Do you think IIT Guwahati certified course can help you in your career?
Introduction
The SCAN disk scheduling algorithm, which is also known as the elevator algorithm, optimizes disk head movement by servicing requests in a forward or backward direction until they reach the end of the disk and then in reverse direction. This approach minimizes the average seek time and improves the overall disk performance by reducing unnecessary disk head movements.
In this article, we will talk about the SCAN Scheduling Algorithm in detail with the help of proper code examples. We will also see its advantages and disadvantages.
What is Scan(Elevator) Disk Scheduling Algorithm?
In the SCAN scheduling algorithm, the disc arm begins at one end of the disc and moves towards the other end, servicing requests as it reaches each cylinder until it gets to the other end of the disc. As soon as it reaches the other end, the direction of head movement is reversed, and servicing continues. The head moves back and forth across the disc continuously servicing requests.
The SCAN algorithm is also known as the ELEVATOR algorithm, since the disc arm behaves similarly to an elevator in a building, first servicing all the requests going up and then reversing to service requests going down.
Advantages of SCAN(Elevator) Algorithm
The advantages of the SCAN Algorithm are-
The main advantage of the SCAN Algorithm is that it reverses its direction after reaching at the end which states that any dynamic request can be handled at the run time.
It provides low variance in response time and waiting time.
It is simple and easy to implement.
Its performance is very good.
Disadvantages of SCAN(Elevator) Algorithm
The disadvantages of the SCAN Algorithm are-
Even if there are no requests to be served, it causes the head to move to the end of the disc.
