Do you think IIT Guwahati certified course can help you in your career?
Introduction
So far, we have studied various regularisation techniques, but we missed out on an important concept, i.e., the difference between the regularisation techniques. Hence, this article will explore the difference between L1 and L2 regularisation, i.e., L1 vs. L2 Regularisation.
L1 Regularisation is also known as LASSO regularisation, short for Least Absolute Shrinkage And Selection Operator. Ordinary Least Squares are modified to minimize the absolute sum of the coefficients (called L1 regularisation). Mathematically it can be represented as
In L2 Regularisation, also known as the Ridge Regularisation, the Ordinary Least Squares are modified to minimize the squared absolute sum of the coefficients. Mathematically it can be represented as
Let's first understand the mathematical difference between them.
In L1 Regularisation, the sum of absolute weight multiplied by lambda is added to the cost function. In L2 Regularisation, the sum of the total weight square multiplied with lambda is added to the cost function.
Another significant difference is that L1 Regularisation reduces overfitting and feature selection because the weights are reduced to zero. While L2 Regularisation only solves the problem of overfitting. It cannot make feature selection because the consequences are reduced to near zero and not exactly zero like L1 Regularisation.
L2 regularisation has a solution in closed form as it is a square of weights. On the other hand, L1 regularisation doesn't have a closed-form solution since it includes an absolute value and is a non-differentiable function. Because of this, L1 regularization is comparatively more expensive in computation. However, at a higher level of computational costs, L2 regularization is likely to be more accurate in all circumstances.
L1 regularization gives output in discrete binary weights from 0 to 1 for the model's features and decreases the number of components in a vast dimensional dataset.
L2 regularization reduces the error terms in all the weight, leading to more accurate model outputs.
L1 vs. L2 Regularisation table
The following table represents the differences between the L1 and L2 regularisation in a more concise way:
S.No.
L1 Regularisation
L2 Regularisation
1
Penalises the sum of the absolute value of weights
Penalises the sum of the square of weights
2
Sparse solution
Non-sparse solution
3
Gives multiple solutions
It provides only one solution
4
Responsible for feature selection
No feature selection
5
Robust to outliers
Not robust to outliers
6
Generates simple and interpretable models
Generates more accurate predictions when the output variable is the function of whole input variables.
7
Unable to learn complex data patterns.
Able to learn complex data patterns.
8
Computationally inefficient over non-sparse conditions.
Computationally efficient because of having analytical solutions.
What is the difference between the effects of L1 vs. L2 regularization? L1 regularization penalizes the sum of absolute values of the weights, whereas L2 regularization penalizes the sum of squares of the consequences.
Why would you use L1 and L2 regularization? L1 regularization gives output in discrete binary weights from 0 to 1 for the model's features and is used for reducing the number of components in a vast dimensional dataset. L2 regularization disperses the error terms in all the weights, leading to more accurate customized final models.
What is the importance of regularisation? Regularisation plays a vital role in machine learning. It is responsible for overcoming the problem of overfitting.
How do you choose between L1 and L2 regularisation? L1 and L2 regularisation have different but equally essential properties. L1 tends to shrink coefficients to zero, whereas L2 shrinks coefficients evenly. L1 is, therefore, valid for feature selection, as we can drop any variables associated with coefficients that go to zero.
Key Takeaways
To prevent overfitting, regularization is the most-approached mathematical technique. It achieves this by penalizing the complex Machine Learning models by adding regularization terms to the cost function of the model. In this article, we studied L1 vs. L2 Regularisation. To dive deeper into machine learning, check out our industry-level courses on coding ninjas.
Live masterclass
Top 5 GenAI Projects to Crack 25 LPA+ Roles in 2026
by Shantanu Shubham
11 May, 2026
03:00 PM
Zero to Data Analyst: Amazon Analyst Roadmap for 30L+ CTC
by Abhishek Soni
10 May, 2026
06:30 AM
Google SDE Roadmap to land 30L+ CTC
by Saurav Prateek
10 May, 2026
08:30 AM
PowerBI + AI for Data Analytics: Secure 30L+ CTC at Netflix
by Ashwin Goyal
11 May, 2026
01:30 PM
Top 5 GenAI Projects to Crack 25 LPA+ Roles in 2026
by Shantanu Shubham
11 May, 2026
03:00 PM
Zero to Data Analyst: Amazon Analyst Roadmap for 30L+ CTC





























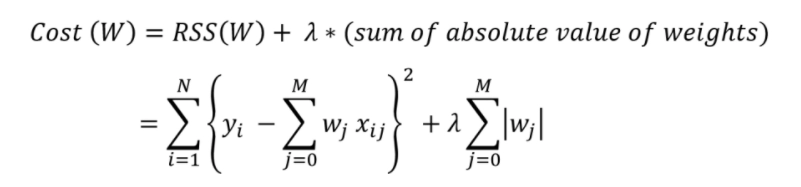


 16+ registered
16+ registered 

