language. It is used to exchange and store structured data. It is usually used as a format for web services and interchanging data to store and transfer data over the vast internet.

XML in Cinder
To modify and parse XML documents in Cinder, we can use the pugiXML library. The pugiXML is a fast, easy-to-use, small parser written in C++. We need to include and link the correct header files in the library in order to use pugiXML in our Cinder projects. Let us look at an example of how we can load an XML document and access its elements using pugiXML in Cinder -
Implementation
#include "pugixml.hpp"
// To load the XML document
pugi::xml_document doc;
pugi::xml_parse_result result = doc.load_file("data.xml");
// Checking for errors
if (!result)
{
std::cout << "Error loading XML document: " << result.description() << std::endl;
return;
}
// To access the root element
pugi::xml_node root = doc.root();
// To iterate over the child elements of the root
for (pugi::xml_node node : root.children())
{
std::cout << "Node name: " << node.name() << std::endl;
// To access the attributes of the node
for (pugi::xml_attribute attr : node.attributes())
{
std::cout << " Attribute name: " << attr.name() << std::endl;
std::cout << " Attribute value: " << attr.value() << std::endl;
}
}Explanation
In the above, we are loading an XML document from a file named "data.xml," iterating it over the root element's child element and then printing the attributes and names of each element.
If the contents of “data.xml” are:
<?xml version="1.0"?>
<root>
<node attribute1="value1" attribute2="value2">
<!-- some content -->
</node>
<node attribute1="value3" attribute2="value4">
<!-- some content -->
</node>
</root>Output
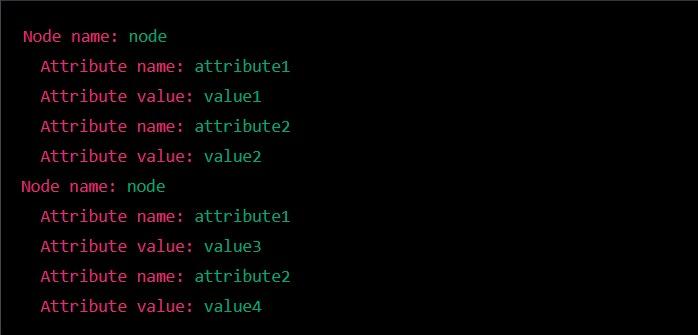
Then the output would be -


 18+ registered
18+ registered 