It results in a long waiting time for the cylinders that have just been visited by the head.
When SCAN Algorithm reverses its direction it won’t be able to get back at the prior direction which can lead to starvation. Although, mostly we’ve given the static requests which totally get executed.
To understand the SCAN Algorithm, let us assume a disc queue with requests for I/O. ‘head’ is the position of the disc head. We will now apply the SCAN algorithm-
Arrange all the I/O requests in ascending order.
The head will start moving in the right direction, i.e. from 0 to the size of the block.
As soon as a request is encountered, head movement is calculated as the current request - the previous request.
This process is repeated until the head reaches the end of the disc and the head movements are added.
As the end is reached, the direction of the head is reversed, and now the head will process the requests in the opposite direction, i.e. in the left direction.
This process is completed as soon as all the requests are processed and we get total head movement.
Example of SCAN Disk Scheduling Algorithm
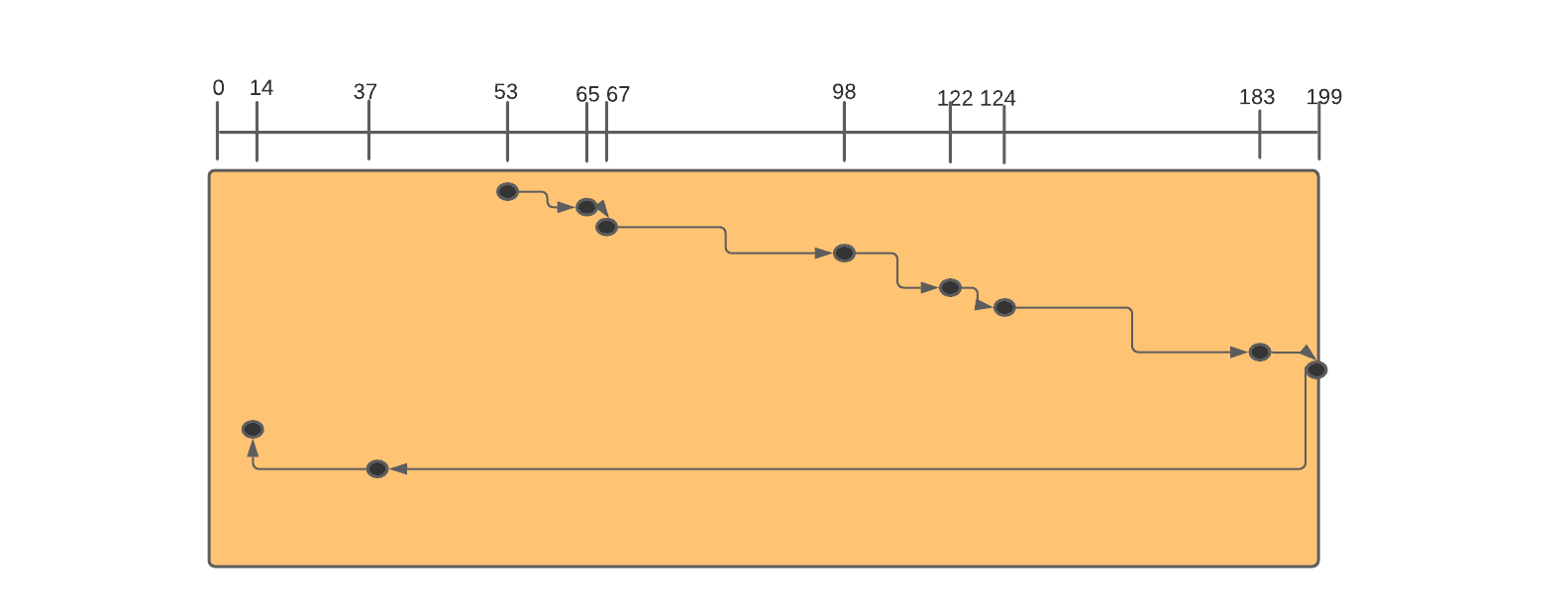
Example 1: Consider a disc queue with requests for I/O to blocks on cylinders 98, 183, 37, 122, 14, 124, 65, 67. The head is initially at cylinder number 53, moving towards a larger number of cylinders. We will now use the SCAN algorithm to serve these I/O requests.
Direction - towards the larger number of cylinders
Output:
Arranging all the requests in ascending order, we get - { 14, 37, 65, 67, 98, 122, 124, 183 }.
The Head starts moving in the right direction. So, the head will move from 53 (current position) and will stop at 65 (next request). Head movement = 65 - 53 = 12.
Then the head moves from 65 to 67, and head movement becomes 12 + (67 - 65) = 14.
Similarly, the head will go from 67 to 98, and head movement becomes 14 + (98 - 67) = 45.
