Do you think IIT Guwahati certified course can help you in your career?
Introduction
There is one kind of computational problems which are beyond the capabilities of a conventional computer. These problems are classified by the fact that they require a vast number of computations that will take conventional computer days or even weeks to complete. Many of the required computations cannot be completed within a reasonable amount of time without sophisticated computers. To achieve the required high-performance level, it is necessary to utilize the fastest and most reliable hardware innovative procedures from vector and parallel processing.
To avoid the overhead of the processing loop, vector processing operates on all elements of the entire array in one operation, i.e in parallel. But vector processing is possible only if operations performed in parallel are independent of each other.
A vector is defined as an ordered set of a one-dimensional array of data items. A vector V of length n can be represented as a row vector by V = [V1 V2 V3 · · · Vn]. If the data items are listed in a column, it may be represented as a column vector
For a processor with multiple ALUs, it is possible to operate on multiple data elements in parallel using a single instruction. Such instructions are called single-instruction multiple-data (SIMD) instructions. They are also called vector instructions.
VectorAdd.S Vi, Vj, Vk
The above Vector instruction computes L sums using the elements in vector registers Vj and Vk, and places the resulting sums in vector register Vi. Similar instructions are used to perform other arithmetic operations.
VectorLoad.S Vi, X(Rj)
The above Vector instruction is to transfer multiple data elements between a vector register and the memory.
A computer capable of vector processing eliminates the overhead associated with the time it takes to fetch and execute the instructions in the program loop. It allows operations to be specified with a single vector instruction of the form
C(1: 100) = A(1: 100) + B(1: 100).
The vector instruction includes the initial address of the operands, the length of the vectors, and the operation to be performed, all in one composite instruction.
The instruction format of the vector processor is
Operation code
Base address source1
Base address source2
Base address destination
Vector length
This is a three-address instruction with three fields specifying the length of the data items in the vectors and the base address of the operands and an additional field. This assumes that the vector operands reside in memory. It is also possible to design the processor with a large number of registers and store all operands in registers prior to the addition operation. In that case, the base address and length in the vector instruction specify a group of CPU registers.
In a source program written in a high-level language, if the operations performed in each pass are independent of the other passes, loops that operate on arrays of integers or floating-point numbers are vectorizable.
A vectorizing compiler can recognize such loops and generate vector instruction if they are not too complex.
Using vector instructions reduces the number of instructions that need to be executed and enables the operations to be performed in parallel on multiple ALUs.
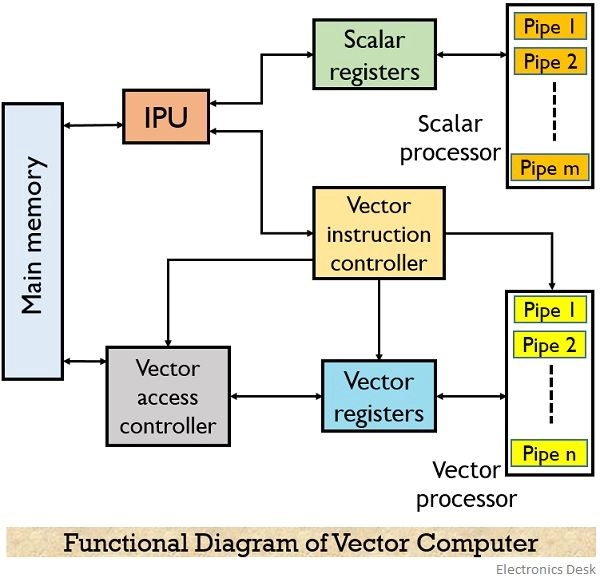
Based on where from where operands are retrieved, vector processors can be classified into two classes - Memory to memory and Register to register.
Memory to memory Vector processor In this type of vector processor, the operands for instruction, intermediate result, and final result all are retrieved from the main memory. Such processors are Cyber-205, TI-ASC.
Register to register Vector processor In this type of vector processor, the operands for instruction, intermediate result, and final result all are retrieved from scalar or vector registers. Such processors are Cray-1, Fujitsu VP-200.
For improving the performance of vector processing, we need to reduce the overhead on the vector processor. In the following way we can ensure better efficiency of vector processor:
Efficient algorithm We need to choose an efficient algorithm that would work faster for vector pipelined processing.
Integrating scalar instruction We can reduce the overhead of reconfiguring pipelines by integrating scalar instruction of the same type.
Improving vector instruction Vector instruction can be improved by reducing memory access and utilizing resources.
What is Vector processor? The processor that can work on an entire vector in a single instruction is called vector processor.
What is SIMD? SIMD stands for single-instruction multiple-data. Instruction that can operate on multiple data elements in parallel is called SIMD instruction.
Key Takeaways
This article covered vector processing as well as the characteristic of vector instruction.
We highly recommend you to visit the Coding Ninjas Studio library to get a better hold of the computer fundamentals to crack your dream jobs.
Check out our blog on Register in Computer to find out more about computer architecture.
Side by side, you can also practice a wide variety of coding questions commonly asked in interviews in Coding Ninjas Studio. Along with coding questions, you can also find the interview experience of scholars working in renowned product-based companies here.





























 18+ registered
18+ registered 