Similarly, the head will go from 98 to 122 and head movement becomes 45 + (122 - 98) = 69.
Similarly, the head will go from 122 to 124, and head movement becomes 69 + (124 - 122) = 71.
Similarly, the head will go from 124 to 183, and head movement becomes 71 + (183 - 124) = 130.
Similarly, the head will go from 183 to 199 (end of the disc), and head movement becomes 130 + (199 - 183) = 146.
Now the head will reverse its direction and will go from 199 to 37, and the head movement will become 146 + (199 - 37) = 308.
Now, the head will go from 37 to 14, and head movement becomes 308 + (37 - 14) = 331.
Since 14 was the last request, the process will stop. We get the total head movement as 331.
The following chart shows the sequence in which requests are served using SCAN.
Thus, the order in which requests are served is- 65, 67, 98, 122, 124, 183, 199, 37, 14 with a total head movement of 331.
Now, let us consider one more example.
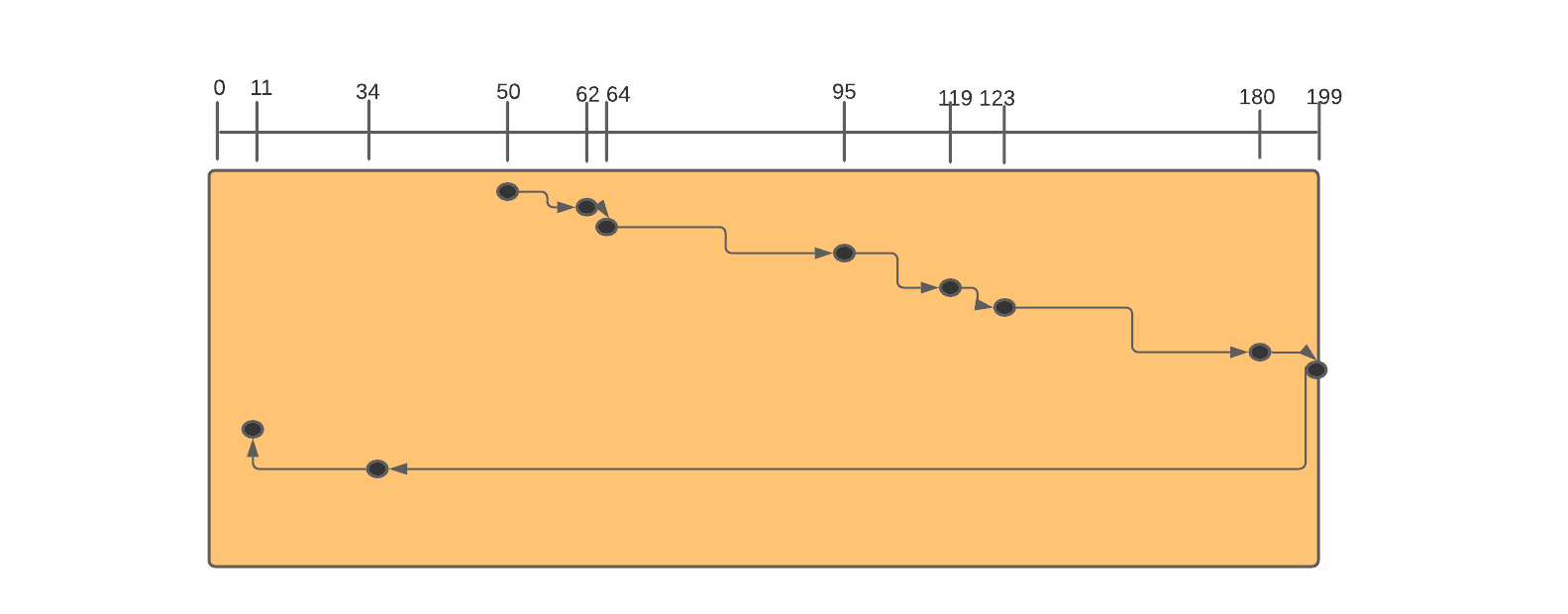
Example 2: Consider a disc queue with requests for I/O to blocks on cylinders 95, 180, 34, 119, 11, 123, 62, 64. The head is initially at cylinder number 50, moving towards a larger number of cylinders. We will now use the SCAN algorithm to serve these I/O requests.
The following chart shows the sequence in which requests are served using the SCAN algorithm.
Thus, the order in which requests are served is- 62, 64, 95, 119, 123, 180, 199, 34, 11 with a total head movement of 337.
Let us consider one more example.
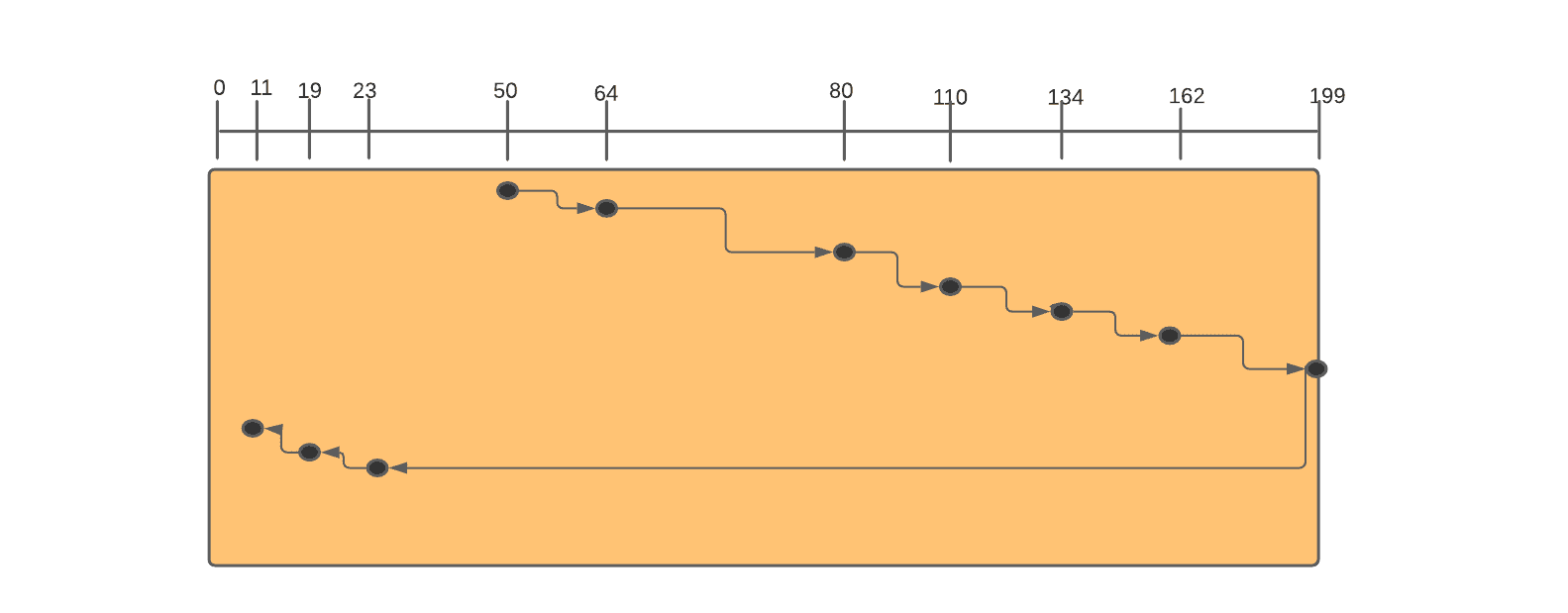
Example 3: Consider a disc queue with requests for I/O to blocks on cylinders 19, 80, 134, 11, 110, 23, 162, 64. The head is initially at cylinder number 50, moving towards a larger number of cylinders. We will now use the SCAN algorithm to serve these I/O requests.
Direction - towards the larger number of cylinders
Output:
Arranging all the requests in ascending order, we get - { 11, 19, 23, 64, 80, 110, 134, 162 }.
The Head will start moving from 50 and will process the requests in the right direction in the sequence - 64, 80, 110, 134, 162, 199 (end of the disc).
Now the head will reverse its direction.
Now the head will process the requests in the left direction in the sequence - 23, 19, 11.
To implement the SCAN disk scheduling algorithm, the disk head moves in a particular direction, servicing requests along the way until it reaches the end of the disk. Then, it reverses direction and continues servicing requests in the opposite direction, which ensures efficient disk access and minimizes seek time.
public class SCANAlgorithm { public static void main(String[] args) { Scanner scanner = new Scanner(System.in); int N = 100005; int n = scanner.nextInt(); int head = scanner.nextInt(); int tail = scanner.nextInt(); ArrayList<Integer> q = new ArrayList<>();
for (int i = 0; i < n; i++) { int x = scanner.nextInt(); q.add(x); }
int direction = (head < tail) ? 1 : -1; scan(q, n, head, direction); }
static void scan(ArrayList<Integer> q, int n, int start, int direction) { int i; if (direction == 1) { for (i = start; i < n; i++) { if (q.contains(i)) { System.out.println("Serving " + i); q.remove(Integer.valueOf(i)); } } for (i = n - 1; i >= 0; i--) { if (q.contains(i)) { System.out.println("Serving " + i); q.remove(Integer.valueOf(i)); } } } else { for (i = start; i >= 0; i--) { if (q.contains(i)) { System.out.println("Serving " + i); q.remove(Integer.valueOf(i)); } } for (i = 0; i < n; i++) { if (q.contains(i)) { System.out.println("Serving " + i); q.remove(Integer.valueOf(i)); } } } } }
You can also try this code with Online Java Compiler
def scan(q, n, start, direction): if direction == 1: for i in range(start, n): if i in q: print("Serving", i) q.remove(i) for i in range(n - 1, -1, -1): if i in q: print("Serving", i) q.remove(i) else: for i in range(start, -1, -1): if i in q: print("Serving", i) q.remove(i) for i in range(0, n): if i in q: print("Serving", i) q.remove(i)
if __name__ == "__main__": n, head, tail = map(int, input().split()) q = [] for _ in range(n): q.append(int(input()))
direction = 1 if head < tail else -1 scan(q, n, head, direction)
You can also try this code with Online Python Compiler
SCAN (Elevator Algorithm) moves the disk arm in one direction, servicing requests sequentially, then reverses direction, improving seek time efficiency.
What is SCAN operation in DBMS?
In DBMS, a SCAN operation sequentially reads all records in a table or index, often used in full-table scans when no index is available.
What is the disk scheduling algorithm?
A disk scheduling algorithm manages read/write requests in an optimized order to minimize seek time. Examples include FCFS, SSTF, SCAN, and C-SCAN.
Conclusion
In this article, we have discussed SCAN (Elevator) Disk Scheduling Algorithms. These algorithms offer efficient data retrieval by mimicking elevator mechanisms. By prioritizing accessibility and optimizing disk access, SCAN algorithms contribute significantly to system performance and resource utilization in modern computing environments.































 8+ registered
8+ registered 

